[논문리뷰] Multimodal Music Recommendation System using LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Srikar Prabhas Kandagatla, Sreehitha R. Narayana, Chandana Magapu, Swetha Mohan, Shamanth Kuthpadi, Hongjie Chen, Ryan A. Rossi, Franck Dernoncourt, Nesreen Ahmed
1. Key Terms & Definitions (핵심 용어 및 정의)
- MGPHot: 음악의 가사, 보컬, 화음, 리듬, 악기 구성, 음향, 작곡 등 58가지 음악적 속성을 정의한 주석 스키마입니다.
- E4SRec: LLM의 시퀀셜 추론 능력을 활용하여 음악 추천을 수행하는 프레임워크로, 본 논문에서는 이를 확장하여 멀티모달 정보를 통합합니다.
- Completion Ratio: 사용자의 실제 청취 시간과 전체 곡 길이를 비교한 비율로, 단순 상호작용 기록보다 정교한 사용자 선호도를 나타내는 지표입니다.
- Multimodal Fusion: 오디오 임베딩, 가사 임베딩, 그리고 LLM이 생성한 시맨틱 메타데이터를 통합하여 더 풍부한 아이템 표현(Item Representation)을 생성하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 음악 추천 시스템이 곡을 독립적인 ID 토큰으로만 취급하여 시맨틱(Semantic) 및 어쿠스틱(Acoustic) 콘텐츠 정보를 간과하는 문제를 해결합니다. 기존의 ID 기반 모델은 상호작용이 부족한 Cold-start 환경에서 성능이 저하되는 한계가 있습니다. 또한, 기존 LLM 기반 추천 연구들은 실제 곡의 콘텐츠에 대한 깊은 Grounding 없이 약한 텍스트 프록시(Textual Proxy)에 의존하고 있습니다. 따라서 본 연구는 오디오, 가사, 시맨틱 메타데이터, 그리고 사용자 참여 신호를 결합한 통합적 멀티모달 프레임워크를 제안합니다 [Figure 1].
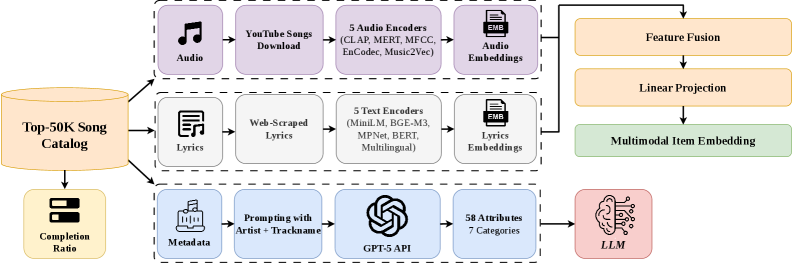
Figure 1 — 멀티모달 특징 추출 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LastFM-1K 데이터셋을 바탕으로 오디오 임베딩, 가사 임베딩, MGPHot 기반의 LLM 생성 메타데이터, 그리고 Completion Ratio를 포함하는 멀티모달 데이터 파이프라인을 구축하였습니다 [Figure 3]. 이 시스템은 SASRec, BERT4Rec, GRU4Rec 등 다양한 시퀀셜 인코더와 LLaMa-3-70B, Qwen2.5-7B-Instruct 등 대형 LLM 백본을 결합하여 추천 성능을 평가합니다. 실험 결과, 콘텐츠 기반 기능을 통합한 모델은 ID 전용 베이스라인 대비 Recall에서 최대 95%, NDCG에서 최대 79%의 성능 향상을 기록했습니다 [Table 5]. 특히 정량적 지표에서 멀티모달 데이터의 전략적 통합이 데이터 희소성을 완화하고 차별화된 추천 성능을 보임을 증명했습니다 [Figure 4].

Figure 3 — 멀티모달 추천 모델 아키텍처

Figure 4 — 데이터 전처리 과정
4. Conclusion & Impact (결론 및 시사점)
본 연구는 멀티모달 정보를 시퀀셜 음악 추천 시스템에 통합하는 표준적인 프레임워크를 정립하였습니다. 제안된 방법론은 단순한 ID 기반 추천의 한계를 넘어 오디오와 가사의 시맨틱 정보를 효과적으로 활용할 수 있음을 보여줍니다. 이번 연구에서 공개한 멀티모달 벤치마크는 향후 학계와 산업계에서 LLM을 활용한 고도화된 콘텐츠 기반 추천 시스템 연구의 중요한 기반이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] ARC-Chapter: Structuring Hour-Long Videos into Navigable Chapters and Hierarchical Summaries
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] OpenVision 2: A Family of Generative Pretrained Visual Encoders for Multimodal Learning
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
Review 의 다른글
- 이전글 [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- 현재글 : [논문리뷰] Multimodal Music Recommendation System using LLMs
- 다음글 [논문리뷰] OPRD: On-Policy Representation Distillation
댓글