[논문리뷰] SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
링크: 논문 PDF로 바로 열기
저자: Haosong Peng, Hao Li, Jiaqi Chen, Yuhao Pan, Runmao Yao, Yalun Dai, Fushuo Huo, Fangzhou Hong, Zhaoxi Chen, Haozhao Wang, Dingwen Zhang, Ziwei Liu, Wenchao Xu
1. Key Terms & Definitions
- SpatialBench: 공간 Foundation Model (SFM)의 all-round player 역량을 포괄적으로 평가하기 위해 제안된 cross-paradigm, domain-diverse 벤치마크로, deterministic sampling 방식을 채택합니다.
- Multi-Density Evaluation Protocol: SpatialBench 내에서 모델의 robustness를 Single-frame, Sparse, Medium, Dense의 4가지 input density regime에 걸쳐 체계적으로 평가하는 프로토콜입니다.
- DA-Next-5M: egocentric 및 wrist-view domain의 데이터 격차를 해소하기 위해 5.5M 프레임과 22K 장면으로 구성된 대규모 3D dataset입니다.
- DA-Next: DA-Next-5M으로 훈련된 강력한 domain-specific baseline model로, Depth-Anything-3 (DA3) 아키텍처를 기반으로 absolute scale 예측 기능을 확장했습니다.
- Full-Context Attention Models: 전체 입력 시퀀스에 걸쳐 globally coupled attention을 사용하여 geometric reasoning을 수행하는 모델로, 일반적으로 높은 정확도를 보이지만 GPU memory consumption이 큽니다.
- Bounded-Memory Models: Streaming, Chunk-wise, Test-Time Training (TTT)과 같은 접근 방식을 통해 active context를 제한하여 긴 시퀀스를 처리하고 long-horizon scalability를 제공하는 모델입니다.
2. Motivation & Problem Statement
본 논문은 현재 Spatial Foundation Models (SFMs)이 standard dataset에서 인상적인 성능을 보여주지만, 다양한 downstream task, 임의의 viewpoint, 변화하는 scene domain, 다양한 input density, 그리고 특정 hardware constraint에 걸쳐 robust하게 generalizing할 수 있는 all-round player인지에 대한 근본적인 질문에 답하고자 합니다. 기존 평가 방식은 narrow paradigm coverage, limited scene domain, arbitrary frame sampling이라는 내재적 한계가 있어 모델의 진정한 generalization capability를 평가하기 어렵습니다. 예를 들어, 현재 benchmark는 feed-forward, optimization-based, streaming, SLAM-based, chunk-based, test-time training (TTT) 등 다양한 model paradigm 중 극히 일부만을 평가하며, input density 변화에 따른 모델의 scaling behavior를 제대로 반영하지 못합니다 [Figure 1]. 또한, standard indoor 또는 object-centric reconstruction dataset으로는 robotics, autonomous driving, egocentric perception, wrist-mounted manipulation과 같은 실제 응용 분야의 다양성을 포착할 수 없어 real-world spatial intelligence에 대한 포괄적인 평가가 불가능합니다.

Figure 1 — 전체 벤치마크 디자인, 포함된 데이터셋, 모델, 패러다임, 주요 발견 사항을 요약하는 핵심 다이어그램
3. Method & Key Results
본 연구는 이러한 격차를 해소하기 위해 cross-paradigm, domain-diverse SpatialBench를 제안합니다. SpatialBench는 19개 dataset과 546개 장면을 포함하며, 5개 spatial domain (Room/Object, Roaming, Driving, Ego-View, Wrist-View)에 걸쳐 41개 모델을 6개 paradigm으로 분류하고 4개 input density setting (Single-frame, Sparse, Medium, Dense)에서 5개 task suite로 평가합니다 [Figure 1, Figure 2]. 특히, DA-Next-5M이라는 대규모 3D dataset (5.5M photorealistic, 고품질 프레임)을 egocentric 및 wrist-view 관점에서 큐레이션하여 기존 benchmark의 가장 큰 데이터 격차를 해소합니다 [Figure 4]. 이 dataset으로 훈련된 DA-Next model은 DA3 아키텍처를 기반으로 absolute scale 예측을 위해 확장되었습니다 [Figure 5].

Figure 5 — 제안된 baseline model인 DA-Next의 아키텍처를 설명하는 다이어그램
SpatialBench의 광범위한 평가 결과, 몇 가지 핵심 통찰력을 발견했습니다. 첫째, Full-context attention models인 DA3-Giant 및 π³는 bounded-memory 접근 방식보다 낮은 depth error를 달성하며, high-memory GPU에서 정확도 상한선을 정의합니다 [Table 1, Figure 6]. 이는 globally coupled representation이 high-fidelity 3D geometry estimation에 필수적임을 시사합니다. 둘째, Bounded-memory models는 GPU memory consumption을 제한하면서 long-sequence reconstruction을 가능하게 하지만, pairwise geometric precision을 일부 희생합니다 [Figure 7, Table 1]. 셋째, data quality가 data volume보다 중요하며, DA3처럼 신중하게 큐레이션된 pseudo-GT supervision이 더 크지만 노이즈가 많은 학습 데이터보다 일관되게 우수한 성능을 보입니다 [Figure 8]. 마지막으로, egocentric 및 wrist-view domain은 cross-method average에서 성능이 급격히 저하되는 dominant Out-of-Distribution (OOD) failure mode로 나타났습니다 [Figure 9]. DA-Next는 DA3-Giant 대비 depth AbsRel에서 sparse input에 대해 47%, medium input에 대해 59% 개선을 보였고, pose AUC@30에서 각각 3.1%와 5.5% 향상되어 targeted in-domain data curation이 embodied domain gap을 효과적으로 줄임을 입증했습니다 [Table 1].
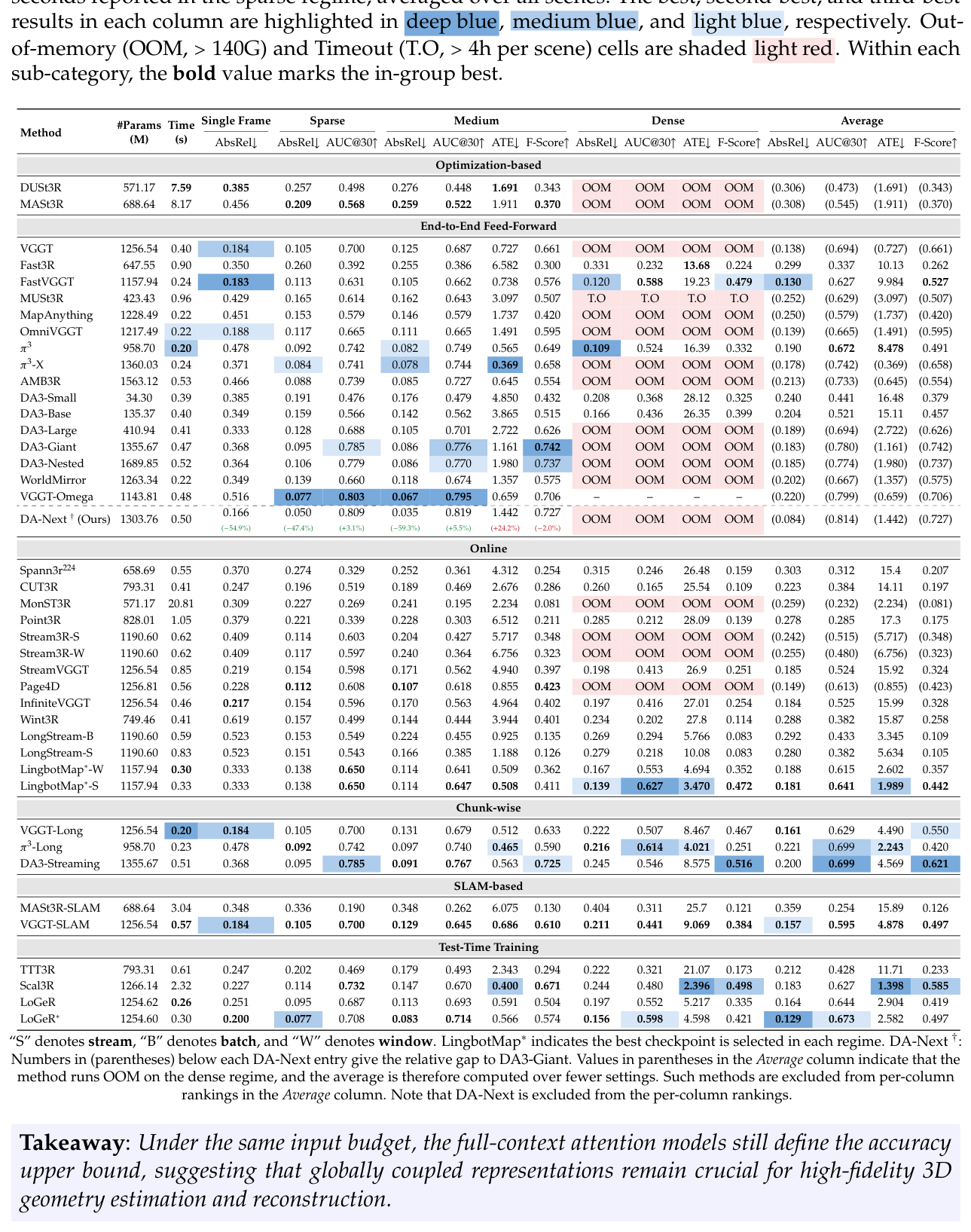
Table 1 — 모든 모델과 설정에 대한 핵심 정량적 성능 비교를 담은 주요 결과 테이블
4. Conclusion & Impact
결론적으로, 현재 Spatial Foundation Models은 아직 진정한 all-round player가 아니며, domain generalization 및 input-density robustness에서 중요한 격차를 보입니다. SpatialBench는 3D spatial foundation models의 성능을 cross-paradigm, domain-diverse, input-density 관점에서 종합적이고 reproducible하게 평가하는 최초의 표준화된 benchmark입니다. 특히, egocentric 및 wrist-view domain에서 가장 심각한 data gap을 식별하고, 이를 해결하기 위해 대규모 DA-Next-5M dataset과 강력한 DA-Next baseline model을 도입했습니다. 이 연구는 full-context attention 모델이 정확도 상한선을 제공하고, bounded-memory 모델이 long-horizon scalability를 가능하게 하며, data quality가 data volume보다 중요하다는 중요한 통찰력을 제공합니다. SpatialBench는 미래 연구를 위한 견고한 기반을 제공하며, 더욱 generalizable하고 robust한 3D foundation models 개발 방향을 제시함으로써 학계와 산업계 모두에 큰 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
- [논문리뷰] ESARBench: A Benchmark for Agentic UAV Embodied Search and Rescue
- [논문리뷰] Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
Review 의 다른글
- 이전글 [논문리뷰] Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
- 현재글 : [논문리뷰] SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
- 다음글 [논문리뷰] The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
댓글