[논문리뷰] WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
링크: 논문 PDF로 바로 열기
Some information may be missing due to the limitations of the tool.
The paper is about "WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation". I need to extract the following information:
- Authors: Kaining Ying, Hengrui Hu, Siyu Ren, Jiamu Li, Fengjiao Chen, Ziwen Wang, Xuezhi Cao, Xunliang Cai, Henghui Ding
- Keywords: Will derive them from the abstract and introduction. Likely
Interactive World Models,Video Generation,Benchmark,Multi-turn Interaction,Evaluation Metrics,Controllability,Physics Compliance. - Key Terms & Definitions:
Interactive World Models,Multi-turn Benchmark,World Setting,Interaction Taxonomy,Automatic Sub-metrics. - Motivation & Problem Statement: Current evaluation for interactive world models is fragmented, lacks a unified standard, and existing benchmarks are limited in scope (e.g., focus on perceptual quality without interactive control, specific domains like autonomous driving, or lack comprehensive interaction types/perspectives). This makes fair comparison and failure diagnosis difficult across crucial aspects like visual quality, controllability, memory, and physics.
- Method & Key Results:
- WBench Dataset: 289 test cases, 1,058 interaction turns. Each case has a
World Setting(scene, style, perspective, subject) and aMulti-turn Interaction sequence(navigation, subject action, event editing, perspective switching). Navigation supports text, 6-DoF pose, and discrete-action control. - WBench Evaluation Suite: 22 automatic sub-metrics across five dimensions:
Video Quality,Setting Adherence,Interaction Adherence,Consistency, andPhysics Compliance. Metrics are validated against human judgments (Spearman ρ ≥ 0.94). - Experiments: Evaluated 20 SOTA models (text-driven, camera-controlled, action-conditioned).
- Key findings:
- No single model performs strongly across all five dimensions.
- Navigation is largely independent of other dimensions (e.g., video quality, consistency, physics compliance).
- Camera control doesn't guarantee
Perspective Consistency. - Physical correctness correlates with rendering quality more than control.
- Benchmark difficulty is structured by
perspective,scene type, andsubject category. - Four interaction types degrade unevenly over turns, with navigation being the most fragile.
- Key findings:
- WBench Dataset: 289 test cases, 1,058 interaction turns. Each case has a
- Conclusion & Impact: WBench provides a comprehensive evaluation framework, revealing limitations of current interactive world models (lack of unification between high-fidelity rendering, reliable controllability, consistency, and physics). It guides future research.
- Figures: I need to pick up to 3 figures.
- Figure 1: Overview of WBench (Top: multi-turn case, Bottom: benchmark design). This seems very important.
- Figure 2: Dataset composition across eight axes. This is also important for understanding the dataset.
- Figure 3: Cross-dimension correlation and per-setting deviation analysis. Shows key experimental findings.
- Figure 4: Per-turn performance degradation. Illustrates a key finding about degradation.
- Figure 5: Human-auto alignment across ten evaluation aspects. Shows the validation.
- Table 1: Comparison with representative benchmarks. Very important for motivation.
- Table 2: Main results on WBench navigation split. Quantitative results.
I'll choose:
- Figure 1: Overview of WBench. (Architecture/Framework diagram)
- Table 2: Main results on WBench. (Key quantitative results) - Correction: The prompt states "Table is an image in HTML, not HTML table". I need to check if Table 2 is an image or an actual HTML table. Looking at the browsed content,
Table 2is indeed an HTML table rendered as text, not an image with asrc. So I cannot pick Table 2 for the JSON output. I need to pick another Figure. Let me re-evaluate the figures for JSON:- Figure 1: Overview of WBench.
src="2605.25874v1/x1.png". This is an image. - Figure 2: Dataset composition.
src="2605.25874v1/x2.png". This is an image. - Figure 3: Cross-dimension correlation.
src="2605.25874v1/x3.png". This is an image. - Figure 4: Per-turn performance degradation.
src="2605.25874v1/x4.png". This is an image.
- Figure 1: Overview of WBench.
I will pick Figure 1, Figure 2, and Figure 3. They cover the overview, dataset, and key analysis results.
Now, let's assemble the response following the markdown and JSON structure. I will carefully adhere to the "Technical Terminology in English" and "Natural Korean Phrasing" constraints, and the citation rules. I will make sure to bold technical terms and refer to figures explicitly.저자: Kaining Ying, Hengrui Hu, Siyu Ren, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Interactive World Models (IWMs): 사용자의 Action 신호에 반응하여 다음 Frame을 직접 합성함으로써 Closed-loop Simulation을 가능하게 하는 Video Generator 기반 모델이다.
- Multi-turn Benchmark: 단일 Turn의 상호작용을 넘어, 연속적인 여러 Turn의 상호작용 Sequence를 통해 Temporal Consistency 및 Long-horizon Coherence를 평가하는 벤치마크이다.
- World Setting: 초기 World State(o0)를 정의하는 네 가지 속성(Scene, Style, Perspective, Subject)으로 구성된다.
- Interaction Taxonomy: WBench에서 정의하는 네 가지 상호작용 Type으로, Navigation, Subject Action, Event Editing, Perspective Switching을 포함한다.
- Automatic Sub-metrics: Specialist Vision Models와 Large Multimodal Models(LMMs)를 결합하여 개발된 22가지의 세분화된 평가 지표로, Human Judgment와 비교하여 검증되었다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Interactive World Models의 발전에도 불구하고, 기존의 평가 방식은 단편적이며 체계적인 평가를 위한 통합된 표준이 부재하다. 많은 연구들이 선택된 Demos나 Task-specific Protocols에 의존하여, Visual Quality, Controllability, Memory, Physics 등 핵심 역량에 대한 공정한 비교와 Failure Diagnosis가 어렵다. 기존 벤치마크인 VBench는 Perceptual Quality에 집중하고 Interactive Control이 부족하며, WorldMark 및 MIND는 Navigation과 Memory를 다루지만 Semantic Interactions이 부족하다. Omni-WorldBench는 Causal Interaction을 추가했으나 First-person View만 지원하며, WorldLens는 자율주행에 국한되는 등, Open-domain Scene, 다양한 Perspective, 그리고 포괄적인 Interaction Type을 아우르는 Unified Protocol이 없는 상황이다. 이러한 Gap을 해결하기 위해, 본 연구는 Interactive World Model의 체계적인 평가를 위한 포괄적인 Multi-turn Benchmark인 WBench를 제안한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Interactive World Models의 포괄적인 평가를 위해 WBench를 제안한다. WBench는 289개의 Test Case와 1,058개의 Interaction Turns로 구성된 Dataset을 포함하며, 각 Case는 Scene, Style, Perspective, Subject를 포함하는 World Setting과 Navigation, Subject Action, Event Editing, Perspective Switching의 네 가지 Interaction Type으로 구성된 Multi-turn Interaction Sequence를 명시한다 [Figure 1, Figure 2]. 특히, Navigation은 Text, 6-DoF Pose, Discrete-action Control을 Unified하여 다양한 Native Input Interface를 가진 모델들의 평가를 가능하게 한다 [Figure 1].
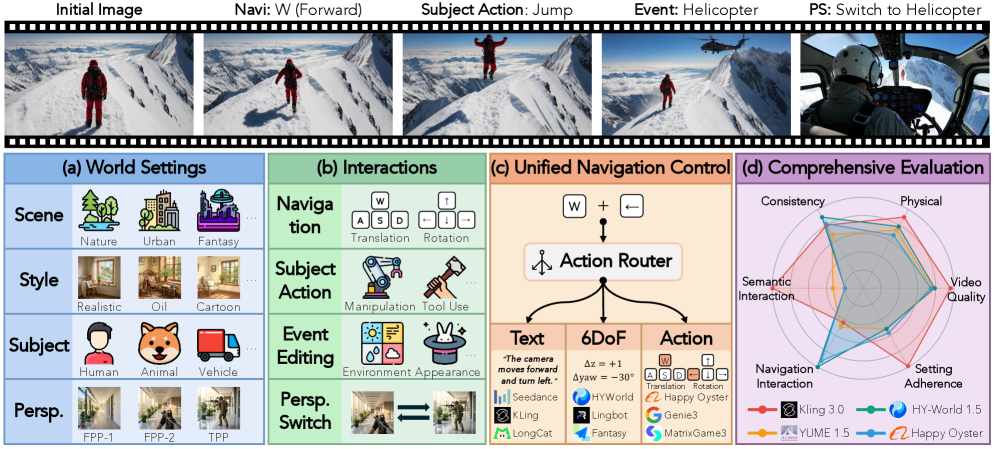
Figure 1 — WBench 개요 및 벤치마크 설계
평가는 Video Quality, Setting Adherence, Interaction Adherence, Consistency, Physics Compliance의 다섯 가지 Dimension에 걸쳐 22개의 Automatic Sub-metrics를 사용한다 [Figure 1]. 이 Metrics들은 Specialist Vision Models와 LMMs를 결합하여 개발되었으며, 모두 Human Judgment에 대해 Spearman ρ ≥ 0.94의 높은 Correlation으로 검증되었다 [Figure 5].
20개의 State-of-the-art 모델들을 대상으로 한 실험 결과, 다음의 핵심 insights가 도출되었다:
- No single model dominates all dimensions: 어떤 단일 모델도 다섯 가지 평가 Dimension 모두에서 강력한 성능을 보이지 못했다.
- Navigation is largely independent: Navigation 성능은 Video Quality (r=-0.12), Consistency (r=-0.05), Physical Compliance (r=-0.15)와 거의 상관관계가 없었다 [Figure 3]. 이는 Rendering, Memory, Physics 성능이 Controllable Movement로 직접 이어지지 않음을 시사한다.
- Physical correctness correlates with rendering quality: 물리적 정확성은 Rendering Quality (r=0.84) 및 Consistency (r=0.72)와 강한 상관관계를 보였지만, Navigation (r=-0.15)과는 무관했다 [Figure 3]. 이는 Physical Plausibility가 풍부한 Generative Priors에서 비롯됨을 나타낸다.
- Per-turn performance degradation: Navigation은 Turn이 진행됨에 따라 가장 빠르게 성능이 저하되었으며 (−33 points from turn 1 to turn 4+), 이는 Spatial Reference Frame을 유지하는 데 필요한 Compound Error 때문으로 분석된다 [Figure 4]. Dedicated World Models(예: HY-World 1.5)가 Text-based Prompting 모델(예: Kling 3.0)보다 더 견고한 경향을 보였다 [Figure 4].
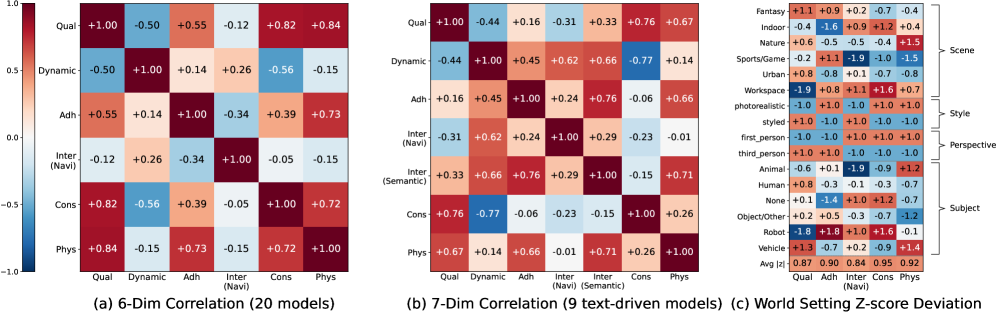
Figure 3 — 차원 간 상관관계 및 설정별 편차
4. Conclusion & Impact (결론 및 시사점)
본 연구는 World Settings과 Multi-turn Interactions를 통해 Interactive World Models를 다섯 가지 상호 보완적인 Dimension으로 평가하는 WBench 벤치마크를 성공적으로 제시하였다. 20개 모델에 대한 광범위한 실험을 통해, 현재 모델들이 High-fidelity Rendering과 Reliable Controllability, Consistency, Physics를 통합하는 데 여전히 한계가 있음을 밝혔다. 특히 Navigation이 다른 Capabilities와 독립적이며, Camera Control이 반드시 Subject Control이나 Perspective Consistency를 보장하지 않고, Physical Correctness가 Control Ability보다는 Rendering Quality와 더 밀접한 관련이 있음을 발견했다. 이러한 Diagnostic Insights는 향후 World Model 연구 및 개발에 중요한 지침을 제공하며, Simulation, Robotics, Gaming, Education 분야에서 보다 신뢰할 수 있는 World Model을 구축하는 데 기여할 것으로 기대된다.
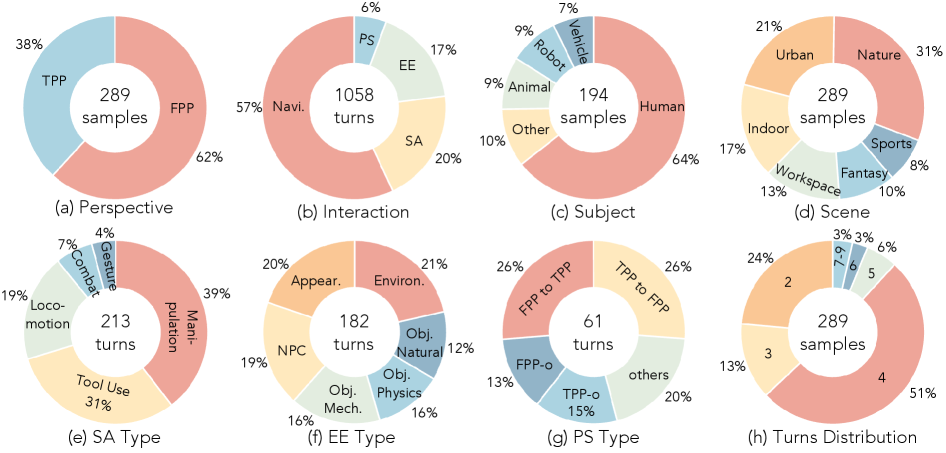
Figure 2 — WBench 데이터셋 구성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
- [논문리뷰] From Pixels to States: Rethinking Interactive World Models as Game Engines
- [논문리뷰] A Benchmark for Interactive World Models with a Unified Action Generation Framework
- [논문리뷰] WorldMark: A Unified Benchmark Suite for Interactive Video World Models
- [논문리뷰] DLEBench: Evaluating Small-scale Object Editing Ability for Instruction-based Image Editing Model
Review 의 다른글
- 이전글 [논문리뷰] TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
- 현재글 : [논문리뷰] WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
- 다음글 [논문리뷰] Your Embedding Model is SMARTer Than You Think
댓글