[논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuying Li, Leqi Zheng, Yongzi Yu, Wenrui Zhou, Xuchang Zhong, Xing Hu, Jing Jin, Huangjie Yuan, Tao Feng
1. Key Terms & Definitions (핵심 용어 및 정의)
- On-Policy Distillation (OPD): 학생 모델이 생성한 trajectory 데이터를 활용하여 교사 모델의 지식을 전수받는 post-training 패러다임입니다.
- FiRe-OPD: Trajectory-level의 필터링과 token-level의 soft reweighting을 결합하여 distillation 효율을 극대화하는 제안 프레임워크입니다.
- Trajectory Filtering: 교사 모델의 likelihood가 낮은 저품질 rollout을 사전에 제거하여 노이즈 없는 학습을 유도하는 기법입니다.
- Soft Reweighting: 고정된 토큰 선택 대신, 교사 모델의 confidence와 학생 모델의 confusion을 결합하여 각 토큰의 중요도를 연속적인 가중치로 부여하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 OPD가 가진 불균일한 학습 가치 문제를 해결하기 위해 최적화 Granularity를 재설계하고자 합니다. 기존 연구들은 단순히 전체 trajectory를 사용하거나, 개별 토큰을 선별하는 Hard selection 방식에 의존하여 정보 손실과 최적화의 불안정성을 초래했습니다 [Figure 1]. 특히, Granularity 간의 상호보완적 관계를 무시한 채 단일 차원의 품질 개선에만 집중한다는 한계가 있습니다 [Table 1]. 따라서 저자들은 trajectory와 token 수준에서 신호를 통합적으로 제어할 수 있는 효율적인 distillation 전략이 필요하다고 판단하였습니다.
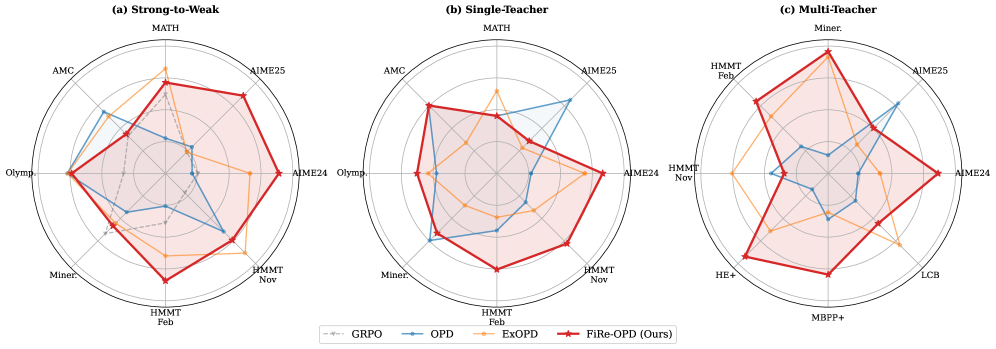
Figure 1 — 시나리오별 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 FiRe-OPD 프레임워크를 제안하여, 교사 모델의 신뢰도가 낮은 trajectory를 먼저 필터링하고 이후 남은 토큰들에 대해 중요도 가중치를 부여합니다 [Figure 2]. Trajectory 수준에서는 교사 모델의 normalized log-probability를 기반으로 저품질 rollout을 제거하며, token 수준에서는 교사 모델의 confidence($c^T$)와 학생 모델의 confusion($c^S$)을 곱하여 가중치($w_t$)를 계산합니다 [Eq 7]. 이러한 soft reweighting 전략은 정보 손실을 최소화하면서도 모델의 학습 효율을 극대화합니다 [Figure 3]. Strong-to-weak 실험 설정에서 FiRe-OPD는 AIME 2024 벤치마크에서 기존 OPD 대비 +6.25 포인트 향상된 성능을 기록하였습니다 [Table 2]. 또한 Multi-teacher 설정에서도 MinervaMATH에서 +18.81의 압도적인 성능 우위를 보이며, 다양한 Distillation 시나리오에서 범용적인 성능 향상을 입증하였습니다 [Table 4]. 이는 Hard filtering 기반의 trajectory 제어와 Soft reweighting 기반의 token 제어가 결합될 때 최적의 성능을 낸다는 사실을 뒷받침합니다 [Table 6].
Figure 2 — 제안 모델 아키텍처
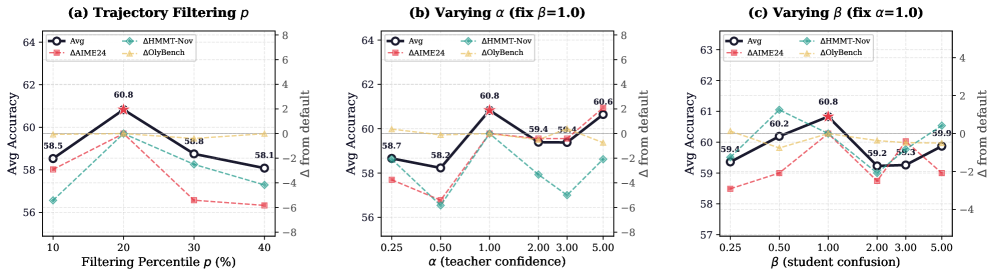
Figure 3 — 하이퍼파라미터 민감도 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 OPD 최적화 과정에서 Granularity의 중요성을 규명하고, FiRe-OPD를 통해 효율적이고 선택적인 지식 전수 체계를 확립하였습니다. 실험을 통해 trajectory 수준의 hard filtering과 token 수준의 soft reweighting이 상호 보완적으로 작동함을 확인했습니다. 이 연구는 대규모 언어 모델의 post-training 과정에서 compute 자원을 효과적으로 활용하는 새로운 기준을 제시하며, 향후 다양한 도메인 간 지식 전수 및 모델 최적화 분야에 실질적인 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] Trust Region On-Policy Distillation
Review 의 다른글
- 이전글 [논문리뷰] Evaluating Large Language Models in Dynamic Clinical Decision-Making with Standardized Patient Cases
- 현재글 : [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- 다음글 [논문리뷰] Functional Attention: From Pairwise Affinities to Functional Correspondences
댓글