[논문리뷰] LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
링크: 논문 PDF로 바로 열기
저자: Tengfei Liu, Yang Shi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LongAV-Compass: 분 단위(minute-scale) Audio-Visual Generation을 위한 체계적인 벤치마크이다. Text, Image, Video Conditioning Modality 전반에 걸친 통합 평가를 지원한다.
- T2AV (Text-to-Audio-Video): 구조화된 이벤트 스크립트(structured event scripts)로부터 Audio-Visual Content를 생성하는 Task이다.
- I2AV (Image-to-Audio-Video): 레퍼런스 이미지(reference image)와 이벤트 스크립트에 Condition되어, Subject Appearance와 Scene Attributes를 일관성 있게 유지하면서 장시간(long-form) Audio-Visual Sequence를 생성하는 Task이다.
- V2AV (Video-to-Audio-Video): 레퍼런스 비디오(reference video)를 Continuation Script에 따라 확장하여, Style Consistency, Subject Continuity, Temporal Coherence, Audio-Visual Alignment를 유지하는 Task이다.
- MLLM-assisted assessment: Multimodal Large Language Model (Gemini 3.1 Pro)을 활용하여 생성된 비디오의 다양한 측면을 평가하는 프로토콜이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Audio-Visual Generation 벤치마크가 Minute-Scale Content의 평가 요구사항을 충족하지 못하는 문제를 해결하고자 한다. 현재 Audio-Visual Generation 모델들이 단일 클립을 넘어 분 단위 Content를 생성할 수 있는 수준으로 발전하고 있음에도 불구하고, 기존 평가 프로토콜은 주로 5~10초 길이의 단일 클립에 초점을 맞추고 있다. 이는 모델이 긴 시간 동안 Subject Identity, Narrative Coherence, Scene Transitions, Audio Grounding을 일관성 있게 유지하는 능력을 평가하기에 충분한 증거를 제공하지 못한다. 또한, 기존 벤치마크는 Text-to-Audio-Video (T2AV), Image-to-Audio-Video (I2AV), Video-to-Audio-Video (V2AV)와 같은 다양한 Input Conditioning Modality에 대한 통합 평가를 제공하지 않아, 상이한 시스템 간의 비교를 어렵게 만든다. 이로 인해 Cross-Event Identity Drift, 약한 Continuation Quality, 불안정한 Scene Transition, Audio-Visual Synchronization 저하와 같은 Long-Range Degradation 현상을 진단하기 어렵다는 한계점이 존재한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Minute-Scale Audio-Visual Generation을 위한 통합 벤치마크인 LongAV-Compass를 제안한다. LongAV-Compass는 284개의 큐레이션된 Test Case를 포함하며, T2AV (128개), I2AV (115개), V2AV (41개) 예시로 구성되어 Application Scenario와 Generation Complexity (L1-L4)에 따라 분류된다 [Figure 2, Table 2]. 제안된 Framework는 Within-Segment Quality, Cross-Segment Consistency, Global Narrative Coherence, Semantic Alignment, Audio-Visual Synchronization을 포함하는 20가지 이상의 세분화된 Dimension을 평가한다 [Figure 1]. 평가 프로토콜은 MLLM-assisted assessment (Gemini 3.1 Pro)를 기반으로 하며, DINO-v2, Arc-Face, CLIP, ImageBind와 같은 Complementary Perceptual 및 Multimodal Metrics로 보완된다.
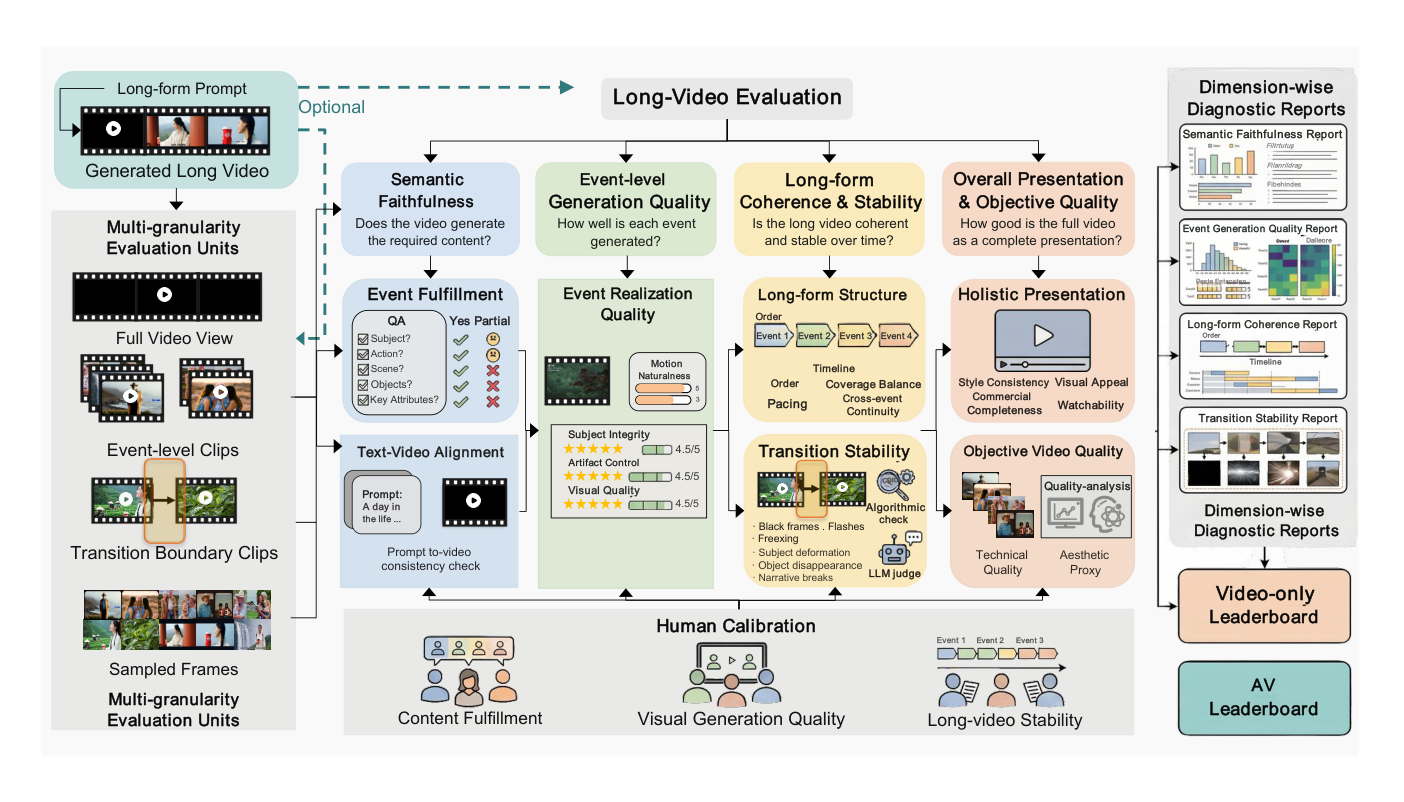
Figure 1 — 전체 벤치마크의 구조와 평가 프레임워크를 시각적으로 설명하는 핵심 다이어그램
실험 결과, 현재 Long-Form Audio-Visual Generation 시스템들은 단일 점수로Adequately하게 특성화될 수 없으며, Event Completion, Temporal Continuity, Visual Quality, Semantic Alignment, Audio-Visual Synchronization을 동시에 유지하는 능력이 요구됨을 보여주었다. Seedance 2.0은 T2AV, I2AV, V2AV 전반에 걸쳐 가장 일관성 있는 성능을 보였다. 특히, T2AV Task에서 Kling 3.0은 Event Fulfillment (VQA)에서 0.9274, Long-form Continuity (Cont.)에서 4.4139로 가장 높았으며, Seedance 2.0은 Visual Quality (VQ)에서 3.7116, Holistic Presentation (Hol.)에서 4.1128, Audio-Video Synchronization (AVS)에서 3.6038, Audio Quality (AudQ)에서 3.7875, Long-audio Coherence (AudL)에서 4.1845로 최상위 성능을 달성했다 [Table 3]. I2AV Task에서는 Seedance 2.0이 VQA 0.9204, VQ 3.7651, Cont. 4.9182, Hol. 3.8526, AVS 3.5669, AudQ 3.9113, AudL 4.2290로 대부분의 지표에서 선두를 차지했으며, Kling 3.0은 First-frame Anchoring (IV1)에서 0.9960로 뛰어난 성능을 보였다 [Table 4]. V2AV Task에서는 Seedance 2.0이 VQA 0.8753, VQ 3.8336, Cont. 4.7636, Hol. 4.1705, TVAlign 0.9727, AVS 3.7591, AudQ 4.4357, AudL 4.3129를 기록하며 모든 지표에서 압도적인 성능을 입증했다 [Table 5]. 또한, Human-Alignment Validation 결과, Content Fidelity, Visual Quality, Long-video Stability에 대해 인간 평가와 벤치마크 점수 간의 Pearson 상관관계가 0.867 이상으로 높은 신뢰성을 보여주었다 [Figure 10].
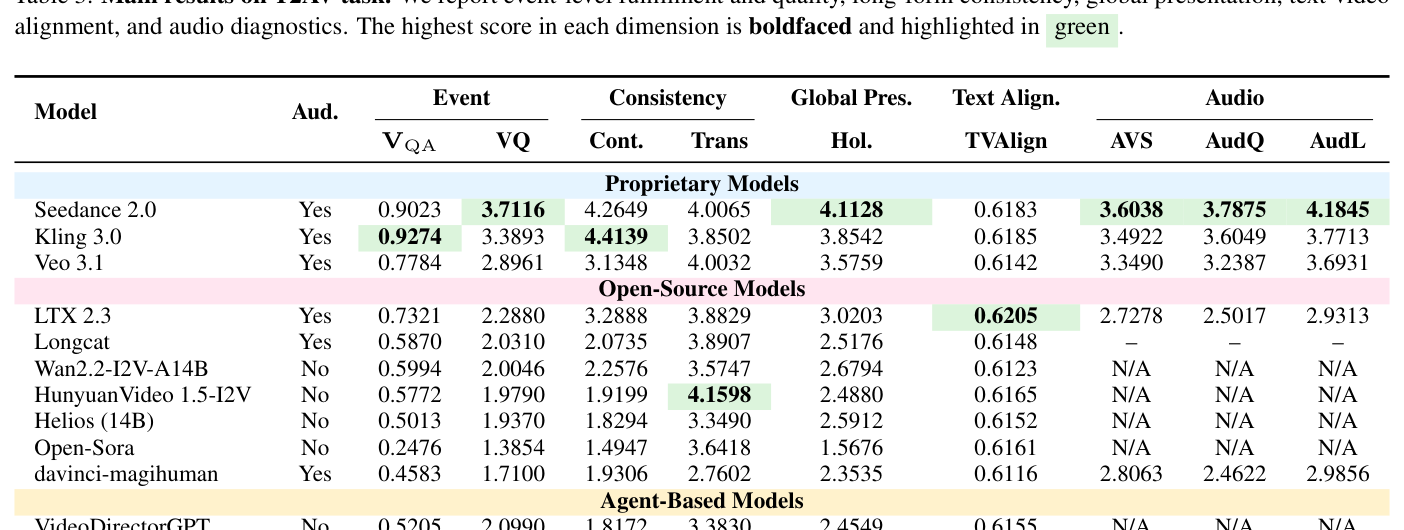
Table 3 — T2AV task에서 각 모델의 정량적 평가 지표별 성능을 비교하는 핵심 결과 테이블
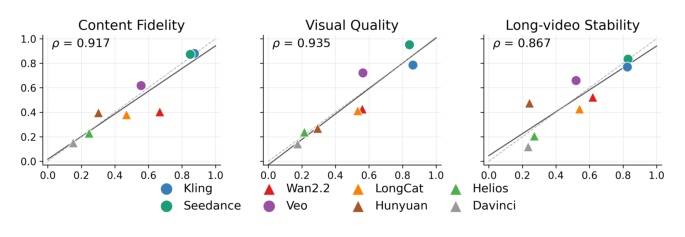
Figure 10 — 제안된 벤치마크의 자동 평가 지표와 인간 평가 간의 높은 상관관계를 보여주는 검증 그래프
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Minute-Scale Audio-Visual Generation의 통합 평가를 위한 최초의 벤치마크인 LongAV-Compass를 성공적으로 도입했다. 이 벤치마크는 기존 단일 클립 중심의 평가 한계를 넘어, Long-Form 시나리오에서 모델의 Event Completion, Temporal Continuity, Visual Quality, Semantic Alignment, Audio-Visual Synchronization 능력을 포괄적으로 진단한다. 연구 결과는 현재 모델들이 Identity Drift, Event Collapse, Transition Artifacts, Product Inconsistency, Audio-Visual Desynchronization과 같은 Long-Range Failure Mode에 취약함을 명확히 보여주며, 특히 Performance Ads 시나리오와 Event Count 증가 시 성능 저하가 두드러졌다. LongAV-Compass는 단순히 모델 간의 성능을 비교하는 것을 넘어, Temporal Scope, Conditioning Diversity, Cross-Modal Coupling이 복잡해짐에 따라 현재 Audio-Visual Generation 모델들이 어떤 지점에서 한계에 부딪히는지를 체계적으로 진단하는 중요한 Testbed 역할을 할 것이다. 이는 미래 Audio-Visual Generation 시스템 개발의 방향성을 제시하고, Minute-Scale Content 생성의 도전과제를 해결하는 데 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] Physics-IQ Verified
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] RISE-Video: Can Video Generators Decode Implicit World Rules?
- [논문리뷰] Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
- 현재글 : [논문리뷰] LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
- 다음글 [논문리뷰] MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
댓글