[논문리뷰] MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
링크: 논문 PDF로 바로 열기
The paper "MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research" by Dingbang Wu, Rui Hao, et al. introduces a new simulation platform and benchmark for mobile GUI agent research.
Here's the summary following the requested format:
저자: Dingbang Wu, Rui Hao, Haiyang Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Interaction Fidelity: 실제 모바일 앱의 백엔드나 픽셀 단위의 Android 내부를 재현하는 대신, GUI Agent가 관찰하고 상호작용하는 표면(visual screens, touch/typing responses, navigation, cross-app handoffs, task-relevant state transitions)을 충실히 재현하는 것을 목표로 하는 시뮬레이션의 정확도.
- Verifiable Outcome Signals: VLM(Vision-Language Model) 기반의 판단이 아닌, structured JSON state를 기반으로 한 deterministic한 상태 기반 검증을 통해 벤치마크 평가 및 RL (Reinforcement Learning) Reward가 실제 Task 상태에 기반하여 결정되는 신호.
- Structured JSON State: MobileGym에서 앱 데이터, OS 상태, 디바이스 Context가 명시적으로 표현되는 형식으로, 환경 상태를 읽고, 쓰고, Fork하고, 비교하는 데 사용된다.
- AnswerSheet Protocol: Query Task의 결과 검증을 위해 free-text matching의 불안정성을 피하고, agent가 GUI 상의 Form을 채워서 답변을 제출하도록 설계된 프로토콜이다. 제출된 typed state는 type-specific matcher에 의해 검증된다.
- Unexpected Side Effects (USE): Agent가 요청된 목표를 완료하는 동안 Task와 관련 없는 상태를 의도치 않게 변경하는 현상을 측정하는 Metric. MobileGym의 full-environment state comparison 기능을 통해 탐지된다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
모바일 GUI Agent 연구는 빠른 발전을 보였지만, 현재 평가 및 훈련 환경은 근본적인 Trade-off 문제에 직면해 있다. 기존 Emulator 기반 환경은 재현 가능한 평가를 제공하지만, System Utility나 간단한 Open-source 앱에 주로 적용되며, 확장 가능한 Online Training을 위해서는 다수의 무거운 Emulator Instance가 필요하다. 반면, Real-device Benchmark는 실제 앱을 다룰 수 있지만, Live Account, Backend State, App Version Drift, 실제 환경의 결과, 그리고 다수의 Device 및 Account 유지 비용으로 인해 Episode를 제어, 재현, 병렬화하기 어렵다.
이러한 환경들은 다음 두 가지 핵심 기능을 제공하지 못한다. 첫째, Verifiable Outcome Signals의 부재로, Benchmark 판단과 RL Reward가 unreliable한 VLM 판단에 의존하거나 실제 Task State에 기반하지 못하는 문제가 있다. 둘째, Scalable Online Training의 어려움이 있는데, Online RL이 GUI Agent의 핵심 Capability Driver가 되었음에도 불구하고, 대규모 병렬 Rollout을 지원하는 환경이 부족하여 Dynamic GUI Variation을 다루는 데 한계가 있다. 이러한 제약은 일상 앱의 내부 상태가 Unreadable, Unwritable, Unforkable하다는 본질적인 특성에서 비롯되며, 이는 재현 가능한 연구를 구조적으로 어렵게 만든다. 또한, 기존 Emulator는 Instance당 Gigabytes의 RAM을 요구하여 대규모 병렬 Rollout이 비실용적이다 [cite: 1, Figure 2].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 이러한 문제 해결을 위해 Browser-hosted, Lightweight, Fully Controllable한 Android-like Simulation Environment인 MobileGym을 제안한다. MobileGym은 실제 앱의 백엔드나 픽셀 수준의 Android 내부를 재현하는 대신, Agent가 관찰하고 상호작용하는 표면인 Interaction Fidelity를 목표로 한다 [cite: 1, Figure 3]. App Data, OS State, Device Context는 structured JSON으로 표현되며, 이를 통해 상태를 Readable, Writable, Forkable하게 만들어 Deterministic Outcome Checking, Snapshot-based Rollout Forking, Side-effect Detection, 그리고 Typed AnswerSheet Protocol을 통한 평가가 가능하다.
MobileGym의 주요 특징은 다음과 같다.
- Layered State Model: Read-only
World Data, Per-environmentRuntime State,OS Runtime State로 계층화된 State Model을 통해 Snapshot 크기를 작게 유지하면서 Agent에 의해 변경된 모든 정보를 보존한다. - Declarative Navigation Specification: 각 App의 UI Navigation을 Declarative Finite-State Machine으로 모델링하여 Runtime Navigation 및 Static Analysis (Task Trajectory Enumeration, Task Auto-generation)를 구동한다.
- State Programmability: Full Environment State를 structured JSON으로 직렬화 및 복원할 수 있어, 정확한 Reset 및 Snapshot으로부터 Forking을 가능하게 한다. 이는 GRPO와 같은 RL Method를 지원하며, Irreversible Operation 후에도 완벽한 복구를 보장한다. 또한, Initial State와 Terminal State 간의 Full-environment State Comparison을 통해 Unexpected Side Effects를 정확히 감지한다.
- MobileGym-Bench: 28개 앱에 걸쳐 416개의 Parameterized Task Template (256 Test + 160 Train)를 제공한다. Task는 Scope, Objective, Composition, Model-Calibrated Difficulty (L1-L4)의 4가지 Orthogonal Axis로 분류되며, AnswerSheet Protocol을 통해 Query Task의 평가 신뢰도를 높인다 [cite: 1, Figure 4].
실험 결과, MobileGym은 Emulator 기반 환경 대비 압도적인 효율성을 보여준다. 단일 Instance당 Memory 사용량은 약 400MB로, 기존 Emulator의 4.5GB~6GB 대비 약 1/10 수준이며, Cold Start Time은 약 3초로, Emulator의 78초 대비 1/20 이상 빠르다 [cite: 1, Table 1]. 이러한 효율성 덕분에 단일 서버에서 수백 개의 병렬 Instance를 호스팅하여 대규모 Online RL 연구를 실용적으로 수행할 수 있다.
Benchmark Evaluation에서는 9개의 Agent (Proprietary 및 Open-source)를 대상으로 MobileGym-Bench Test Set (256 Tasks)에 대해 평가를 진행했다. Gemini 3.1 Pro가 58.8% SR (Success Rate)로 가장 높은 성능을 보였고, Open-source Generalist Model인 Qwen3-VL-4B-Instruct는 9.4% SR을 기록했다 [cite: 1, Table 2]. 특히, Difficulty Stratification 결과, 모든 모델에서 L1에서 L4로 갈수록 SR이 단조 감소하며, L4에서는 Gemini 3.1 Pro만이 21.9%로 유의미한 성능을 유지했다. Unexpected Side Effects (USE) Metric은 모델 Capability와 단순 비례하지 않으며, 9개 모델에서 4.7%~14.5% 범위로 나타나, Full-environment State Comparison의 중요성을 입증했다.
Sim-to-Real Transfer Case Study에서는 Qwen3-VL-4B-Instruct를 MobileGym의 Train Set (160 Tasks)에서 GRPO로 10 Step Fine-tuning한 결과, Test Set (256 Tasks)에서 SR이 9.4%에서 22.2%로 +12.8pt 향상되었다 [cite: 1, Table 11]. Real-device에서 59개 Signal-bucket Subset으로 평가했을 때, Real-device Pass Rate는 32.2%에서 72.9%로 +40.7pt 증가했으며, 이는 Simulation-side Gain의 95.1%가 유지되는 것을 보여주었다 [cite: 1, Figure 5]. 또한, VLM Judge Error Analysis 결과, Real-device Trajectory에서 10.2%의 Misjudgment가 발견되어 Programmatic State Verification의 중요성을 강조했다 [cite: 1, Table 14].
4. Conclusion & Impact (결론 및 시사점)
MobileGym은 일상적인 모바일 사용 시나리오를 GUI Agent 연구를 위한 완전히 제어 가능한 Simulation Environment로 전환한다. 이 플랫폼은 Interaction Fidelity에 초점을 맞춤으로써, 실제 계정, Device Farm 또는 독점적인 백엔드에 의존하지 않고도 Deterministic Verification을 위한 상태 가독성, Reset 및 Configuration을 위한 상태 쓰기 가능성, 병렬 Online RL을 위한 상태 Forking 가능성, 그리고 고위험 작업에 대한 무위험성을 제공한다.
MobileGym-Bench는 416개의 Parameterized Task Template, Calibrated Difficulty Strata, AnswerSheet 기반 평가, 그리고 Unexpected Side Effects를 포함한 Diagnostic Metric을 통해 이 환경을 운영 가능하게 한다. 9개 Agent에 대한 실험 결과는 일상 모바일 Task에서 상당한 발전 여지가 있음을 보여주었으며, Sim-to-Real 연구는 Simulation-side Training Gain의 대부분이 Real-device Execution으로 Transfer될 수 있음을 입증했다. 이 통제 가능한 인프라는 Safety Alignment 연구, Robustness Testing, Training Data Generation 등 다양한 분야에 활용될 수 있으며, 재현 가능한 연구와 확장 가능한 Training을 위한 실용적인 대안을 제시한다.
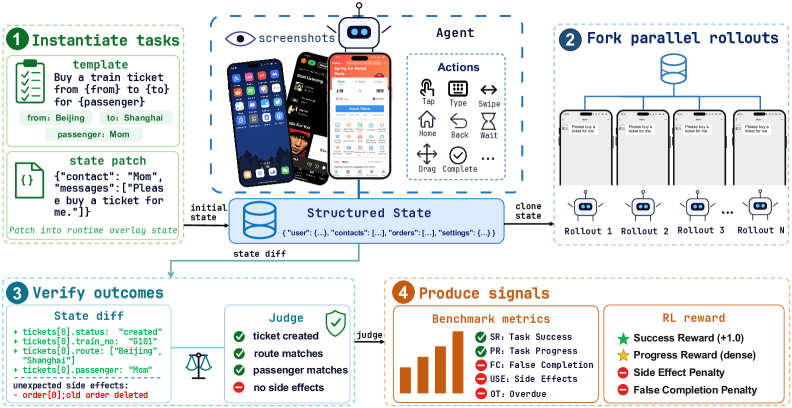
Figure 2 — MobileGym End-to-End 워크플로우
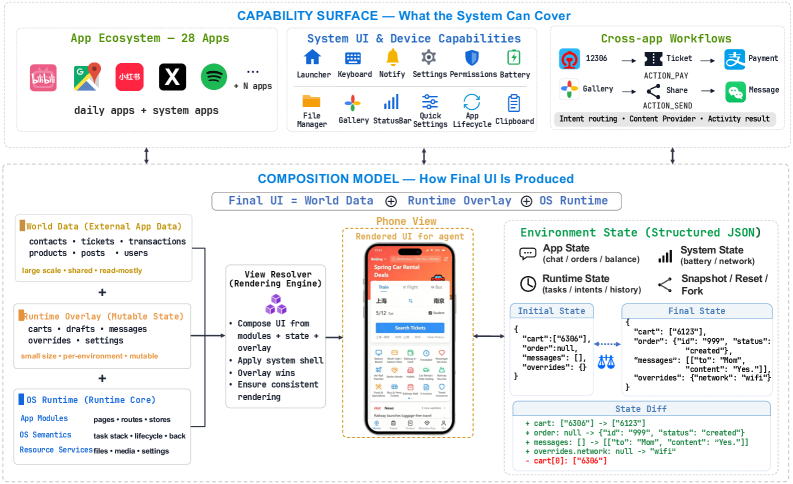
Figure 3 — MobileGym 시스템 역량 및 상태 모델
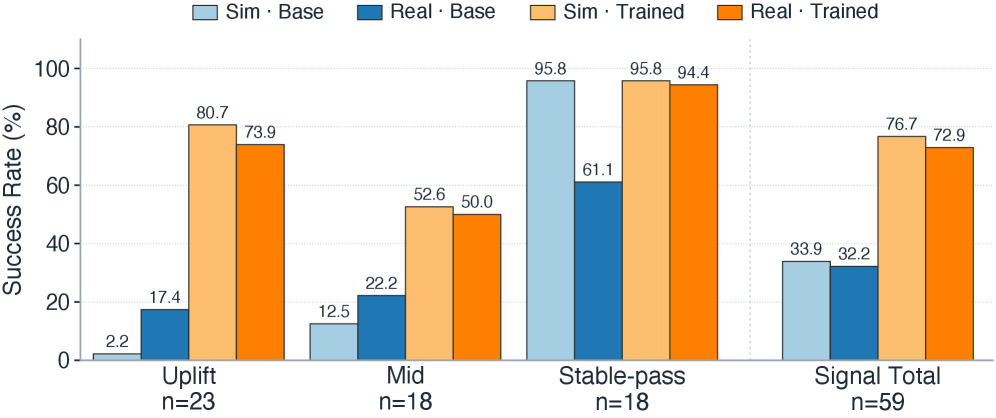
Figure 5 — Sim-to-Real 훈련 이득 전이 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
- [논문리뷰] EgoPush: Learning End-to-End Egocentric Multi-Object Rearrangement for Mobile Robots
- [논문리뷰] Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
- [논문리뷰] VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
- [논문리뷰] An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Review 의 다른글
- 이전글 [논문리뷰] LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
- 현재글 : [논문리뷰] MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
- 다음글 [논문리뷰] Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
댓글