[논문리뷰] Personal AI Agent for Camera Roll VQA
링크: 논문 PDF로 바로 열기
메타데이터
저자: Thao Nguyen, Krishna Kumar Singh, Donghyun Kim, Yong Jae Lee, Yuheng Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- camroll dataset: 사용자 개인의 기기에서 수집된 31,476개의 이미지와 2,500개의 Q&A 쌍으로 구성된 데이터셋으로, 개인화된 시각적 컨텍스트와 장기적 기억을 포함함.
- Hierarchical Personal Memory: Raw pixels(이미지), Image captions(이미지 정보), Event summaries(이벤트 요약)의 3단계 계층 구조를 통해 방대한 개인 사진 데이터를 효율적으로 탐색하는 아키텍처.
- camroll-agent:
ReAct기반의 대화형 에이전트로, 계층적 메모리를 탐색하기 위한 최적화된 도구(Tool) 세트를 사용하여 사용자 개인의 사진 데이터 내에서 시각적 추론을 수행함. - View/Get/Search Tools: 메모리 접근 깊이와 retrieval paradigm에 따라 구분된 도구들로, 효율적인 토큰 소비를 위해 필요한 경우에만 Raw pixel을 해석하도록 설계됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 사용자 개인의 Camera Roll 전체를 대상으로 대화형 AI가 사진을 검색하고 질의에 응답하는 VQA 설정에서의 한계를 해결하고자 한다. 기존의 MLLM 기반 방식은 수천 장의 사진을 처리할 때 context window를 초과하거나, 이미지 압축 과정에서 심각한 정보 손실을 겪으며, Retrieval-Augmented Generation(RAG) 방식 역시 개인화된 컨텍스트를 제대로 활용하지 못한다 [Figure 1]. 또한, 단순히 이미지를 텍스트 캡션으로 변환하는 기존의 접근은 일상적이고 중복된 데이터가 많은 개인 사진 데이터에서 고수준의 추론을 수행하는 데 부족함이 많다.

Figure 1 — 개인 Camera Roll VQA 설정
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Raw pixels부터 Event summaries까지 추상화하는 Hierarchical Personal Memory를 구축하여 시각적 정보를 계층적으로 연결한다 [Figure 3]. camroll-agent는 이 메모리 구조를 기반으로 상황에 맞는 도구 호출을 수행하며, search, grep, list를 통해 후보를 좁히고 get, view를 통해 정밀하게 검증한다. 실험 결과, camroll-agent는 Gemini-2.5-Flash 기반에서 Free-form 응답 Judge 점수 4.11을 기록하며, ClaudeCode(3.77) 및 기존 메모리 기법인 Mem0(2.68) 대비 우수한 성능을 입증했다 [Table 3]. 특히, 모든 이미지를 직접 입력하는 방식이 750k 토큰을 소모하는 반면, 제안 기법은 약 3.2k 토큰만을 소모하여 계산 효율성 측면에서 압도적인 효율을 보여주었다.
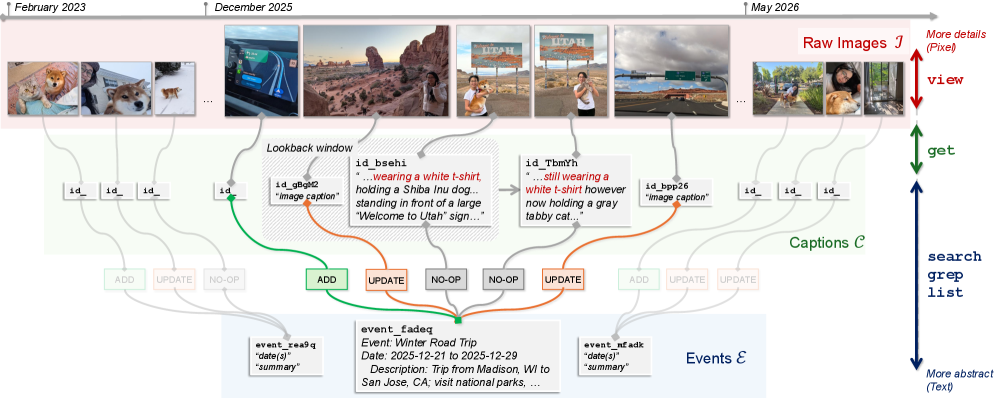
Figure 3 — 계층적 메모리 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 개인화된 시각적 기억이 일반적인 장기 텍스트 메모리와는 근본적으로 다른 접근 방식을 요구함을 규명하고, camroll-agent라는 효과적인 해결책을 제시하였다. 이 연구는 대규모 개인 데이터셋 내에서 에이전트가 안전하고 효율적으로 작동할 수 있는 기반을 마련하였으며, 향후 개인화된 일관된 스토리텔링이나 고도의 개인 맞춤형 비서 개발에 중요한 지침을 제공한다. 학계와 산업계 모두에 개인 데이터 관리와 멀티모달 추론 결합의 방향성을 제시했다는 점에서 그 의의가 크다.
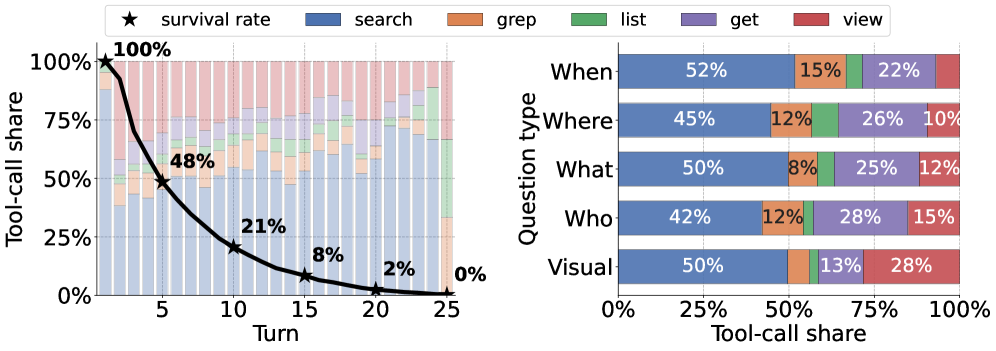
Figure 4 — 에이전트의 도구 사용 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
- [논문리뷰] MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
- [논문리뷰] TreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
- [논문리뷰] MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
- [논문리뷰] Benchmark Everything Everywhere All at Once
Review 의 다른글
- 이전글 [논문리뷰] OPRD: On-Policy Representation Distillation
- 현재글 : [논문리뷰] Personal AI Agent for Camera Roll VQA
- 다음글 [논문리뷰] Quality-Guided Semi-Supervised Learning for Medical Image Segmentation
댓글