[논문리뷰] Your Embedding Model is SMARTer Than You Think
링크: 논문 PDF로 바로 열기
저자: Jianrui Zhang, Hyun Jung Lee, Sukanta Ganguly, et al.
1. Key Terms & Definitions
- Single-Vector Retrieval: 풍부한 sequential token sequence를 하나의 global representation으로 압축하는 임베딩 모델로, 일반적으로
token의 최종 layer hidden state를 사용합니다. 이는 효율적이지만 fine-grained local evidence를 소실시킵니다. - Multi-Vector Retrieval: token-level 또는 patch-level representation을 유지하고 local interaction (예: MaxSim)을 통해 관련성을 계산하는 임베딩 모델입니다. Single-Vector 모델의 한계를 극복하지만 상당한 training overhead가 필요합니다.
- SMART (Single-to-Multi Adaptation for Retrieval Transformers): 표준 single-vector 모델의 잠재된 multi-vector 능력을 발현시키는 프레임워크입니다. Pooled embedding에 대한 contrastive loss의 gradient flow가 non-pooling hidden states를 local matching에 적합하도록 암묵적으로 정렬한다는 관찰에서 출발하여, inference-only 방식 또는 lightweight finetuning을 통해 성능을 향상시킵니다.
- Late Interaction (MaxSim): ColBERT에서 시작된 메커니즘으로, 각 query token을 가장 유사한 candidate token과 매칭하여 유사도를 계산합니다.
- Hybrid Scoring: SMART에서 사용되는 scoring 메커니즘으로, global
single-vector score와 non-pooling hidden states에서 얻은late-interaction score를 결합하여 사용합니다.
2. Motivation & Problem Statement
본 논문은 single-vector multimodal retriever가 rich하고 sequential한 token sequence를 단일 global representation으로 압축하면서 발생하는 근본적인 information bottleneck 문제를 해결하고자 합니다. 이러한 압축 방식은 효율적이지만, dense retrieval task에 critical한 fine-grained local evidence를 종종 소실시키는 한계를 가집니다. 기존 multi-vector 접근 방식들(예: ColBERT, Colpali, jina-embeddings-v4)은 이러한 문제를 해결하기 위해 도입되었지만, 일반적으로 전체 task-specific finetuning 또는 learnable token의 도입을 필요로 하여 상당한 computational 및 memory cost를 발생시킵니다. 또한, 이들 방법은 single-vector model이 효과적으로 사용하는 global pooled readout의 필요성을 간과하는 경우가 많습니다. Figure 1은 표준 single-vector embedding model이 local information을 손실하고 hidden states를 제대로 활용하지 못하는 문제를 시각적으로 보여줍니다 [Figure 1, cite: 1].
3. Method & Key Results
저자들은 single-vector retriever의 latent multi-vector capabilities를 발현시키는 SMART (Single-to-Multi Adaptation for Retrieval Transformers) 프레임워크를 제안합니다. SMART는 contrastive loss의 gradient가 pooled token에만 적용될지라도 transformer의 attention 및 residual pathway를 통해 non-pooling hidden states의 retrieval geometry를 암묵적으로 정렬한다는 핵심 관찰에서 시작합니다. 이 indirect supervision은 hidden states가 cosine-based token-level retrieval을 지원하는 방식으로 organize되도록 장려합니다.
SMART는 세 가지 주요 형태로 적용될 수 있습니다:
- Inference-Only (Plug-and-Play): 기존
single-vector backbone을 유지하고,final-layer non-pooling hidden states에late-interaction MaxSim메커니즘을 적용합니다. 이token-level score는 원래의single-vector score와simple addition방식의hybrid scoring으로 결합되어, 추가적인 training 없이localized details를 효과적으로 recovery합니다. - Lightweight Adapter Post-Training:
embedding model을freeze한 상태에서final-layer hidden states위에token-wise linear adapter를 훈련시킵니다. 이를 통해non-pooling token hidden states를late interaction에 명시적으로 최적화하여inference-only방식보다 더 큰 성능 향상을 달성합니다. - Efficient Conversion via LoRA Finetuning:
single-vector embedder를hybrid scoring objective를 사용하여LoRA기반으로finetune하여multi-vector retriever로 변환합니다.
핵심 결과:
- Inference-Only Plug-and-Play 효과:
SMART는MMEB-V2벤치마크에서VLM2Vec-V2.0의average performance를 +2.54% 향상시키고,SoTA모델인Qwen3-VL-Embedding-8B의average metric을 78.83%에서 79.34%로 끌어올리는 등 다양한modality에 걸쳐 일관된 성능 향상을 보였습니다. 특히, 이 모든 개선은 추가 training 없이 inference-only로 달성되었습니다 [Table 1, cite: 1]. - Local Evidence 활용:
Controlled local-evidence toy benchmark에서single-vector score의pairwise accuracy는 31.9%에 불과했으나,late-interaction score를 단독으로 적용했을 때 56.8%로 향상되어non-pooling hidden states에local binding evidence가 보존되어 있음을 입증했습니다 [Figure 2, cite: 1]. 이는single-vector bottleneck이local evidence를 가릴 수 있음을 시사합니다. - Lightweight Adapter Post-Training 성능:
Qwen3-VL-Embedding-2B에lightweight adapter를 훈련시키는 데 단 1시간 50분이 소요되었으며, 이 모델은MMEB-V2의Visdocsubset에서SoTA multi-vector embedding model인jina-embeddings-v4보다0.34-point높은average performance를 달성했습니다 [Table 2, cite: 1]. - 효율적인 모델 변환:
LamRA-Single모델을SMARTfinetuning을 통해LamRA-Single-Convert로 변환하는 데 추가로 3시간이 소요되었으며, 이 모델은LamRA-Multi(multi-vector 모델을 처음부터 training한 경우)보다training time을 약 20% 절약하면서도Visdocaverage performance에서LamRA-Multi의 78.31%에 근접한 77.68%를 기록했습니다 [Table 3, cite: 1].Figure 3은SMART가local evidence를 활용하여single-vector retriever가 실패한 경우에도 올바른 후보를 검색하는 정성적 시각화 예시를 보여줍니다 [Figure 3, cite: 1].
4. Conclusion & Impact
본 논문은 single-vector multimodal retrieval model의 information bottleneck을 극복하기 위해 SMART 프레임워크를 제안합니다. contrastive training이 global pooling token에 대한 supervision을 통해서 non-pooling hidden states를 retrieval에 적합하도록 암묵적으로 구조화한다는 점을 활용하여, late-interaction MaxSim operator와 hybrid scoring objective를 통해 localized representations를 효과적으로 recovery합니다. SMART는 inference-only 환경에서 zero-training-cost plug-and-play upgrade로서 다양한 modality에 걸쳐 retrieval accuracy를 일관되게 향상시키며, Qwen3-VL-Embedding 시리즈와 같은 SoTA architectures에서도 견고하게 scalability를 입증합니다. 나아가, lightweight post-training을 통해 single-vector embedding model을 SoTA multi-vector variant로 변환할 수 있음을 보여주며, 이는 training time과 computational cost를 크게 절감하는 동시에 strong performance를 달성합니다. 궁극적으로 SMART는 기존 multimodal architecture에서 fine-grained, localized evidence를 recovery하는 robust하고 computationally efficient한 pathways를 제공하여 universal dense retrieval system의 성능 상한을 높이는 데 기여합니다.
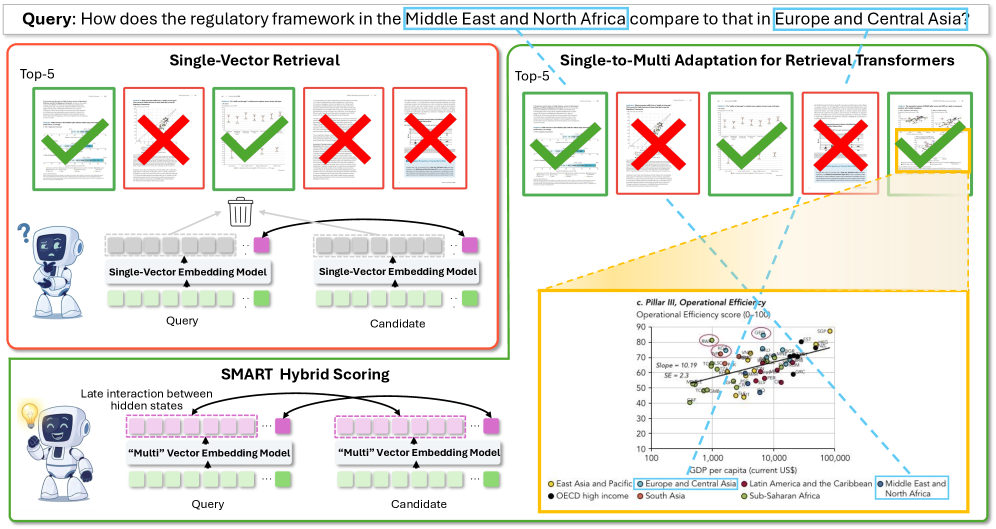
Figure 1 — 제안 방법론 SMART의 개요
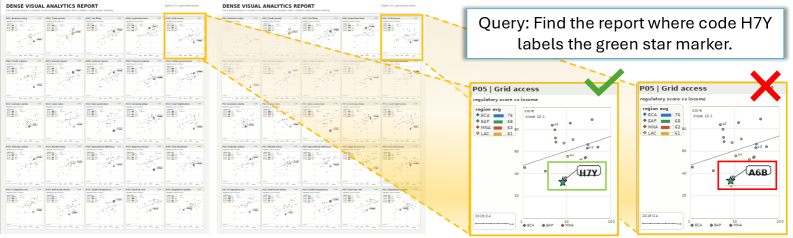
Figure 2 — 로컬 증거 장난감 벤치마크

Figure 3 — SMART 정성적 시각화 예시
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond the Grid: Layout-Informed Multi-Vector Retrieval with Parsed Visual Document Representations
- [논문리뷰] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
- [논문리뷰] Towards Mixed-Modal Retrieval for Universal Retrieval-Augmented Generation
- [논문리뷰] FG-CLIP 2: A Bilingual Fine-grained Vision-Language Alignment Model
- [논문리뷰] MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Review 의 다른글
- 이전글 [논문리뷰] WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
- 현재글 : [논문리뷰] Your Embedding Model is SMARTer Than You Think
- 다음글 [논문리뷰] D^2-Monitor: Dynamic Safety Monitoring for Diffusion LLMs via Hesitation-Aware Routing
댓글