[논문리뷰] The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
링크: 논문 PDF로 바로 열기
저자: MiniMax, Aili Chen, Aonian Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Mixture-of-Experts (MoE): 모델 용량을 확장하면서도
per-token compute budget을 낮게 유지하도록 설계된sparse language model아키텍처입니다. - Multi-Token Prediction (MTP): 모델이
next K tokens를jointly예측하도록 훈련하는 모듈로,richer training signals을 제공하고inference시speculative decoding을 가능하게 합니다. - Forge:
large-scale,general-purpose agentic reinforcement learning을 위해 설계된agent-native RL system으로,white-box및black-box agent를unified training loop내에서 지원합니다. - Agent-as-a-Verifier (AaaV):
application developmenttrajectory의 유효성을 검사하기 위해sandboxed environment에generated application을 배포하고tool-assisted interaction을 통해 평가하는framework입니다. - Interleaved Thinking: 모델이
natural-language reasoning과external tool invocation(예:code execution,web browsing,API calls)을single trajectory내에서alternating sequence로 수행하는generation protocol입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 large language model (LLM)이 long-horizon agentic workflow로 전환됨에 따라 발생하는 efficiency 및 cost bottleneck 문제와 intrinsically complex, high-stakes task 해결의 어려움을 다룹니다. 기존 LLM은 short, single-turn dialogue에 최적화되어 있어 production-grade software engineering이나 knowledge-intensive office automation과 같은 agentic task에 적용될 때 context length로 인한 inference 및 training 비용 문제가 발생합니다. 또한, sparse attention과 같은 효율적인 attention mechanism은 reasoning, coding, agent tasks 전반에 걸쳐 full attention의 품질을 안정적으로 match하지 못하는 한계를 보였습니다. 이러한 문제를 해결하기 위해 저자들은 mini activations을 통해 maximum real-world intelligence를 구현하는 MiniMax-M2 series를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MiniMax-M2 series를 mini activations으로 maximum real-world intelligence를 구현하는 Mixture-of-Experts (MoE) language model로 소개합니다. flagship M2는 total parameters 229.9B 중 per token activated parameters가 9.8B에 불과하며, 62-layer decoder-only Transformer 아키텍처를 가집니다. 제안된 시스템은 (i) agent-driven data pipelines [Figure 3], (ii) scalable agent-native RL system인 Forge [Figure 4], 그리고 (iii) self-evolution 능력을 갖춘 M2.7 checkpoint로 구성됩니다 [Figure 8].
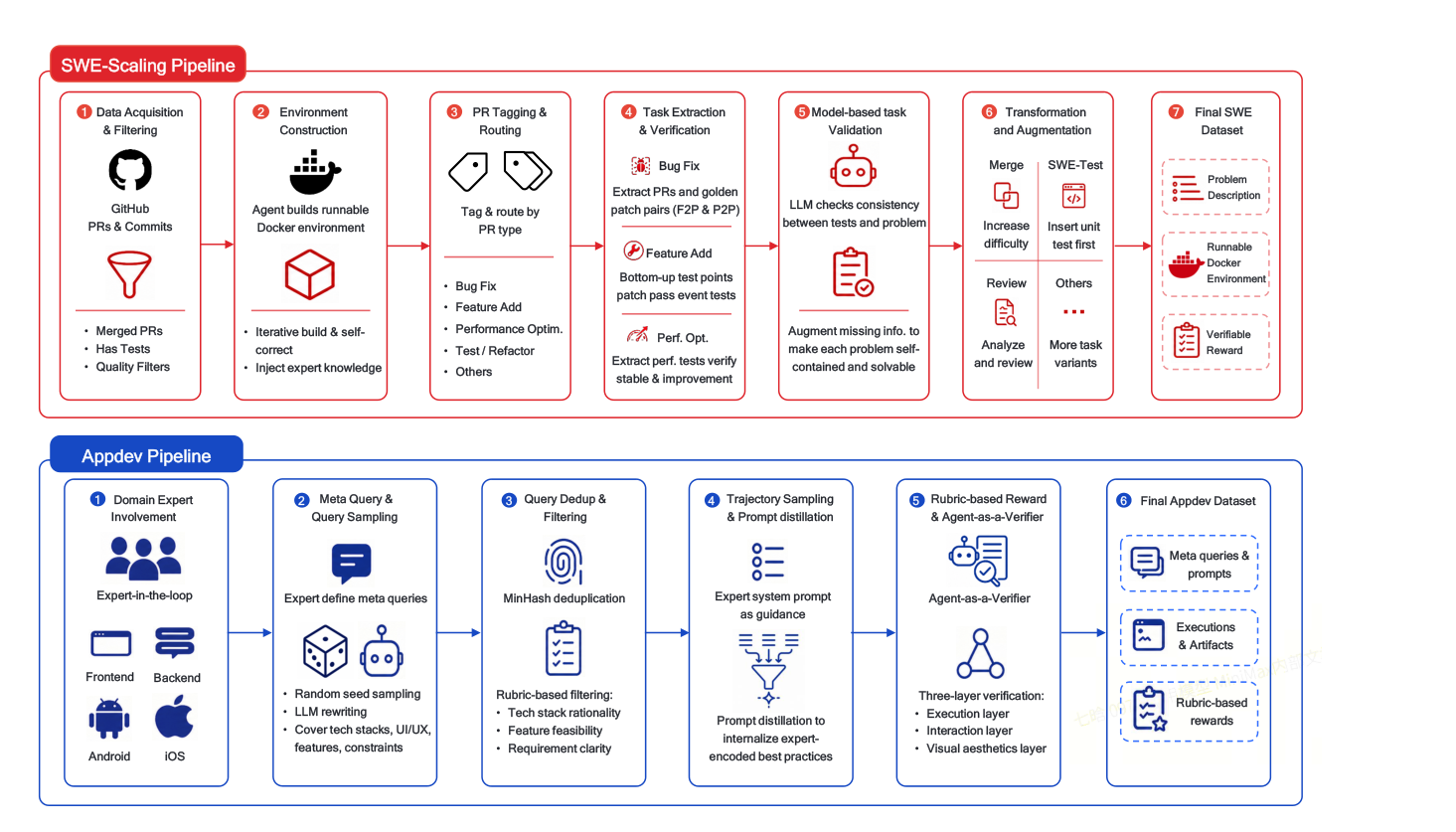
Figure 3
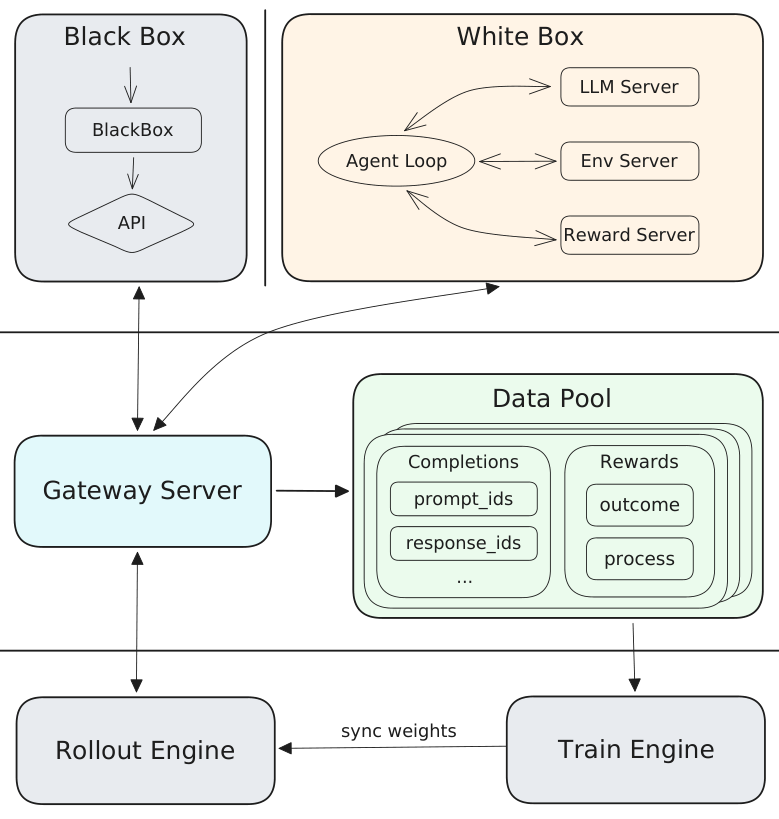
Figure 4
M2.7은 agentic coding, deep search, office-task, reasoning benchmarks에서 frontier-tier performance를 달성합니다 [Table 4]. SWE-bench Pro에서 56.2, Multi-SWE-bench에서 52.7을 기록하며, Terminal-Bench 2.0에서 57.0을 달성했습니다. application development 분야에서는 VIBE-Pro에서 55.6으로 leading closed-weight baselines와 동등한 수준을 보였습니다. 특히 MLE Bench Lite에서 66.6%의 medal rate를 달성하며 self-evolution 능력을 입증했습니다 [Table 4]. 이러한 성능은 agent-driven data pipeline을 통해 수집된 verifiable trajectory와 Forge RL system의 Windowed FIFO scheduling, prefix-tree merging 등의 optimization 덕분입니다. 또한 M2.7은 training runs을 autonomously debug하고 agent scaffold를 수정하는 self-evolution을 통해 human-in-the-loop bottleneck을 줄였습니다 [Figure 8].
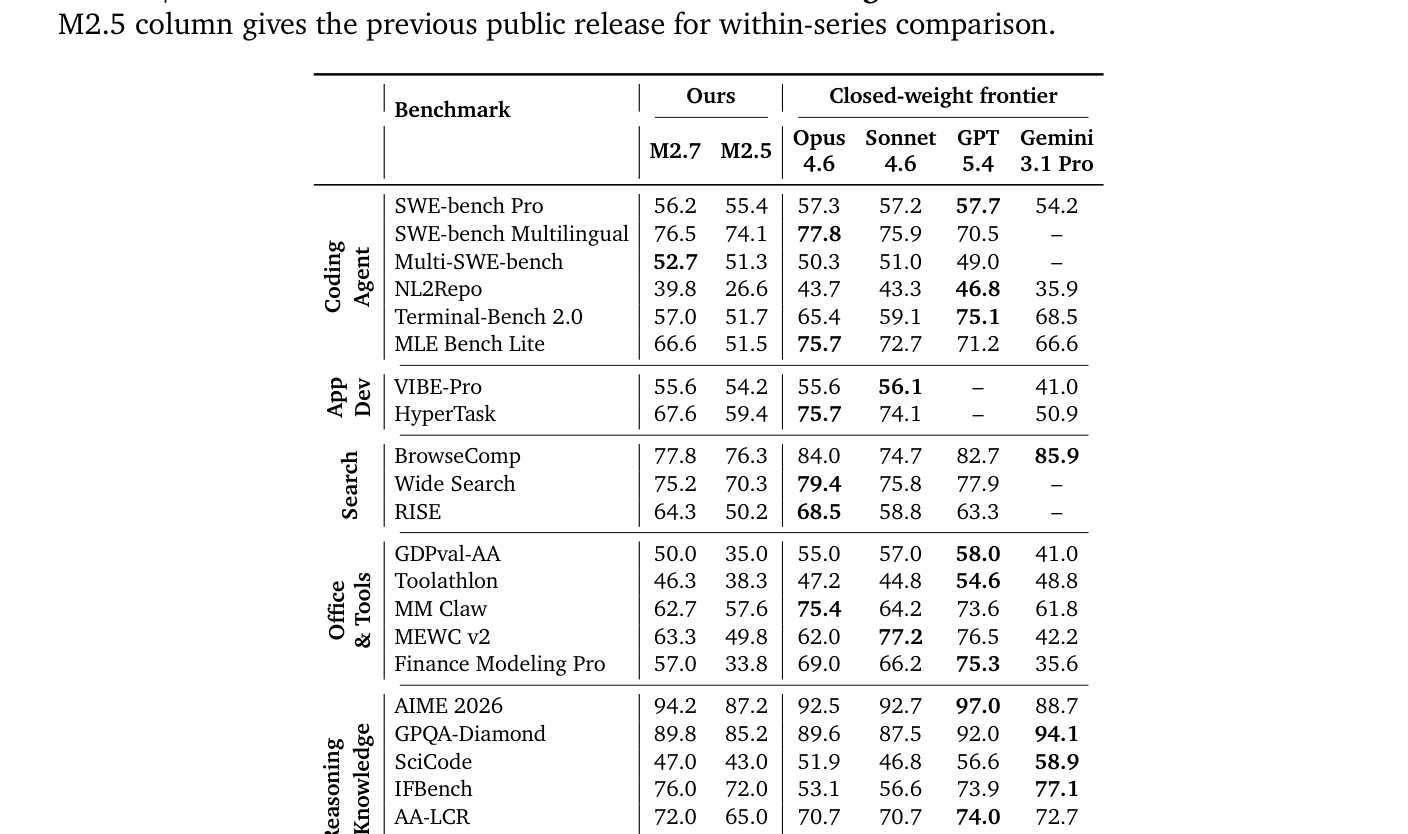
Table 4
4. Conclusion & Impact (결론 및 시사점)
MiniMax-M2 series는 mini activations을 통해 maximum real-world intelligence를 달성한다는 핵심 원칙을 기반으로 합니다. M2.7은 9.8B activated parameters라는 footprint로도 agentic coding, deep search, office-task, reasoning benchmarks에서 frontier-tier performance를 보여주며, closed-weight frontier systems와 경쟁력을 갖춥니다. 이 연구는 agent-driven data pipelines, Forge RL system, 그리고 self-evolution이라는 세 가지 핵심 구성 요소를 통해 LLM의 long-horizon agentic task 수행 능력을 크게 향상시켰습니다. 이는 agentic AI 개발의 efficiency와 scalability를 높이는 중요한 진전이며, 향후 autonomous ML-engineering 및 real-world problem-solving 분야에 큰 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
- [논문리뷰] LongCat-Flash-Thinking-2601 Technical Report
- [논문리뷰] RewardHarness: Self-Evolving Agentic Post-Training
- [논문리뷰] OpenClaw-RL: Train Any Agent Simply by Talking
- [논문리뷰] Dr. Zero: Self-Evolving Search Agents without Training Data
Review 의 다른글
- 이전글 [논문리뷰] SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
- 현재글 : [논문리뷰] The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
- 다음글 [논문리뷰] AI Research Agents Narrow Scientific Exploration
댓글