[논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
링크: 논문 PDF로 바로 열기
메타데이터
저자: Peixian Zhou, Yuxu Chen, Chaorui Zhang, Wei Han, Bo Bai, Xueyan Niu
1. Key Terms & Definitions (핵심 용어 및 정의)
- ChLogic: 논문에서 제안하는 English–Chinese 정렬 벤치마크로, 동일한 논리적 구조를 다양한 중국어 표현(Surface Realization)으로 변환하여 모델의 추론 강건성(Robustness)을 평가함.
- Surface Realization: 고정된 논리적 템플릿(Logical Template)이 자연어(영어 또는 중국어)로 구현되는 방식. 본 논문에서는 표준, 자연어, 구어체, 수사 의문문, 변형된 문장 등 5가지 중국어 변형을 사용함.
- Back-translation Probes: 중국어 표현을 다시 영어로 번역하여 모델이 추론하는 과정을 테스트하는 진단 기법으로, 모델의 오류가 형식 논리(Formal Inference) 문제인지 혹은 중국어 표현 해석(Surface-to-Logical-Form Normalization)의 문제인지를 구분함.
- Logical Template Families: 논리적 추론 능력을 측정하기 위한 체계적인 범주로, 명제 논리(Propositional Logic), 술어 논리(Predicate Logic), 다단계 추론(Multi-step Rule Chains) 등을 포함함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 영어 기반 논리 벤치마크에서는 우수한 성능을 보이지만, 중국어와 같이 언어적/실용적 변동성이 큰 환경에서도 이러한 논리적 추론 성능이 유지되는지 의문을 제기한다. 기존 벤치마크는 주로 영어 중심적이거나 단순한 구조에 치우쳐 있어, 중국어의 생략, 반어법, 관용구, 모호한 양화사 등이 포함된 복잡한 문맥에서의 논리적 구조 복원력을 정확히 측정하지 못하는 한계가 있다 [Figure 1]. 저자들은 논리적 구조가 동일함에도 불구하고 표면적인 언어 표현만 다를 때 모델의 판단이 어떻게 변하는지 분석하고자 한다.
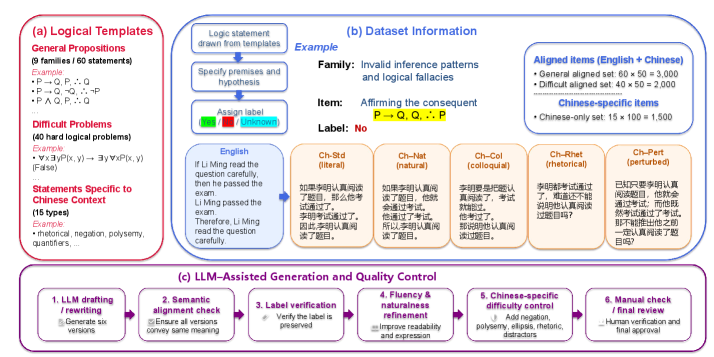
Figure 1 — ChLogic 벤치마크 구축 워크플로우
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 60개의 일반 명제(General Propositions)와 40개의 난해한 문제(Difficult Problems)를 포함한 3개의 데이터셋으로 구성된 ChLogic을 제안하며, 각 논리적 템플릿을 영어와 5가지 중국어 변형으로 정렬하여 모델의 추론 일관성을 테스트한다 [Figure 1]. Qwen3, Ministral, GLM-5.1 모델을 대상으로 실험한 결과, 모든 모델에서 영어 대비 중국어 추론 성능이 저하되는 견고한 격차(English–Chinese performance gap)가 관찰되었다 [Table 2]. 예를 들어, GLM-5.1은 일반 영어 문제에서 98.30%의 정확도를 보였으나, 수사 의문문 형태의 중국어에서는 78.89%로 급격히 하락했다 [Figure 2]. Back-translation을 통해 분석한 결과, 일반적인 문제에서는 영어로 역번역 시 성능이 개선되나, 난해한 문제에서는 일부 모델(예: Qwen3-32B)의 경우 성능이 오히려 하락하는 혼재된 양상을 보였다 [Table 3]. 이는 중국어 표면 구현과 번역 과정에서의 정보 왜곡이 모델의 논리적 판단에 복합적으로 작용함을 시사한다.
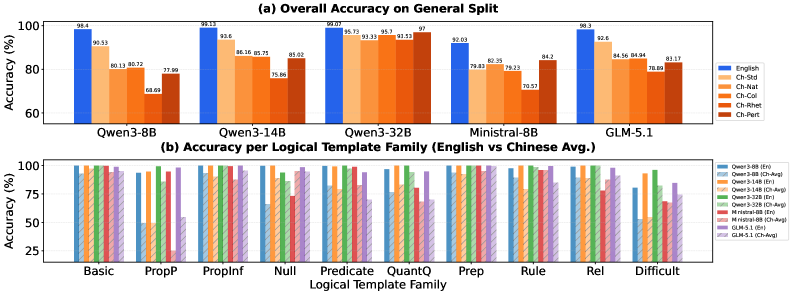
Figure 2 — ChLogic 주요 모델 정확도 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 ChLogic을 통해 강력한 영어 논리 추론 능력이 반드시 robust한 다국어 논리 이해를 보장하지는 않음을 실증적으로 규명했다. 실험 결과, 모델의 크기(Scaling)를 키워도 중국어 특유의 표면적 난제에 대한 추론 오류를 완전히 제거하지 못한다는 점을 확인하였다. 이 연구는 향후 LLM의 다국어 정렬 및 추론 강건성 평가를 위한 중요한 diagnostic 벤치마크로서 기여할 것으로 기대된다. 또한, 단순 정확도를 넘어 언어별/형식별 오류 패턴을 분석함으로써 LLM 개발 시 모델의 인지적 편향과 표면적 해석 실패를 방지하는 방향성을 제시하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] Measuring Epistemic Resilience of LLMs Under Misleading Medical Context
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild
- [논문리뷰] Revealing Algorithmic Deductive Circuits for Logical Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Beyond Monolingual Deep Research: Evaluating Agents and Retrievers with Cross-Lingual BrowseComp-Plus
- 현재글 : [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
- 다음글 [논문리뷰] Dr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
댓글