[논문리뷰] Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
링크: 논문 PDF로 바로 열기
저자: Xinglin Wang, Hao Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Test-Time Scaling (TTS): 대규모 언어 모델(LLM)의 추론 시 컴퓨팅 자원을 추가로 할당하여 솔루션 공간을 탐색함으로써 추론 능력을 향상하는 패러다임입니다.
- Information Isolation Bottleneck: 기존 병렬 TTS 방법론에서 각 추론 Branch의 중간 발견(discovery)이 해당 Branch 내에만 국한되어 다른 Branch와 공유되지 않아 발생하는 비효율성입니다.
- Collaborative Parallel Thinking (CPT): Information Isolation Bottleneck을 해결하기 위해 제안된, 학습이 필요 없는(training-free) 추론 프레임워크로, 병렬 Branch 간 검색 시간 정보 공유를 가능하게 합니다.
- Shared Information Pool: CPT 내에서 진행 중인 Branch들로부터 추출된 간결한(compact) 중간 정보를 저장하고 중복을 제거하는(deduplicated) 쿼리-레벨(query-level) 정보 저장소입니다.
- Adaptive Broadcast Scheduling: CPT가 새로 발견된 정보의 유입률(marginal new-information gain)을 기준으로 정보 공유(broadcasting)를 시작하고 중단하는 시점을 동적으로 조절하는 스케줄링 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 병렬 Test-Time Scaling (TTS) 방법론은 Information Isolation Bottleneck이라는 중요한 한계점을 가지고 있습니다. 현재의 병렬 TTS 접근 방식은 일반적으로 추론 Branch들을 탐색 과정에서 서로 독립적으로 유지하여, 각 Branch에서 얻은 중간 발견(intermediate discoveries)이 다른 Branch와 공유되지 못하고 Branch-private하게 남아있습니다. 이로 인해 Branch들은 이미 다른 Branch에서 발견한 정보를 반복적으로 재발견하게 되고, 이는 상당한 Redundant Exploration을 유발하여 완전한 결정 정보(decision information)를 수집하고 정답에 도달하는 데 더 많은 검색 Step을 필요로 합니다. [Figure 1]은 이러한 독립적인 병렬 샘플링이 검색이 진행됨에 따라 중복 정보(duplicate information units)를 더 많이 생성하고 새로운 정보(newly discovered information units)의 수는 유지하면서도, CPT는 이러한 중복성을 완화함을 명확히 보여줍니다. [Table 1]에서 확인할 수 있듯이, Branch 간에 분산된 정보를 오프라인으로 주입(offline injection)하면 Pass@1 (%) 정확도를 크게 향상시키고 필요한 토큰 수와 Latency를 줄일 수 있어, 공유되지 않은 정보가 실제 의사결정에 유용하다는 것을 입증합니다.
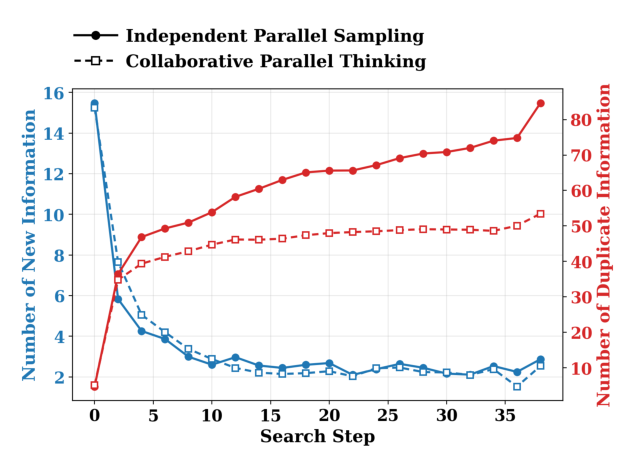
Figure 1 — CPT의 핵심 문제 해결(redundancy 감소) 능력을 보여주는 통계 그래프.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Information Isolation Bottleneck을 해결하기 위해 Collaborative Parallel Thinking (CPT)이라는 학습이 필요 없는 추론 프레임워크를 제안합니다. CPT는 진행 중인 병렬 Branch들로부터 간결한(compact) 중간 정보를 추출하고, 이를 중복 제거된(deduplicated) 쿼리-레벨 Shared Information Pool에 유지합니다. [Figure 2]는 독립적인 병렬 샘플링과 CPT의 동작 방식을 비교하며, CPT가 Branch-레벨 정보가 Shared Information Pool에 통합되어 Branch들이 공유된 정보를 재사용하고 더 빠르게 수렴하는 과정을 보여줍니다. CPT는 고정된 토큰 검색 Step에서 Branch들을 동기화하여 Branch-레벨 정보가 추출, 병합, 중복 제거 과정을 거쳐 이 Pool에 추가됩니다. Pool Entry는 입력 Context를 통해 모든 Branch에 Broadcast되어 후속 검색 Step에서 다른 Branch들이 발견한 정보를 재사용할 수 있도록 합니다. 또한, CPT는 Adaptive Broadcast Scheduling을 사용하여 새로운 정보 획득률(marginal new-information gain)에 따라 공유 시점을 조절하며, 불필요하게 빠른 공유로 인한 탐색 방향의 조기 수렴을 방지하고 Branch의 독립적인 탐색을 보존합니다.
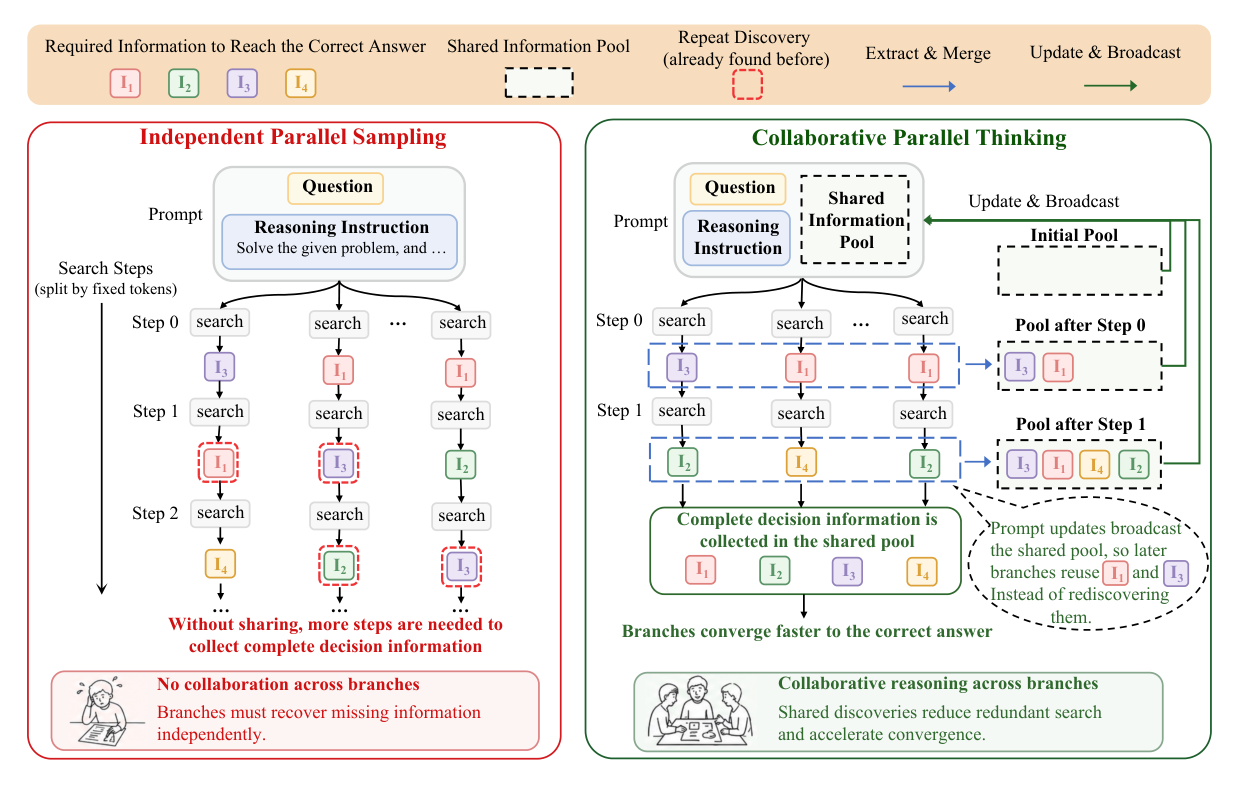
Figure 2 — CPT의 동작 방식과 기존 독립적 병렬 샘플링의 차이를 시각적으로 비교하는 전체 프레임워크 다이어그램.
실험 결과, CPT는 HMMT 및 AIME 벤치마크에서 기존 Baseline 대비 훨씬 강력한 accuracy-latency Pareto frontier를 구축했습니다. 예를 들어, [Figure 3]은 QWEN3-4B-THINKING-2507 및 QWEN3-30B-A3B-THINKING-2507 모델 모두에서 CPT가 더 높은 Pass@1 (%) 및 MV@K (%) 정확도를 더 낮은 Latency (s)로 달성함을 보여줍니다. 또한 [Figure 4]는 Accuracy-Tokens 관점에서도 CPT가 더 적은 토큰으로 더 높은 정확도를 달성하며 효율적인 Token 사용을 입증합니다. Table 1의 결과는 오프라인 정보 주입(offline information injection)이 Pass@1 (%)을 48.95%에서 80% 주입 시 56.20%로 향상시키고, Tokens는 26714에서 11924로, Latency는 395s에서 219s로 각각 감소시켜 CPT의 정보 공유 메커니즘이 효과적임을 시사합니다.
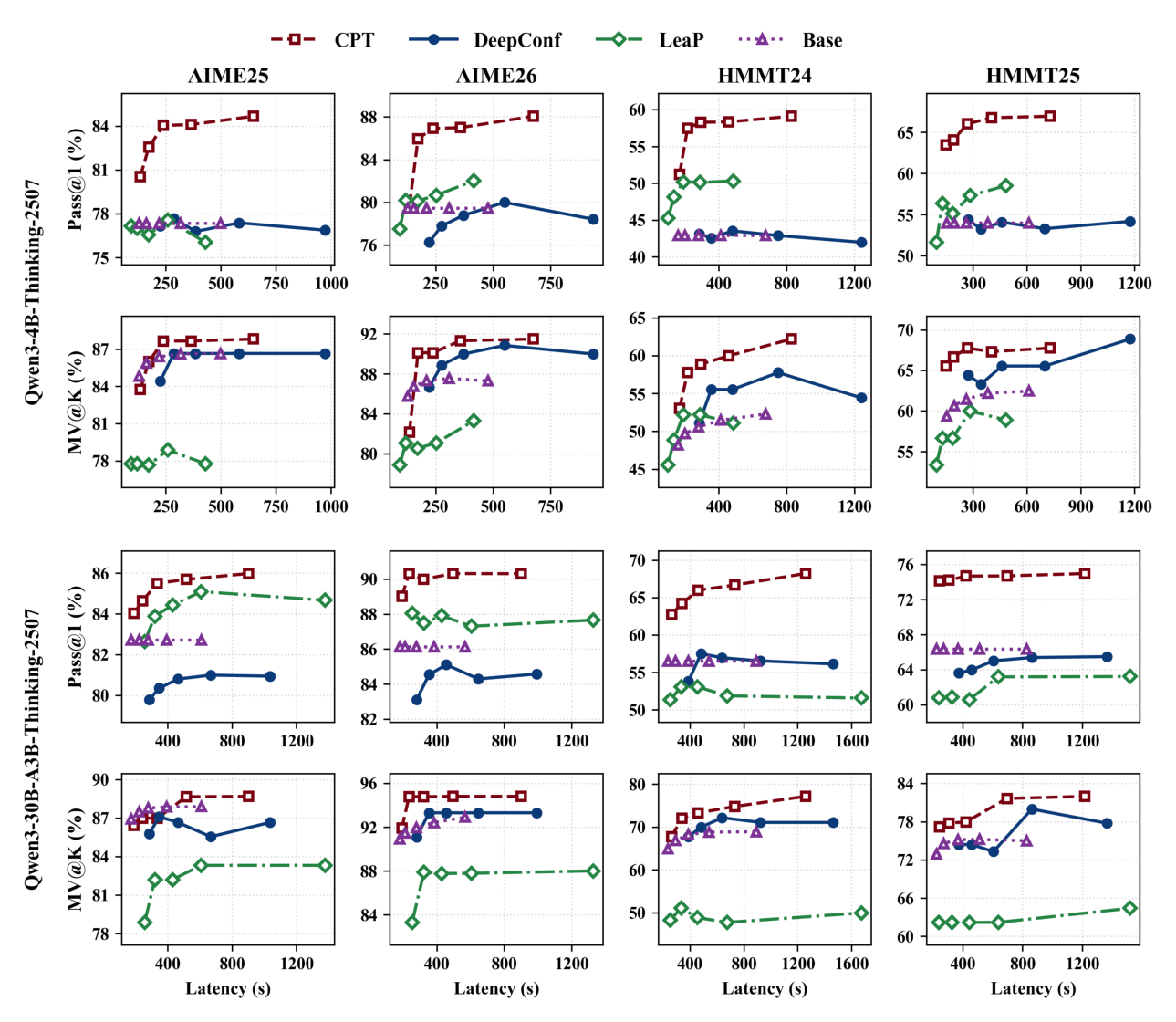
Figure 3 — CPT가 다양한 모델 및 벤치마크에서 기존 Baseline 대비 뛰어난 Accuracy-Latency Pareto Frontier를 달성했음을 보여주는 핵심 실험 결과 그래프.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 병렬 Test-Time Scaling (TTS)의 주요 비효율성인 Information Isolation Bottleneck을 성공적으로 식별하고 해결하기 위해 Collaborative Parallel Thinking (CPT)이라는 훈련-프리 추론 프레임워크를 제안합니다. CPT는 Branch-private한 발견(discovery)을 중복 제거된(deduplicated) Shared Information Pool로 통합하고, 이를 입력 Context를 통해 Broadcast하여 Branch 간 정보 재사용을 가능하게 합니다. 이러한 검색 시간(search-time) 협업을 통해 CPT는 중복 탐색을 줄이고, 정답에 대한 수렴 속도를 높여 LLM의 추론 효율성을 향상시킵니다. HMMT 및 AIME와 같은 도전적인 수학적 추론 벤치마크에서의 실증적 평가는 CPT가 다양한 Rollout Budget 및 모델 스케일에서 기존 Baseline보다 우수한 Accuracy-Latency Pareto Frontier를 제공함을 일관되게 보여줍니다. 이는 LLM의 추론 성능을 향상시키기 위해 단순히 더 많은 추론 Branch를 시작하는 것을 넘어, Branch들이 의사결정 관련 정보를 공유하고 재사용할 수 있도록 하는 것이 효율적인 병렬 TTS의 핵심 방향임을 시사하며, 학계와 산업계 모두에서 LLM 기반 문제 해결 시스템의 효율성과 성능 향상에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
- 현재글 : [논문리뷰] Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
- 다음글 [논문리뷰] Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
댓글