[논문리뷰] Contrastive Attribution in the Wild: An Interpretability Analysis of LLM Failures on Realistic Benchmarks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rongyuan Tan, Jue Zhang, Zhuozhao Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Contrastive Attribution: 모델이 특정 오류 토큰을 더 올바른 대안 토큰보다 선호하는 이유를 설명하기 위해, 두 토큰 간의 logit 차이를 입력 토큰 및 내부 상태에 귀속시키는 방법론입니다.
- AttnLRP (Attention-aware Layer-wise Relevance Propagation): Transformer 모델의 복잡한 비선형 구조를 고려하여, 예측에 대한 기여도를 입력 계층까지 역전파(backpropagation)하는 Faithful한 interpretability 기법입니다.
- Attribution Graph: 신경망 내부의 hidden states(노드)와 이들 간의 relevance 흐름(엣지)을 표현한 구조로, 모델의 의사결정 경로를 시각화합니다.
- Batch-Packed Multi-Target Backpropagation: GPU 효율성을 극대화하기 위해 배치 차원을 활용하여 여러 attribution target을 단일 backward pass 내에서 동시에 처리하는 계산 가속 기술입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 interpretability 도구들이 실제 벤치마크상의 LLM 오류를 분석하는 데 한계가 있다는 점을 지적하며, 이를 해결하기 위한 실용적인 분석 프레임워크를 제안합니다. 기존의 많은 연구는 인위적인 toy setting이나 짧은 입력에 국한되어 있어, 실제 실무 환경에서 발생하는 장문 컨텍스트나 복잡한 벤치마크 오류를 체계적으로 디버깅하는 데 어려움이 있습니다. 특히 단순한 행동 분석(behavioral analysis)만으로는 오류의 결과는 확인할 수 있어도 "왜(why)" 오류가 발생했는지에 대한 내부 메커니즘을 밝혀내기 어렵습니다. 따라서 본 연구는 이러한 gap을 메우고, interpretability 분석이 실제 LLM failure case 분석에 실질적인 가치를 제공할 수 있는지 탐구합니다 [Figure 1].
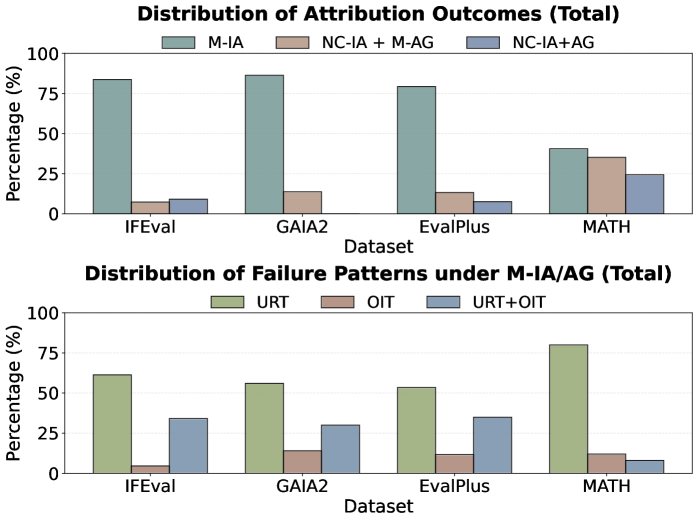
Figure 1 — 벤치마크별 귀속 결과 및 오류 패턴 분포
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 LLM의 오류를 오류 토큰과 올바른 대안 토큰 사이의 logit 차이를 분석하는 Contrastive Attribution 문제로 재정의하고, 이를 구현하기 위해 AttnLRP를 확장한 효율적인 attribution graph 건설 방법을 도입했습니다. 특히 긴 입력 문맥에서도 확장 가능한 분석을 위해 배치 단위의 역전파 기법을 활용하여 연산 효율성을 높였습니다.
주요 실험 결과는 다음과 같습니다:
- Failure Patterns: 다양한 벤치마크 실험 결과, Underweight Relevant Tokens (URT)가 주요 오류 원인으로 나타났으며, 모델이 불필요한 토큰을 과도하게 강조하는 Overweight Irrelevant Tokens (OIT) 현상도 공존함을 확인했습니다 [Figure 2].
- Attribution Graphs: 입력 단계에서 분석 불가능했던(NC-IA) 오류 케이스들을 Attribution Graph 분석을 통해 내부 레이어 간의 relevance 흐름을 시각화함으로써 결정적인 기여 경로를 식별할 수 있었습니다 [Figure 3].
- Scaling & Training Dynamics: 모델 사이즈의 스케일링이나 학습 과정(SFT/DPO)에서 나타나는 성능 향상이 단순히 표면적인 결과가 아니라, 중요 토큰에 대한 relevance 점수가 체계적으로 개선되는 Interpretability shift를 동반함을 입증했습니다 [Figure 4, 5, 6].

Figure 2 — 입력 귀속 히트맵 예시
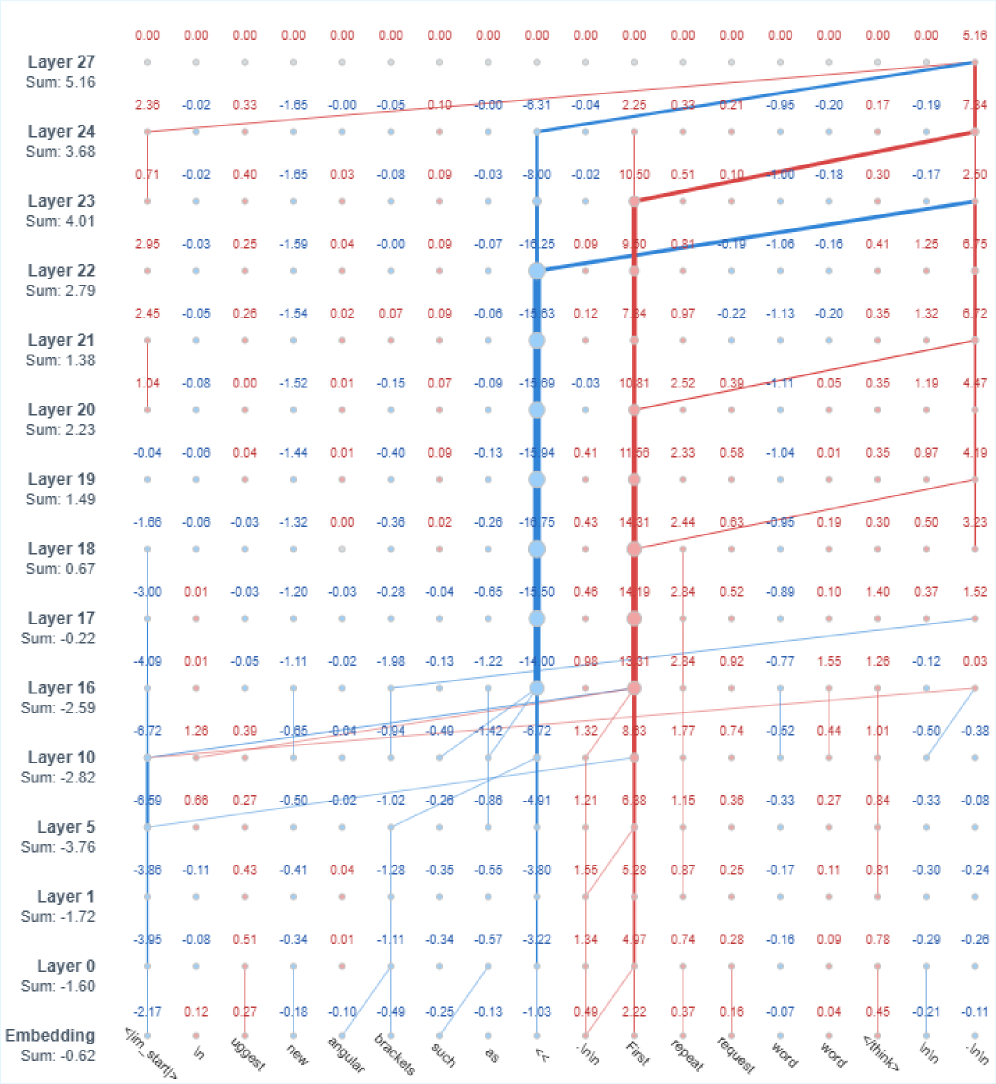
Figure 3 — 내부 상태 귀속 그래프 예시
4. Conclusion & Impact (결론 및 시사점)
본 논문은 대규모 언어 모델의 오류 분석을 위해 Contrastive Attribution 기반의 실용적이고 확장 가능한 interpretability 도구를 성공적으로 제시했습니다. 이 연구는 모델의 스케일링이나 학습이 블랙박스 형태의 성능 향상이 아닌, 신뢰할 수 있는 내부 메커니즘의 개선을 수반함을 데이터로 입증했다는 점에서 중요한 학술적 의미를 갖습니다. 산업계 및 학계 연구자들은 본 프레임워크를 통해 모델 오류를 더 깊이 있게 디버깅하고, 이를 기반으로 Targeted prompt tuning이나 더 효과적인 Alignment training 전략을 수립할 수 있는 실용적 토대를 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] CIPER: A Unified Framework for Cross-view Image-retrieval and Pose-estimation
- [논문리뷰] Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
- [논문리뷰] Confidence-Adaptive SwiGLU for Mixture-of-Experts
Review 의 다른글
- 이전글 [논문리뷰] Code-Switching Information Retrieval: Benchmarks, Analysis, and the Limits of Current Retrievers
- 현재글 : [논문리뷰] Contrastive Attribution in the Wild: An Interpretability Analysis of LLM Failures on Realistic Benchmarks
- 다음글 [논문리뷰] Dual-View Training for Instruction-Following Information Retrieval
댓글