[논문리뷰] OPRD: On-Policy Representation Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shenzhi Yang, Guangcheng Zhu, Bowen Song, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- On-Policy Distillation (OPD): 학생 모델이 생성한 응답(on-policy rollouts)을 기반으로 학생의 conditional distribution을 Teacher의 conditional distribution과 비교하여 학습하는 지식 증류(Knowledge Distillation) 방식입니다. 기존 Knowledge Distillation의 Exposure Bias 문제를 해결합니다.
- Representation Distillation: 모델의 최종 출력(Output Space) 대신 중간 Hidden States (Intermediate Representations)를 직접 Teacher 모델과 일치시키도록 학습하는 기법입니다.
- LM-head Information Bottleneck: LLM의 마지막 Hidden State를 Logits으로 매핑하는 LM Head 레이어가 정보를 압축하고, Softmax 함수가 Additive Constants에 불변하여 Teacher의 풍부한 구조적 Hidden State 정보가 손실되는 현상입니다.
- Signal-to-Noise Ratio (SNR) Collapse: OPD의 sampled-token variant에서 학습 후반부에 Student의 분포가 Teacher에 가까워질수록 Gradient의 Signal이 Noise에 비해 급격히 작아져 학습이 정체되는 현상입니다.
- Effective Null Space ($\mathcal{N}_W$): LM Head의 Weight Matrix ($W_{\mathrm{head}}$)에 의해 Output Space에서 Additive Softmax-Invariant Shift를 생성하는 Hidden State Perturbation들의 집합을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Large Language Models (LLMs)의 Post-training에 필수적인 On-Policy Distillation (OPD) 방식의 본질적인 두 가지 한계점을 지적하며, 이를 해결하기 위한 새로운 접근 방식인 OPRD (On-Policy Representation Distillation)를 제안합니다. 기존 OPD는 모든 변형(sampled-token, full-vocabulary, top-k)이 Next-token Log-probabilities를 매칭하여 Student를 Output Space에서만 지도합니다.
첫째, 가장 널리 사용되는 sampled-token OPD는 Vocabulary size가 매우 큰 경우 (예: Qwen 시리즈의 $|\mathcal{V}| \approx 150K$), 각 위치의 Reward가 KL Divergence의 Single-sample Monte Carlo Estimate로 계산되어 학습이 진행될수록 Sampling Variance가 신호(Signal)를 압도하게 됩니다. 이로 인해 Signal-to-Noise Ratio (SNR)가 붕괴되어 학습 후반부에 정확도가 정체되거나 Teacher보다 훨씬 낮은 수준에서 맴도는 문제가 발생합니다 [Figure 3].
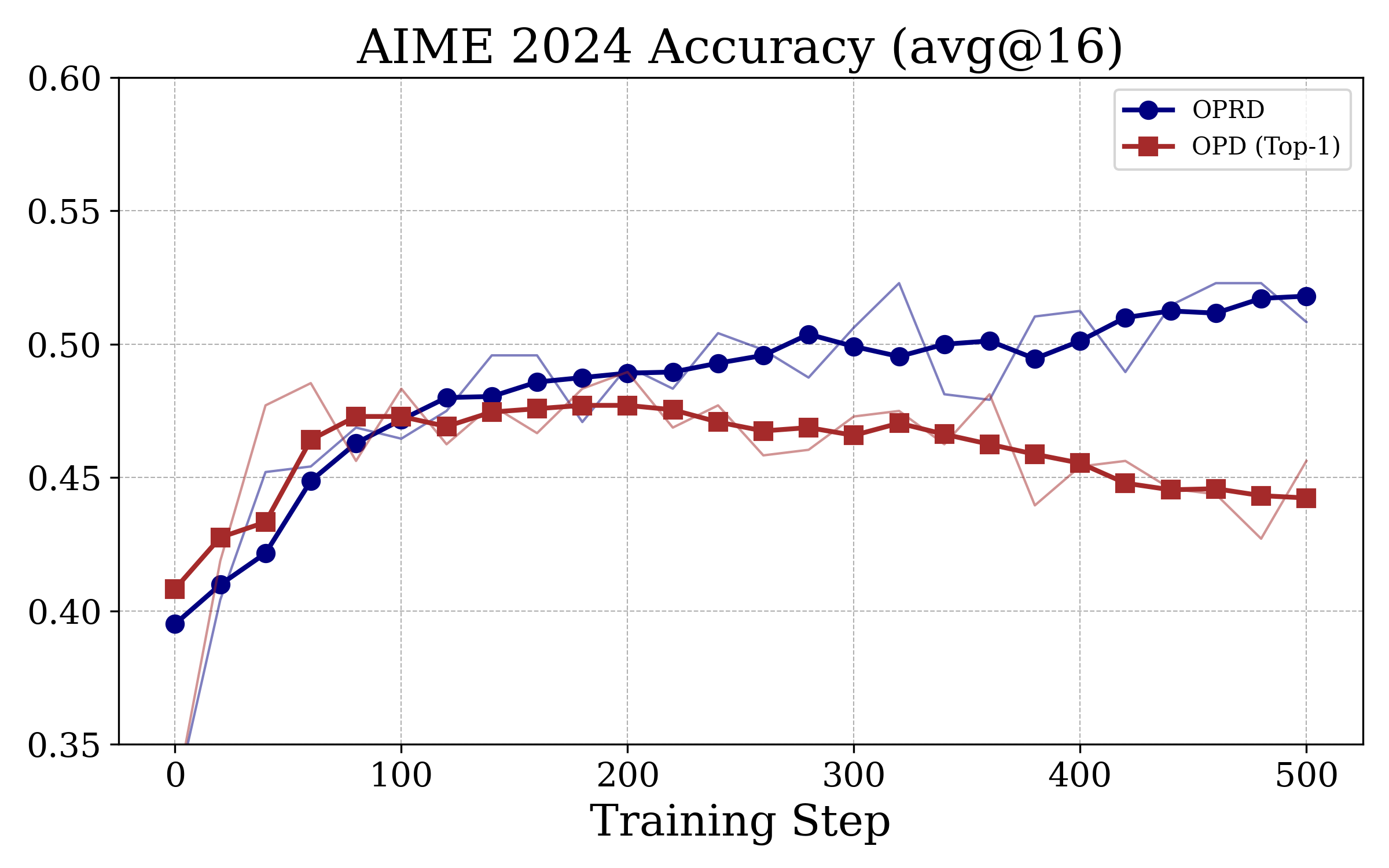
Figure 3 — OPRD vs. OPD 학습 동학
둘째, 모든 Output-space OPD는 Teacher를 Black-box Probability Oracle처럼 취급하여, LM Head 이후의 분포만 쿼리하고 Teacher가 실제로 계산한 다차원 Intermediate Hidden States를 완전히 버립니다. Softmax Projection은 Additive Constants에 불변하고 Ill-conditioned $W_{\mathrm{head}}$에 의해 정보를 크게 압축하므로, Output Distribution이 유사하더라도 Hidden States는 크게 다를 수 있습니다. 이는 Teacher의 내부 추론 과정에 대한 신호를 Student에게 전달하지 못하며, On-policy Rollout 시 이미 계산된 Hidden States를 버리는 비효율성을 야기합니다 [Figure 2].
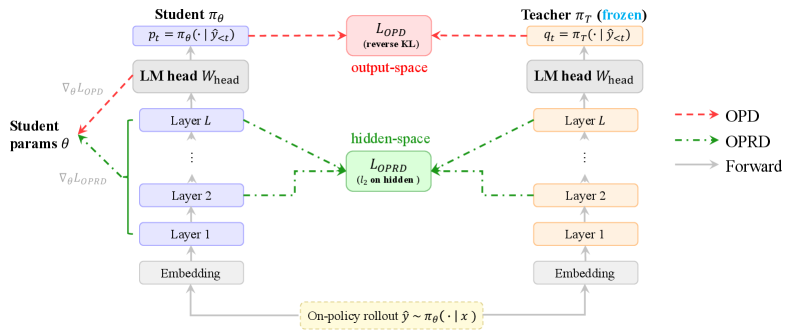
Figure 2 — OPRD vs. OPD 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 OPD의 두 가지 한계점을 극복하기 위해 On-Policy Representation Distillation (OPRD)를 제안합니다. OPRD는 On-policy Rollouts ($x, \hat{y}$)를 사용하여 Student의 Intermediate Hidden Representations를 Teacher의 Hidden Representations와 선택된 Transformer Layers 및 Response Positions에서 정규화된 Mean-Squared Error (MSE) Objective를 통해 정렬시킵니다 [Figure 2].
OPRD의 핵심 Objective는 다음과 같습니다: $\mathcal{L}{\mathrm{OPRD}}(\theta)=\mathbb{E}{x\sim\mathcal{D}{x},;\hat{y}\sim\pi{\theta}(\cdot\mid x)}\left[\frac{1}{|\mathcal{L}{\mathrm{layer}}|}\sum{l\in\mathcal{L}{\mathrm{layer}}}\frac{1}{\sum{t=1}^{T}m_{t}}\sum_{t=1}^{T}m_{t},\frac{1}{d}\Bigl|h_{\theta,t}^{(l)}-\mathrm{sg}!\bigl(h_{T,t}^{(l)}\bigr)\Bigr|_{2}^{2}\right]$
이 방법론은 두 가지 이론적 이점을 제공합니다. 첫째, OPRD의 MSE Objective는 Rollout의 결정론적 함수이므로 Gradient에 추가적인 Sampling Variance가 Zero입니다 [cite: 1, Theorem 1]. 이로써 학습 후반부의 Signal-to-Noise Collapse 문제를 해결합니다. 둘째, OPRD는 LM Head를 완전히 우회하여 Teacher의 Per-position, Per-layer 구조적 정보를 직접 노출하며, Output-space Objective가 필연적으로 버리는 풍부한 Supervision Signal을 제공합니다 [cite: 1, Theorem 2]. 또한, Hidden Dimension ($d$)이 Vocabulary Dimension ($|\mathcal{V}|$)보다 훨씬 작기 때문에, Loss Path 계산 시 [B, T, $|\mathcal{V}|$] Logits Tensor를 Materialize할 필요가 없어 메모리 사용량과 Wall-clock Time을 크게 절감합니다.
실험 결과, OPRD는 세 가지 Competition Mathematics Benchmarks (AIME 2024, AIME 2025, AIMO)에서 Student-Teacher Gap을 효과적으로 줄이며, Teacher 모델에 근접하는 정확도를 달성했습니다. 예를 들어, OPRD는 AIMO 벤치마크에서 Teacher와 거의 동등한 79.1%의 Avg@16 Accuracy를 기록하며 Student-Teacher Gap을 거의 완전히 메웠습니다 [Table 2]. 반면, 기존 Output-space OPD (top-1 및 top-16)는 Teacher보다 수 포인트 낮은 지점에서 정체되거나 진동했습니다 [Table 2, Figure 3].
효율성 측면에서, OPRD는 동일한 Hardware 및 Rollout Budget에서 OPD top-16 대비 1.44배 빠른 Wall-clock Training Time과 최대 54% 적은 Actor-update Transient Memory를 사용했습니다 [Table 3]. 이는 OPRD Loss Path가 LM Head 이전에 작동하여 [B, T, $|\mathcal{V}|$] Logits Tensor 생성을 피하기 때문입니다 [Table 3]. 또한, OPRD는 더 높은 정확도를 달성하면서도 더 짧은 평균 Response Length (OPD의 약 7,000 Token 대비 OPRD는 약 5,700 Token)를 보여주어, 더 간결하고 효율적인 추론 Chain을 유도함을 시사합니다 [Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 기존 On-Policy Distillation (OPD)의 한계점인 Gradient Variance와 LM-head Information Bottleneck 문제를 해결하기 위한 On-Policy Representation Distillation (OPRD)를 제안합니다. OPRD는 Student의 Hidden States를 Teacher의 Hidden States에 직접 정렬시킴으로써 Sampling Variance가 없는 결정론적인 Gradient를 제공하고, Teacher의 풍부한 내부 구조적 정보를 활용하여 Student의 학습을 효과적으로 촉진합니다.
실험적으로 OPRD는 Competition Mathematics Benchmarks에서 Student-Teacher Gap을 성공적으로 줄였으며, 기존 Output-space OPD 방식들이 겪는 Late-stage Stagnation 현상 없이 학습 전반에 걸쳐 monotonic improvement를 보였습니다 [cite: 1, Figure 3]. 또한, OPRD는 LM Head를 우회하는 설계 덕분에 학습 효율성 측면에서 Wall-clock Time과 Transient GPU Memory 사용량을 크게 절감하여, Accuracyd와 Training Cost 면에서 기존 OPD Baseline들을 Pareto-dominates 합니다 [cite: 1, Figure 1].
이 연구는 LLM Distillation 분야에서 Hidden-state Representations가 Output Space Distillation에 대한 새로운 보완적 축(New and Orthogonal Axis of Supervision)이 될 수 있음을 보여줍니다. OPRD는 Multi-model RL Merging 및 On-policy Self-Distillation (OPSD)과 같은 고가치 시나리오에서 특히 유용하며, 미래 연구에서는 Cross-architecture Distillation, Adaptive Layer 및 Position Selection, Attention-map Distillation 등 다양한 확장 가능성을 제시합니다.
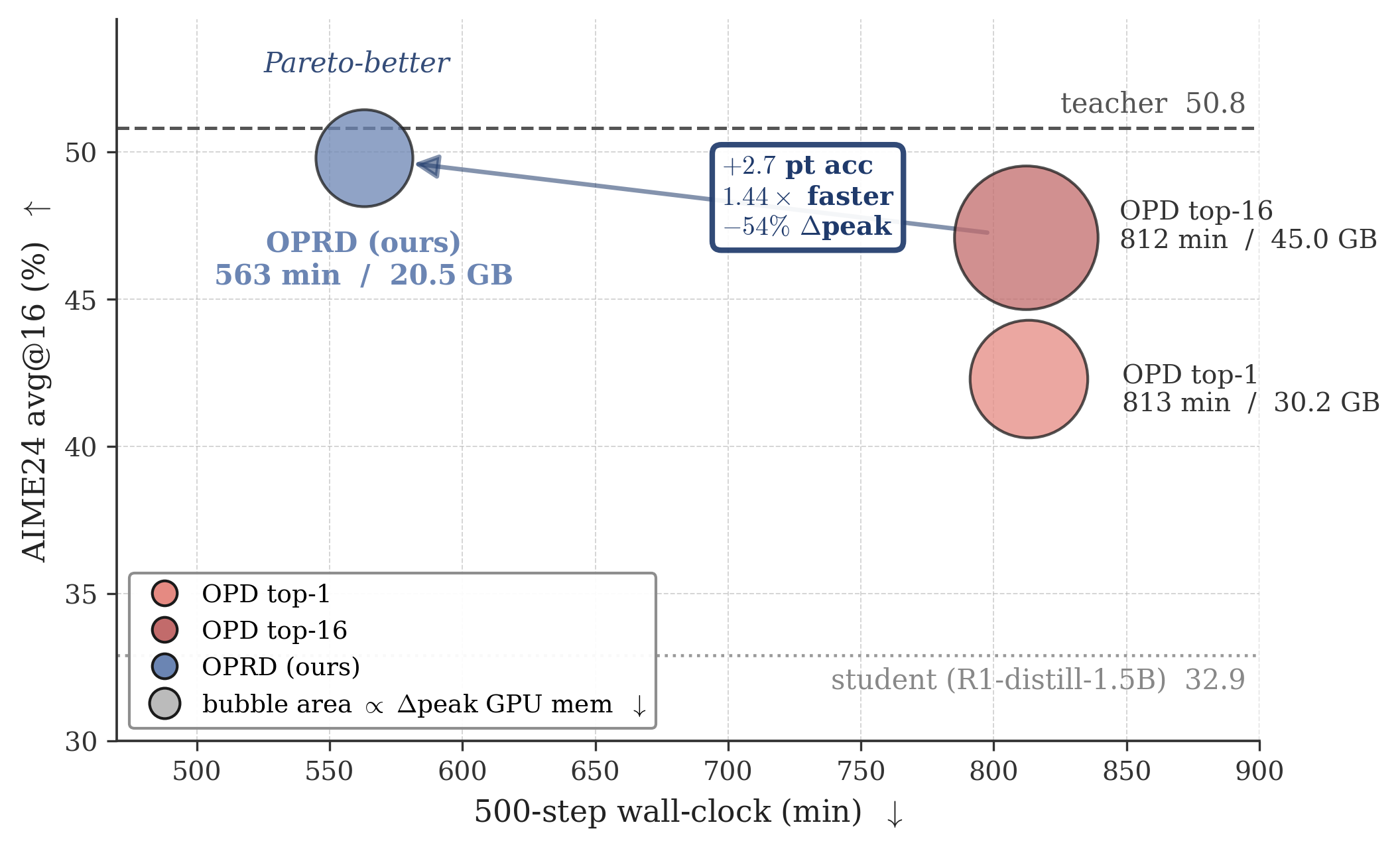
Figure 1 — OPRD의 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
- [논문리뷰] On-Policy Self-Distillation for Reasoning Compression
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
Review 의 다른글
- 이전글 [논문리뷰] Multimodal Music Recommendation System using LLMs
- 현재글 : [논문리뷰] OPRD: On-Policy Representation Distillation
- 다음글 [논문리뷰] Personal AI Agent for Camera Roll VQA
댓글