[논문리뷰] Evaluating Large Language Models in Dynamic Clinical Decision-Making with Standardized Patient Cases
링크: 논문 PDF로 바로 열기
메타데이터
저자: Cheng Liang, Pengcheng Qiu, Ya Zhang, Yanfeng Wang, Chaoyi Wu, Weidi Xie, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MedSP1000: peer-reviewed 된 의료 교육 자료인 MedEdPORTAL을 기반으로 구축된, 임상 AI 에이전트 평가를 위한 대규모 인터랙티브 벤치마크.
- ACGME Competencies: 의학 교육에서 핵심적인 6가지 역량(Patient Care, Medical Knowledge, Systems-Based Practice, Interpersonal and Communication Skills, Practice-Based Learning and Improvement, Professionalism)으로, 모델 평가의 척도로 활용됨.
- Closed-loop Simulation: 임상 에이전트가 환자 에이전트 및 환경 컨트롤러와 상호작용하며 순차적으로 의사결정을 내리는 역동적인 평가 프레임워크.
- Rubric Completion Rate: 전문가가 작성한 교육 자료의 평가지표를 기반으로 모델이 시뮬레이션 과정에서 수행한 작업의 완수율을 측정한 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 정적인 단일 턴(Single-turn) 의학 벤치마크가 복잡하고 역동적인 실제 임상 환경을 충분히 반영하지 못한다는 한계를 해결하고자 한다. 현재의 LLM 평가 방식은 단편적인 질의응답에 치중되어 있어, 임상 현장에서 필수적인 정보 수집, 진단, 치료 계획 수정, 모니터링 등 연속적인 추론과 행위 능력을 평가하기 어렵다. [Figure 1]에서 볼 수 있듯이, 저자들은 실제 의료 교육에 활용되는 표준화된 환자(Standardized Patient, SP) 시나리오를 실행 가능한 형태로 변환하여 모델의 실제 임상 수행 능력을 다각도로 분석할 필요성을 강조한다.

Figure 1 — 벤치마크 구축 파이프라인과 데이터 소스 구조를 설명하는 핵심 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MedEdPORTAL의 1,073개 소스 문서를 기반으로 1,638개의 인터랙티브 시나리오와 24,602개의 세부 평가지표를 추출하는 자동화 파이프라인을 제안한다. [Figure 7]에 나타난 데이터 처리 파이프라인은 원본 문서를 4가지 역할별 패킷(scenario initialization, patient script, environment controller materials, scoring rubric)으로 구조화하여, 임상 에이전트가 환경과 상호작용할 수 있도록 설계되었다. 성능 평가 결과, 가장 뛰어난 성능을 보인 GPT-5.5조차 전체 Rubric completion rate가 60.4%에 그쳐, 일반적인 의료 지식 검증 벤치마크에서의 고성능이 실제 인터랙티브 임상 성능으로 직결되지 않음을 확인했다. [Table 1]에 따르면, 전문적인 의학 지식을 학습한 MedGemma와 Baichuan-M3는 40% 미만의 낮은 성적을 기록하며 일반 목적 모델들에 비해 뒤처지는 모습을 보였다. 특히 PBLI 역량의 완수율은 모든 모델에서 30%를 넘지 못해 모델들의 자기 성찰 및 반복적 학습 능력에 심각한 결함이 있음이 드러났다. [Figure 4]와 [Figure 5]는 다양한 임상 분과 및 맥락에서의 성능 차이를 보여주며, 복합적 통합 사고가 요구되는 분야일수록 모델의 성능이 저하되는 경향성을 입증했다.
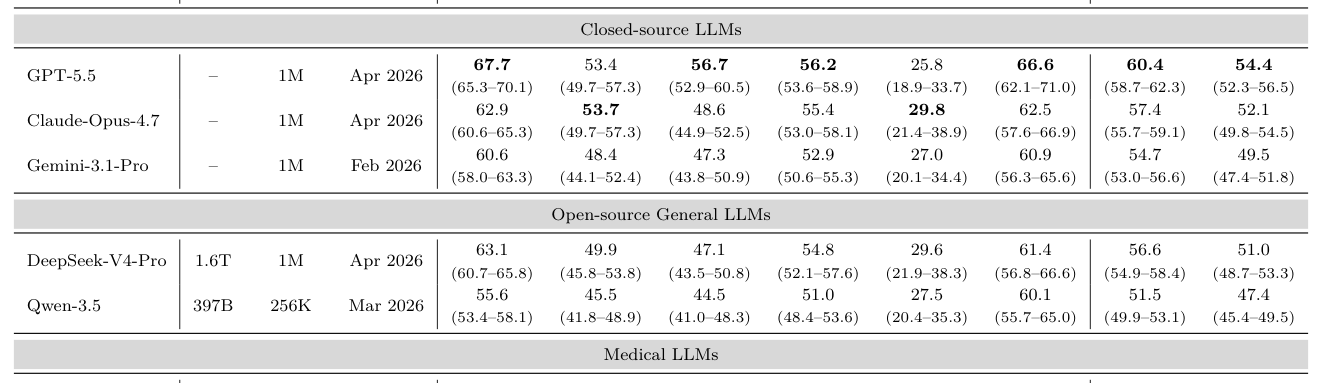
Table 1 — 다양한 모델별 성능 및 역량별 micro/macro 결과를 비교하는 핵심 결과표
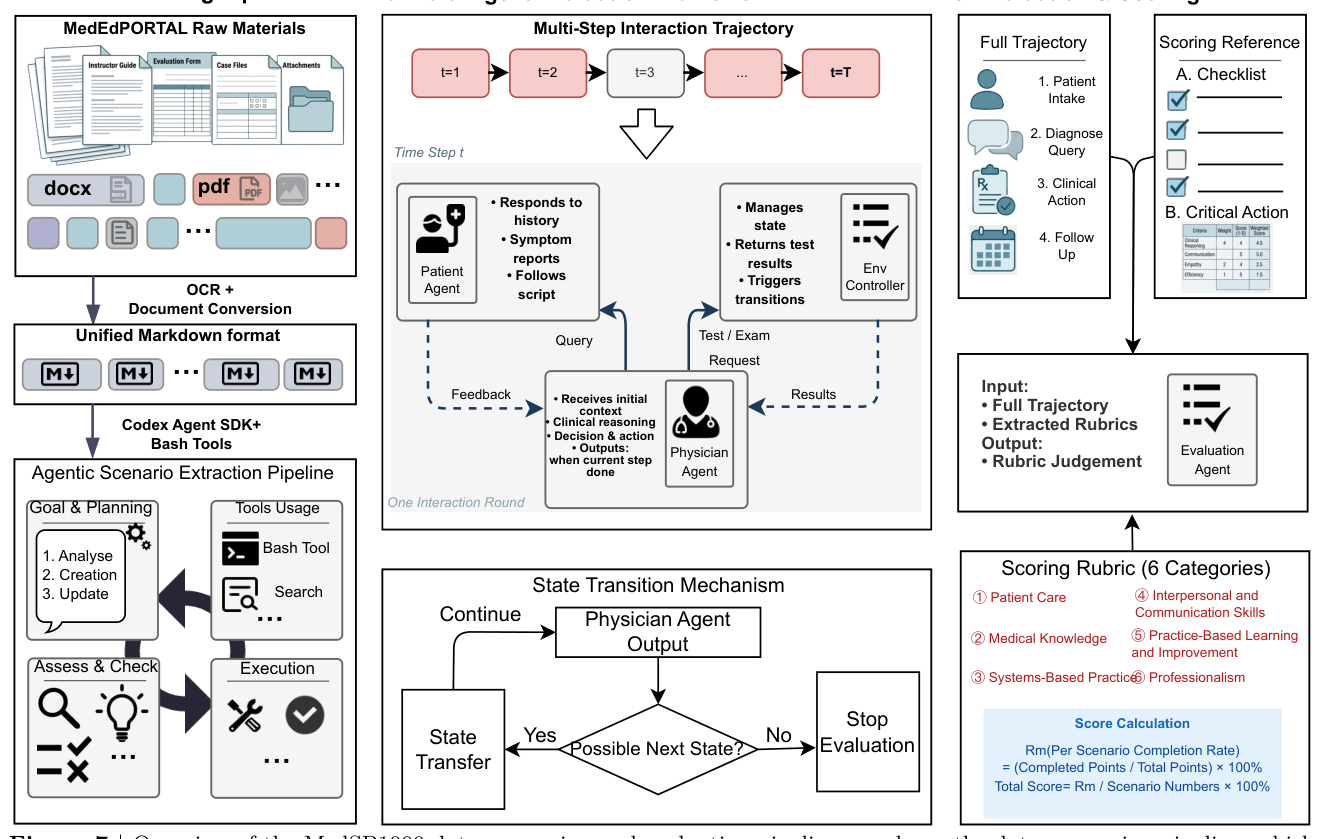
Figure 7 — 데이터 전처리부터 에이전트 간 인터랙티브 시뮬레이션 방식까지의 전체 프레임워크를 설명하는 핵심 다이어그램
4. Conclusion & Impact (결론 및 시사점)
본 연구는 현재의 최첨단 LLM들이 높은 의학적 지식을 보유하고 있음에도 불구하고, 역동적인 임상 환경에서 안전하게 임상 에이전트로 활동하기에는 신뢰성이 부족하다는 결론을 내린다. 또한 테스트 타임 컴퓨팅 확장 전략인 Best-of-N이나 MDT 방식이 전체적인 성능 향상에는 유의미한 도움을 주지 못하며, 오히려 과도한 자신감으로 인한 조기 종료 등의 새로운 실패 모드를 유발함을 규명했다. 이 벤치마크는 향후 의료용 LLM이 단순 지식 검색 단계를 넘어, 실제 임상 현장의 복잡성을 이해하고 긴 문맥을 추론할 수 있는 능력을 키우는 방향으로 발전해야 함을 시사한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
- [논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
- [논문리뷰] A2RBench: An Automatic Paradigm for Formally Verifiable Abstract Reasoning Benchmark Generation
- [논문리뷰] Xpertbench: Expert Level Tasks with Rubrics-Based Evaluation
- [논문리뷰] RubricBench: Aligning Model-Generated Rubrics with Human Standards
Review 의 다른글
- 이전글 [논문리뷰] Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
- 현재글 : [논문리뷰] Evaluating Large Language Models in Dynamic Clinical Decision-Making with Standardized Patient Cases
- 다음글 [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
댓글