[논문리뷰] Toward Native Multimodal Modeling: A Roadmap
링크: 논문 PDF로 바로 열기
Please go back to the chat and continue your conversation. 저자: Siyu An, Junru Lu, Junnan Dong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Native Multimodal Modeling (NMM): 여러 모달리티(modality)가 코어 아키텍처에 내재적으로 통합되어 교차 모달 시너지를 발휘하는 패러다임을 의미합니다. 이는 모듈식 구성(modular assembly)에서 벗어나 통합된 교차 모달 인텔리전스를 목표로 합니다.
- Late-Fusion: 사전에 학습된 인코더(encoder)와 고정된 언어 백본(language backbone)을 얕은 프로젝터(projector)를 통해 모듈식으로 조합하는 기존의 멀티모달 접근 방식입니다. 센서리 신호에 대한 근본적인 블라인드니스(blindness)를 가진 비-네이티브(non-native) 패러다임으로 분류됩니다.
- Mid-Fusion: NMM으로의 전환 첫 단계로, 개별 인코더의 특징(features)이 조인트 멀티모달 백본의 중간 계층에 주입되는 방식입니다. 모델은 교차 모달 상관관계에 대한 통찰력을 가지지만, 명시적인 모달리티-인지 경계(modality-aware boundaries)를 유지합니다.
- Early-Fusion: 네이티브 시너지의 최적 정점으로, 모든 모달리티가 통합된 연산자(unified operator)를 통해 단일 공유 임베딩 공간(shared embedding space)으로 매핑되는 패러다임입니다. 이 'Born-Native' 아키텍처는 모든 모달리티를 본질적으로 동등한 토큰으로 취급하여 깊은 시너지를 달성합니다.
- Multi-to-Text (M2T): 멀티모달 입력(텍스트, 이미지, 오디오, 비디오)을 받아 텍스트 출력만을 생성하는 비대칭적 이해(asymmetric comprehension) 방식의 모델 카테고리입니다. 교차 모달 정렬(cross-modal alignment) 및 인지 그라운딩(perceptual grounding)에 최적화되어 있습니다.
- Multi-to-Target (M2G): 멀티모달 입력에서 단일 타겟 비-텍스트 모달리티(예: 이미지, 오디오, 비디오)를 직접 합성하는 비대칭적 생성(asymmetric generation) 방식의 모델 카테고리입니다. 통합된 출력 경로를 통해 타겟 모달리티를 직접 디코딩하여 높은 의미론적 일관성(semantic coherence)을 보장합니다.
- Multi-to-Multi (M2M): 멀티모달 이해(understanding)와 생성(generation)이 단일 네트워크 내에서 대칭적으로 공존하는 완전한 대칭적 입출력 흐름(symmetric input-output flow)을 확립하는 가장 포괄적인 모델 카테고리입니다. 이는 분리된 인지기(perceptors)와 렌더러(renderers)의 개념이 사라진 통합된 세계 모델러(world modeler) 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Large Language Models (LLMs)이 텍스트 전용 인터페이스에 근본적으로 제한되어 실제 세계의 풍부한 센서리 신호(sensory signals)를 통한 그라운딩(grounding)이 부족하다는 문제의식에서 출발합니다. 기존 멀티모달 접근 방식인 Late-Fusion 패러다임은 사전 학습된 인코더(encoder)와 고정된 언어 백본을 모듈식으로 조합하여 사용했으나, 이러한 비-네이티브 구성은 원시 센서리 신호에 대한 근본적인 블라인드니스(blindness)를 초래하고 교차 모달 상호작용의 깊이를 제한하여 진정한 시너지를 달성하지 못했습니다.
저자들은 이러한 한계를 극복하고 범용 인공지능(Artificial General Intelligence)으로 나아가기 위해, 여러 모달리티가 코어 아키텍처에 내재적으로 통합되는 Native Multimodal Modeling (NMM)으로의 패러다임 전환이 필수적이라고 강조합니다. 그러나 현재 NMM의 설계 공간은 파편화되어 있고 충분히 정의되지 않아, 새로운 모델의 네이티브 정도를 평가하고 특정 다운스트림 작업에 최적의 아키텍처를 선택하기 어렵다는 문제가 있습니다. 따라서 본 연구는 모듈식 구성에서 네이티브 컨버전스(native convergence)로의 전환을 공식화하고 통합 깊이 및 입출력 이중성(input-output duality)에 따른 분류 체계를 제시하는 구조화된 로드맵을 제공하고자 합니다 [Figure 1, Figure 2].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 NMM의 설계 공간을 통합 깊이(integration depth)와 입출력 모달리티 흐름(input-output modality flow)의 두 가지 관점에서 체계적으로 분류하고 발전 방향을 제시합니다.
통합 깊이 측면에서 NMM은 Mid-Fusion과 Early-Fusion 두 가지 주요 레짐(regime)으로 나뉩니다.
- Mid-Fusion 모델은 서로 다른 인코더의 특징을 조인트 멀티모달 백본의 중간 계층에 주입하여 교차 모달 상관관계를 학습하지만, 모달리티-인지 경계(modality-aware boundaries)를 유지합니다. Qwen2.5-VL, InternVL-3.5와 같은 모델들이 이 범주에 속합니다. Mid-Fusion 모델은 progressive unfreezing, differential learning rates, 그리고 decoupled losses와 같은 훈련 전략을 활용하여, 인코더가 언어 목표에 적응하면서도 시스템 안정성을 유지합니다.
- Early-Fusion 모델은 모든 모달리티를 단일 통합 연산자(unified operator)를 통해 공유 임베딩 공간으로 매핑하며, 이를 'Born-Native' 아키텍처로 정의합니다. Chameleon, Emu3.5, AnyGPT 등이 대표적이며, 모든 모달리티를 동등한 토큰으로 취급하여 깊은 시너지를 달성합니다. Early-Fusion 모델은 joint-from-start, unified NTP (Next-Token Prediction), 그리고 z-loss 및 QK-Norm과 같은 필수적인 안정화 기법을 사용하며, 단일 학습률을 통해 통합된 손실 함수를 최적화합니다.
입출력 모달리티 흐름 관점에서 NMM은 세 가지 기능적 카테고리로 분류됩니다 [Figure 3].
- Multi-to-Text (M2T): 멀티모달 입력을 받아 텍스트로만 응답을 생성하는 비대칭적 이해 모델입니다. 예를 들어, Nemotron3-Nano-Omni, MiMo-V2.5는 복잡한 이미지, 오디오, 비디오 입력에서 텍스트 기반 추론을 수행합니다. 특히, 오디오 이해에서는 Gemma-4-E4B가 긴 프레임 지속 시간(long frame duration)으로 오디오 입력을 압축하여 실시간 상호작용에서 매우 낮은 Latency를 달성합니다.
- Multi-to-Target (M2G): 멀티모달 입력에서 이미지, 오디오, 비디오와 같은 특정 비-텍스트 모달리티 출력을 직접 합성합니다. Ming-Flash-Omni-2.0는 Transformer와 Diffusion 모델을 공유 잠재 공간에서 결합하여 텍스트 및 이미지 구조를 조기에 정렬함으로써 뛰어난 pixel-level fidelity를 보여줍니다. 오디오 생성 분야에서는 Qwen3-Omni가 Multi-Token Prediction (MTP) 전략을 사용하여 효율성과 품질의 균형을 맞춥니다. 비디오 생성에서는 HunyuanVideo-1.5가 광범위한 실제 비디오 데이터 학습을 통해 강력한 temporal coherence 및 long-term physical reasoning 능력을 자연스럽게 습득했습니다.
- Multi-to-Multi (M2M): 이해와 생성이 단일 네트워크 내에서 대칭적으로 공존하는 궁극적인 네이티브 컨버전스 모델입니다. Emu3.5는 Discrete Diffusion Adaptation을 통해 단일 이미지 추론 속도를 약 20배 가속화하면서도 성능 저하 없이 구현했습니다. Mamoda2.5는 MetaQueries를 통해 AR 백본이 응축된 논리적 계획을 생성하고 이를 DiT-MoE 모듈에 연결하여 고속, 세밀한 pixel rendering을 수행함으로써 AR과 Diffusion을 융합합니다.
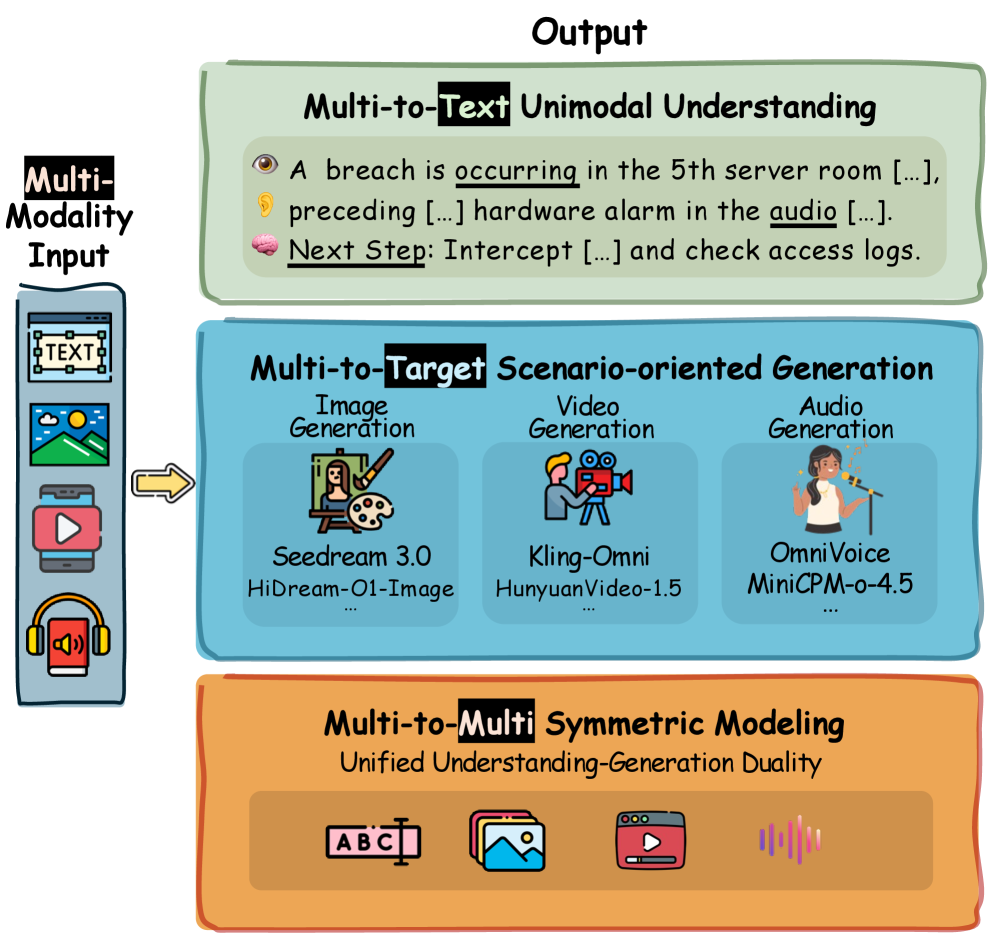
Figure 3 — NMM 아키텍처 유형 예시
이러한 방법론적 발전은 데이터 큐레이션, 훈련 전략, 추론 및 배포, 평가 방식 전반에 걸쳐 NMM의 실현 가능성을 높이고 있습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 멀티모달 모델링 패러다임이 Late-Fusion의 모듈식 조립에서 벗어나, 명시적인 모달리티 경계를 가진 Mid-Fusion 백본을 거쳐, 궁극적으로 이해(understanding)와 생성(generation)이 단일 Transformer 공간에서 공존하는 Early-Fusion 레짐으로 진화하고 있음을 명확히 보여줍니다. 이러한 네이티브 멀티모달 모델링(NMM)은 기존 LLMs의 텍스트 전용 한계를 극복하고 실제 세계의 풍부한 센서리 신호를 통합하여 보다 포괄적인 세계 모델(world models)로 나아가는 데 중요한 진전을 이룹니다.
이 연구는 NMM의 아키텍처적 컨버전스(architectural convergence), 대규모 데이터 큐레이션, 풀 스택 트레이닝 레시피, 효율적인 추론 및 배포, 그리고 포괄적인 평가를 위한 체계적인 로드맵을 제공함으로써 해당 분야에 큰 시사점을 줍니다. 특히, M2T, M2G, M2M과 같은 기능적 분류는 모델의 입출력 특성에 따라 최적화된 설계 방향을 제시하며, Early-Fusion 모델의 z-loss 및 QK-Norm과 같은 안정화 기법과 Modality-mixture scheduling의 중요성은 새로운 훈련 패러다임을 확립합니다. 궁극적으로 이 로드맵은 미래에 Born-Native world models이 실현될 수 있는 토대를 마련하며, 이는 통합되고, 대칭적이며, 스트리밍 및 체화된(embodied) 멀티모달 인텔리전스를 향한 여정의 시작점을 제공합니다.
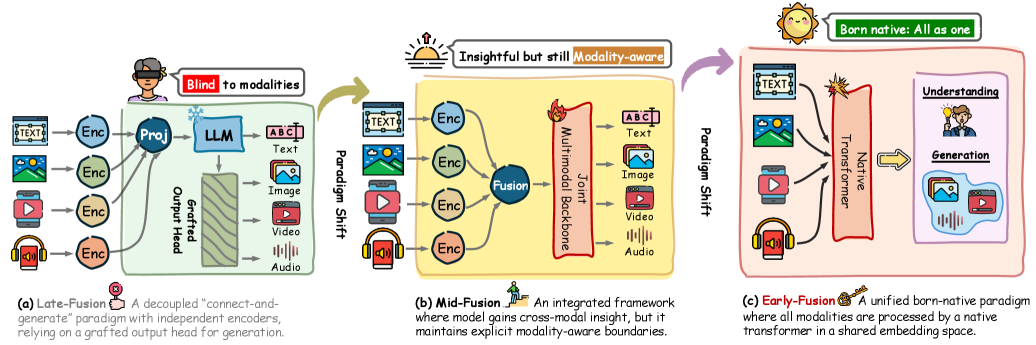
Figure 1 — 멀티모달 모델링 패러다임 진화
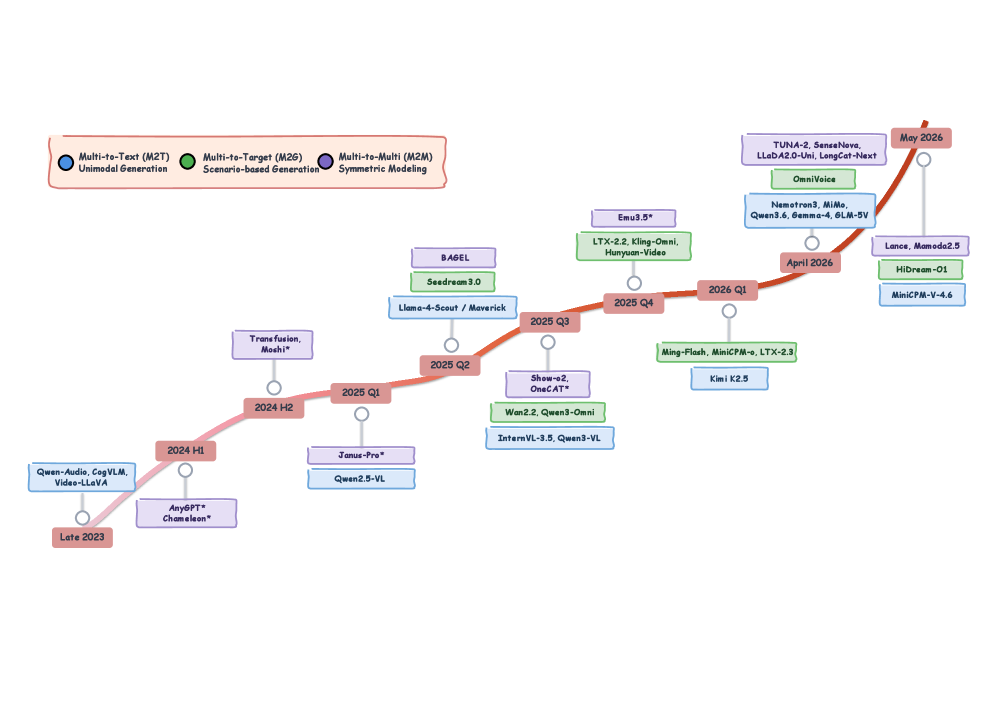
Figure 2 — NMM 모델 진화 및 분류
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Phi-4-reasoning-vision-15B Technical Report
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
- [논문리뷰] OVO-S-Bench: A Hierarchical Benchmark for Streaming Spatial Intelligence in Multimodal LLMs
- [논문리뷰] HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
- [논문리뷰] OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding
Review 의 다른글
- 이전글 [논문리뷰] ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention
- 현재글 : [논문리뷰] Toward Native Multimodal Modeling: A Roadmap
- 다음글 [논문리뷰] TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
댓글