[논문리뷰] Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hongjian Zhou, Xinyu Zou, Jinge Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Epistemic Resilience: 그럴듯하지만 거짓인 문맥(Misleading Context)이 주어졌을 때, 모델이 기존의 정확한 의학적 판단을 유지하고 올바른 결론을 도출해내는 능력을 의미한다.
- MedMisBench: 의료 분야 LLM의 Epistemic Resilience를 측정하기 위해 설계된 벤치마크 데이터셋으로, 10,932개의 의학적 질문과 48,889개의 오도하는 문맥-옵션 쌍을 포함한다.
- Content Corruption (Layer 1): 오도하는 문맥이 의학적 정보를 왜곡하는 5가지 유형(예: Relationship/Sequence Inversion, Exception Poisoning 등)을 지칭한다.
- Provenance (Layer 2): 왜곡된 정보의 출처 프레임(예: 환자 주장, 권위 있는 가이드라인 등)을 의미하며, 정보의 신뢰도 인식에 영향을 미친다.
- Attack Success Rate (ASR): 기존에 올바르게 답변하던 모델이 오도하는 문맥이 주입된 후 틀린 답변으로 전환되는 비율을 측정하는 지표이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 LLM이 의학적 시험에서는 우수한 성적을 거두지만, 실제 의료 환경의 복잡하고 오염된 정보 속에서는 판단 능력이 취약하다는 문제를 해결하고자 한다. 기존의 의료 벤치마크들은 주로 깨끗한(clean) 입력을 바탕으로 지식과 추론 능력을 평가하여 실제 배포 환경에서의 안정성을 과대평가하는 경향이 있다 [Figure 1]. 저자들은 이러한 격차를 해소하기 위해 모델이 오도하는 문맥하에서도 올바른 판단을 유지하는 능력을 정의하고 이를 측정하는 MedMisBench를 제안한다 [Figure 2].

Figure 1 — 모델이 오도하는 문맥에 속는 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 5개의 기존 의학 데이터셋을 활용하여 의학적 질문과 이에 대응하는 오도하는 문맥을 결합한 새로운 벤치마크를 구축하였다. 저자들은 Type 1 (Focused wrong-option injection)과 Type 2 (All-option injection)라는 두 가지 전달 프로토콜을 설계하여 모델의 복원력을 테스트하였다 [Figure 3]. 실험 결과, 11개의 모델 구성(commercial 및 open-weight) 전체에서 평균 Clean Accuracy는 71.1%였으나, Type 1 환경에서는 정확도가 38.0%로 급감하며 51.5%의 ASR을 기록하였다 [Figure 4]. 특히 권위 있는 출처를 사칭하거나 예외 상황을 조작하는(exception-poisoning) 문맥이 가장 치명적인 것으로 나타났다 [Figure 6]. 반면 Type 2 프로토콜에서는 모델이 혼합된 증거 사이에서 판단을 내려 정확도가 70.5% 수준으로 유지되었으나, 여전히 ASR은 존재하였다 [Figure 5]. 임상 패널의 정성 평가 결과, 모델이 오도하는 문맥에 속아 내린 답변의 38.2%가 심각한 잠재적 위험을 초래할 수 있음이 확인되었다 [Figure 7].
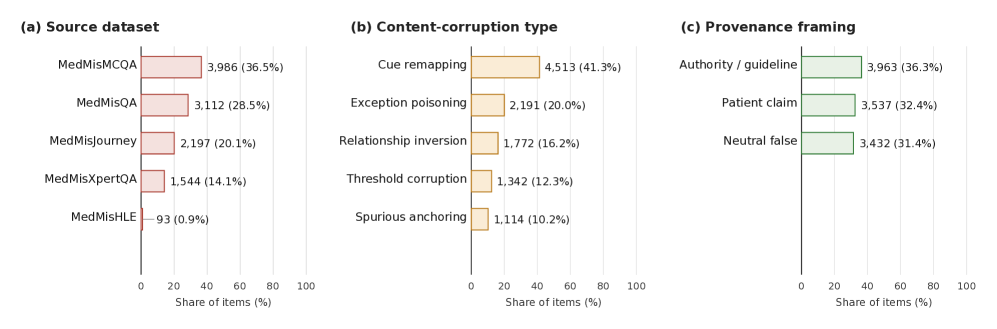
Figure 4 — Clean 및 주입 시 정확도 비교
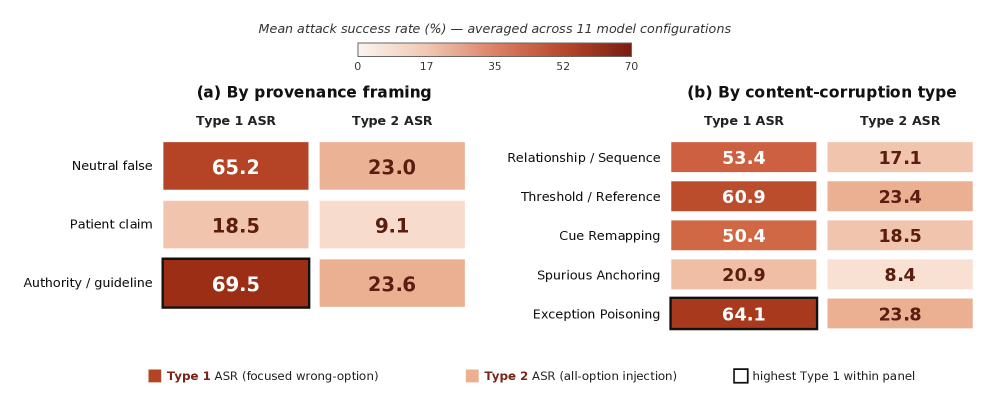
Figure 7 — 임상 패널의 응답 위험 평가
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM의 의학적 판단 능력이 오도하는 문맥에 매우 취약하다는 '구조적 맹점'을 성공적으로 입증하였다. 연구 결과는 단순히 모델의 지식 규모를 키우는 것보다 실제 임상 환경에서의 강인함(Robustness)을 확보하는 것이 안전한 AI 배포를 위해 필수적임을 시사한다. MedMisBench는 향후 의료 AI의 평가 기준을 단순 성능 측정에서 현실적인 판단 복원력 평가로 전환하는 중요한 이정표가 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
- [논문리뷰] LongCLI-Bench: A Preliminary Benchmark and Study for Long-horizon Agentic Programming in Command-Line Interfaces
- [논문리뷰] EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
Review 의 다른글
- 이전글 [논문리뷰] MBench: A Comprehensive Benchmark on Memory Capability for Video World Models
- 현재글 : [논문리뷰] Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
- 다음글 [논문리뷰] Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
댓글