[논문리뷰] Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
링크: 논문 PDF로 바로 열기
메타데이터
저자: Qingcheng Zeng, Yuheng Lu, Zeqi Zhou, Heli Qi, Puxuan Yu, Fuheng Zhao, Hitomi Yanaka, Weihao Xuan, Naoto Yokoya, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Code-Switching (CS): 동일한 대화나 검색 쿼리 내에서 두 개 이상의 언어가 혼용되는 언어적 현상.
- CSR-L (Code-Switching Retrieval benchmark-Lite): 자연스러운 혼용 언어 쿼리를 포함하고 통계적, 밀집, 교차 인코더, 지연 상호작용 검색 방식의 성능을 평가하기 위해 저자들이 구축한 인간 주석 벤치마크.
- CS-MTEB: 11개의 다양한 작업과 7개의 작업 유형을 포괄하며 코드 스위칭이 임베딩 모델에 미치는 영향을 측정하기 위해 제안된 확장 벤치마크.
- Retrieval-Augmented Generation (RAG): 외부 정보를 검색하여 생성 모델의 답변을 보강하는 시스템 아키텍처.
- Late-Interaction Architecture: ColBERT와 같이 쿼리와 문서의 토큰 간 상호작용을 마지막 단계에서 수행하여 효율성과 효과를 동시에 확보하는 검색 프레임워크.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 정보 검색(IR) 시스템이 다국어 환경의 필수 요소인 코드 스위칭 상황에서 체계적인 평가를 받지 못하고 있다는 문제점을 제기한다. 기존의 검색 시스템은 대부분 단일 언어(monolingual) 환경에 최적화되어 있어, 실생활의 자연스러운 언어 혼용 쿼리가 발생할 경우 성능이 크게 저하되는 견고성(robustness) 결함이 존재한다 [Figure 1]. 이러한 코드 스위칭은 글로벌 소통의 핵심임에도 불구하고, 기존 검색 모델들은 이러한 혼용 데이터를 처리할 때 단일 언어 대비 상당한 성능 손실을 겪으며 임베딩 공간상의 정렬 문제를 노출한다. 본 연구는 이러한 한계를 극복하기 위해 다각적인 분석 프레임워크를 제안하고, 현존하는 검색 기법들의 한계를 규명하고자 한다.
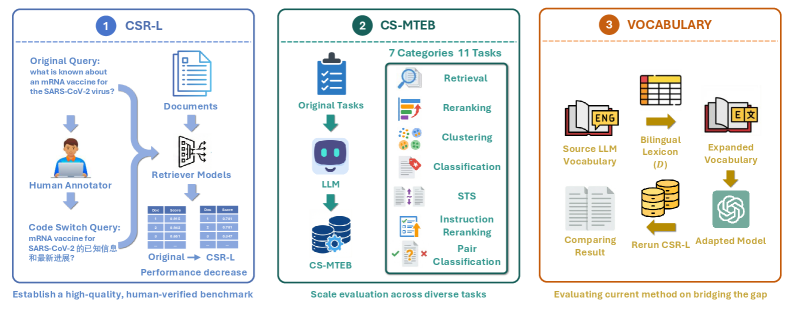
Figure 1 — 코드 스위칭 IR 연구 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 코드 스위칭 검색 시스템의 성능 평가를 위해 인간이 주석을 단 CSR-L 벤치마크를 구축하고, 11개 작업을 포함하는 CS-MTEB를 통해 그 영향력을 정량적으로 분석하였다. 실험 결과, 쿼리 내 코드 스위칭만으로도 강력한 다국어 모델을 포함한 대부분의 시스템에서 유의미한 성능 저하가 발생함이 확인되었다. 구체적으로 CS-MTEB 벤치마크에서 임베딩 모델의 성능은 단일 언어 대비 최대 27%까지 하락하는 결과를 보였다 [Table 3]. 임베딩 공간 분석 결과, 영어 중심 모델은 코드 스위칭 쿼리 시 원본 데이터와 임베딩 공간이 분리되는 현상을 보인 반면, 다국어 모델은 상대적으로 견고했으나 여전히 근본적인 의미적 정렬 문제는 해소하지 못했다 [Figure 2]. 또한, lexicon-based vocabulary expansion 기법은 일부 성능 향상을 도출하였으나, 단일 언어 성능을 완전히 회복하지 못한다는 정량적 지표를 통해 코드 스위칭의 난이도를 입증하였다 [Table 4].
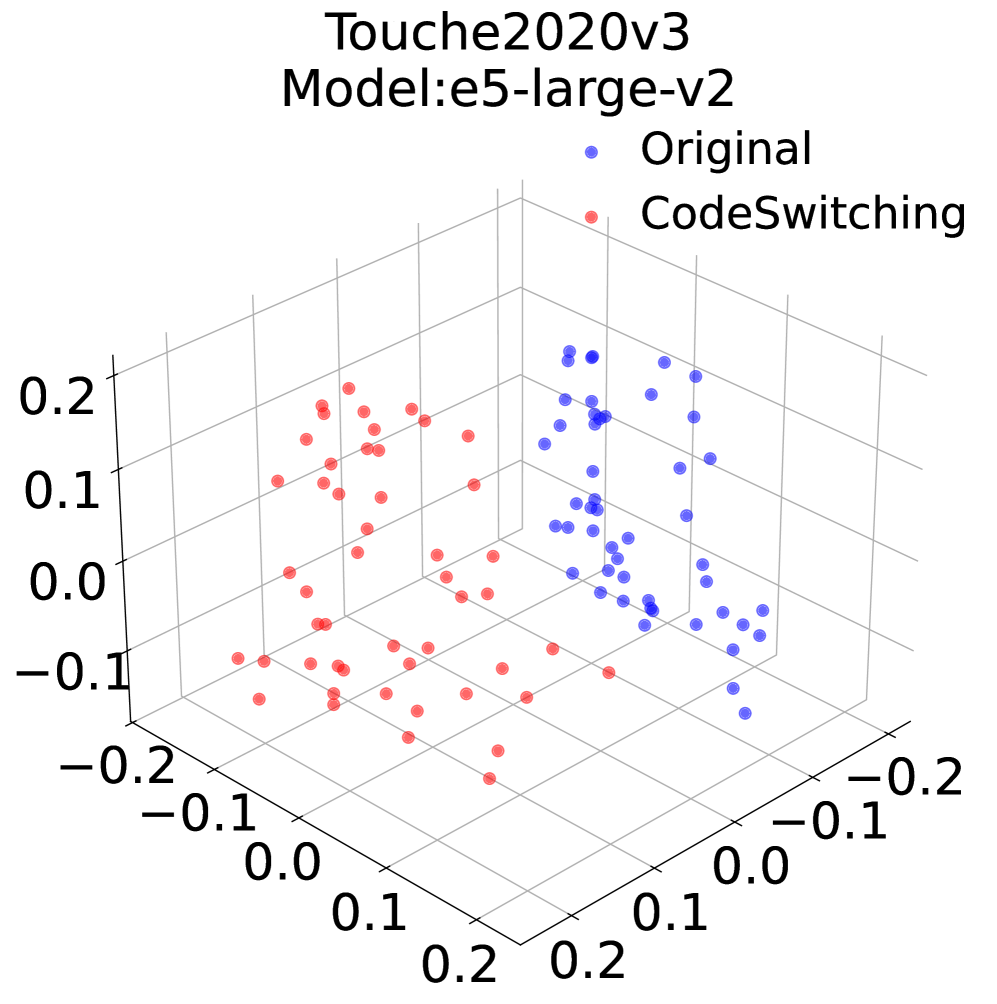
Figure 2 — 임베딩 공간 시각화(e5/Qwen)
4. Conclusion & Impact (결론 및 시사점)
본 논문은 코드 스위칭이 현대 검색 시스템에서 피할 수 없는 견고성 병목 현상임을 규명하며, 이는 단순한 어휘적 패치가 아닌 구조적인 접근이 필요한 핵심 도전 과제임을 결론지었다. 연구 결과는 단순한 임베딩 모델의 규모 확장이나 다국어 사전 훈련만으로는 혼용 언어 쿼리의 의미적 불일치를 완전히 해결할 수 없음을 시사한다. 따라서 향후 학계와 산업계는 코드 스위칭 데이터를 별도의 독립적인 언어 양식으로 취급하여 훈련 데이터에 반영하는 전문적인 최적화 방향으로 나아가야 한다. 본 벤치마크와 데이터셋은 향후 혼용 언어 검색 시스템의 발전을 위한 중요한 토대를 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Legal RAG Bench: an end-to-end benchmark for legal RAG
- [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] CiteAudit: You Cited It, But Did You Read It? A Benchmark for Verifying Scientific References in the LLM Era
- [논문리뷰] DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
Review 의 다른글
- 이전글 [논문리뷰] CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
- 현재글 : [논문리뷰] Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
- 다음글 [논문리뷰] Contrastive Attribution in the Wild: An Interpretability Analysis of LLM Failures on Realistic Benchmarks
댓글