[논문리뷰] Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
링크: 논문 PDF로 바로 열기
저자: Yiren Song, Huilin Zhong, Kevin Qinghong Lin, Haofan Wang, Mike Zheng Shou
1. Key Terms & Definitions
- Cinematic Remaking: 기존 필름 또는 TV 시리즈를 스타일 또는 배우 교체를 통해 새로운 버전으로 변환하면서 내러티브 구조, 모션 안무 및 캐릭터 Identity를 엄격하게 보존하는 장기(long-horizon) Video-to-Video Generation 태스크.
- Dual-Bridge Consistency: Language Bridge (Scene-aware JSON screenplay)와 Visual Bridge (동적으로 할당된 Visual Reference Anchors)를 통해 Input Source Video와 Output Remade Video 간의 Long-term Consistency를 명시적으로 연결하는 메커니즘.
- Batch Keyframe Consistency: Keyframe Generation 단계에서 동일 Scene 및 캐릭터를 공유하는 여러 Keyframe을 Shared Latent Context에서 Grid-based Joint Synthesis 방식으로 공동 생성하여 Intra-scene Consistency를 향상시키는 전략.
- SoapBench: Long-Video Remaking 태스크의 Long-horizon Consistency 및 Narrative Fidelity를 평가하기 위해 제안된 벤치마크.
- VLM-as-a-Judge: Video-Language Model을 사용하여 생성된 비디오의 Character Identity, Scene Consistency, Plot Consistency를 평가하는 프로토콜.
2. Motivation & Problem Statement
본 논문은 Long-horizon Video-to-Video Generation의 핵심 과제인 Long Cinematic Video Remaking 문제를 해결하고자 합니다. 기존 Video Generation 및 Editing Pipeline은 수백 개의 Shot에 걸쳐 Identity Drift, Background Mutation, Semantic Erosion이 누적되어 Long-term Consistency를 유지하는 데 어려움을 겪습니다. 특히, Cinematic Remaking은 Character Identity, Narrative Structure, Motion Choreography 및 Camera Language에 대한 Long-range Consistency를 엄격하게 요구하지만, 기존 시스템들은 이러한 요소들을 Jointly 유지하는 명시적인 메커니즘이 부족했습니다. 따라서, 수 초 이상의 긴 Temporal Horizon에서 Identity Mutation, Background Instability, Semantic Erosion이 발생하는 기존 시스템의 한계를 극복할 새로운 접근 방식이 필요합니다.
3. Method & Key Results
저자들은 Long Cinematic Video Remaking을 위한 Soap2Soap라는 Multi-agent Framework를 제안합니다. 이 Framework는 Video Understanding Agent, Video Generation Agent, Verification Agent의 세 가지 Collaborative Agent로 구성되며, Dual-Bridge Consistency 메커니즘을 통해 Long-horizon Stability를 강화합니다. [Figure 2]는 이 Framework의 전체 아키텍처를 보여줍니다. Video Understanding Agent는 Source Video를 Scene-aware JSON Screenplay (Language Bridge) 및 Visual Reference Anchors (Visual Bridge)로 변환하고, Contextual Memory Allocation을 통해 Shot-specific Memory Packages를 동적으로 생성합니다. Video Generation Agent는 이 Memory Packages를 기반으로 Batch Keyframe Consistency를 통해 여러 Keyframe을 Shared Latent Context에서 Grid-based Joint Synthesis 방식으로 생성한 후, Google Veo 3를 사용하여 Short Video Segments를 만듭니다. 마지막으로 Verification Agent는 생성된 Keyframe과 Video Clip을 Audit하고, Inconsistency가 감지되면 Selective Regeneration을 Trigger하는 Closed-loop Feedback Mechanism을 제공합니다.
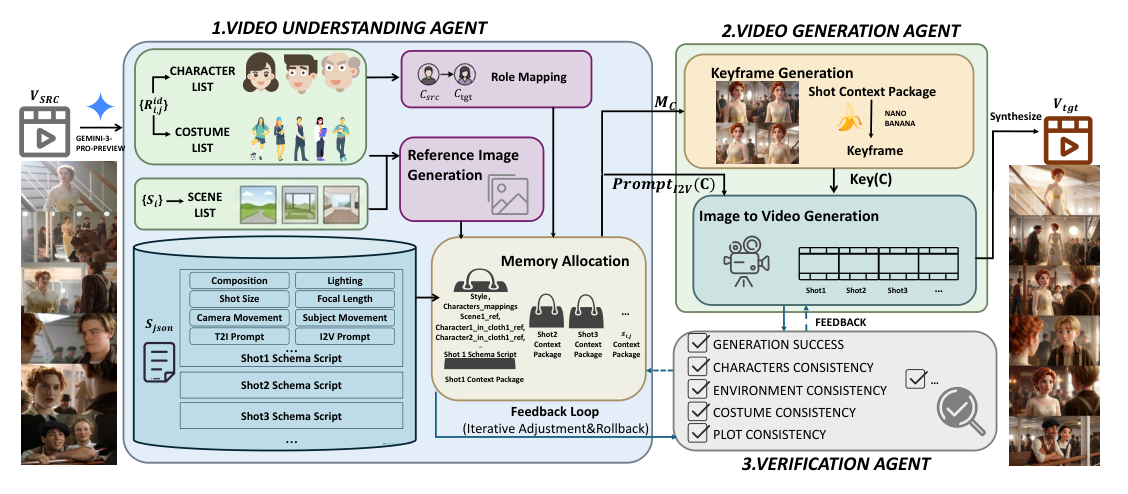
Figure 2 — Soap2Soap의 전체 Multi-agent System 아키텍처를 보여주는 핵심 다이어그램
SoapBench 벤치마크에서 Soap2Soap는 Baseline 방법론인 Mocha, Kling O1, Runway Gen4 대비 모든 평가 지표에서 가장 우수한 성능을 달성했습니다. [Table 1]에서 볼 수 있듯이, Character Identity Preservation에서 ID-VLM↑ 9.17 (Kling O1 8.11, Runway Gen4 7.48 대비 우수), Scene Coherence에서 Scene-VLM↑ 8.84 (Kling O1 8.37, Runway Gen4 7.96 대비 우수)를 기록했습니다. Model-agnostic 지표인 **CLIP Image Score (ID)↑**에서도 0.842로 가장 높았으며, **CLIP Image Score (Scene)↑**에서도 0.819로 Baseline들을 크게 상회했습니다. Ablation Study [Table 2]에서는 Dynamic Memory Allocation이 없을 경우 F1 Score가 0.921에서 0.569로 감소하고, Verification Agent가 없을 경우 F1 Score가 0.936에서 0.887로 감소하여 각 구성 요소의 중요성을 입증했습니다.

Table 1 — Soap2Soap와 Baseline Method들의 Long-video Remaking 성능을 정량적으로 비교하는 주요 결과 테이블

Table 2 — Soap2Soap의 핵심 구성 요소 (Dynamic Memory Allocation, Verification Agent)의 기여도를 보여주는 Ablation Study 결과 테이블
4. Conclusion & Impact
본 논문은 Character Identity Drift 및 Semantic Erosion과 같은 Cinematic Remaking의 Long-standing Challenge를 해결하기 위해 Soap2Soap Framework를 성공적으로 제안합니다. Dual-Bridge Consistency와 Grid-based Batch Synthesis를 통해 Narrative Fidelity와 Visual Stability를 수백 개의 Shot에 걸쳐 보장함으로써, Long-sequence Generation에서 발생하는 에러 축적을 효과적으로 완화했습니다. SoapBench 벤치마크를 통해 Soap2Soap가 State-of-the-art Academic Method 및 Commercial API 대비 Identity 및 Scene Coherence에서 월등한 성능을 보임을 입증했습니다. 이 연구는 High-fidelity Long-form Video Transformation을 위한 확장 가능하고 제어 가능한 Foundation을 구축하여, 향후 Fine-grained Audio-visual Synchronization 및 Extreme Motion Dynamics 연구의 기반을 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery
- [논문리뷰] DataEvolver: Self-Evolving Multi-Agent Data Construction for Text-Rich Image Generation
- [논문리뷰] Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
- [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
Review 의 다른글
- 이전글 [논문리뷰] Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
- 현재글 : [논문리뷰] Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
- 다음글 [논문리뷰] SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
댓글