[논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziyan Liu, Zhezheng Hao, Yeqiu Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Belief Entropy: 모델이 현재의 memory 상태를 바탕으로 latent task state에 대해 가지는 불확실성을 측정하는 지표로, response uncertainty를 통해 간접적으로 추정합니다.
- MMPO (Metacognitive Memory Policy Optimization): Belief Entropy를 활용하여 중간 memory 상태에 dense supervision을 제공함으로써, long-horizon에서의 belief deviation을 줄이는 최적화 프레임워크입니다.
- Summary-Induced Belief: 전체 interaction history 대신 압축된 memory $m_t$에 기반하여 모델이 추론하는 내재적 확률 분포 $P(s_t|m_t)$를 의미합니다.
- POMDP (Partially Observable Markov Decision Process): agent가 직접 관찰할 수 없는 latent task state를 추론하며 행동을 결정해야 하는 환경을 모델링하는 수학적 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 메모리 기반 LLM agent가 장기적인(long-horizon) 과업 수행 시 발생하는 성능 저하 문제를 해결하기 위해 연구되었습니다. 기존 연구들은 주로 final outcome에 기반한 sparse한 보상을 사용하여 memory 정책을 학습시켰으나, 이는 intermediate memory의 품질 저하를 국소화하지 못하는 한계가 있습니다 [Figure 1]. 결과적으로 재귀적 요약(recursive summarization) 과정에서 의미적 노이즈가 누적되어 belief deviation이 발생하고, 이는 최종적으로 장기 추론 능력의 붕괴로 이어집니다 [Figure 2]. 따라서 단순한 결과 기반 학습을 넘어, 중간 단계에서 memory가 task state를 얼마나 명확하게 유지하는지 측정하고 최적화할 수 있는 새로운 기준이 필요합니다.
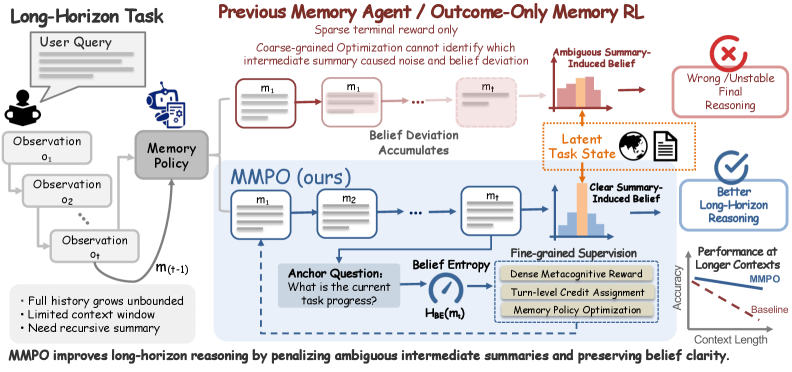
Figure 1 — MMPO의 개요 및 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 metacognitive probe를 통해 모델 내부의 상태 불확실성을 측정하는 Belief Entropy를 제안하고, 이를 통해 MMPO를 구축합니다. MMPO는 앵커 질문(anchor question)을 사용하여 모델이 현재 task 진행 상황과 부족한 정보를 스스로 진단하게 하며, 여기서 계산된 entropy를 기반으로 중간 memory 상태에 dense reward를 할당합니다 [Figure 4]. 제안된 MMPO는 RULER-HotpotQA 벤치마크에서 기존 RL-MemAgent 대비 224K에서 3.5M context length 구간에서 평균 +3.14% 이상의 성능 향상을 보였습니다 [Table 1]. 또한, MMPO는 multi-objective QA 및 WebShop 환경에서도 기존 방식 대비 일관된 우위를 점하며, 특히 Belief Entropy 감소와 과업 정확도 사이의 강한 음의 상관관계($r = -0.684$)를 입증했습니다 [Figure 3, Table 2, Table 3].
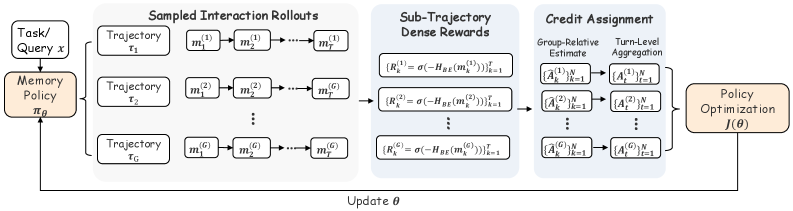
Figure 4 — MMPO 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM agent의 long-horizon 추론 성능 저하가 memory의 정보적 명확성 결여에서 기인함을 밝히고, Belief Entropy라는 메타인지적 도구를 통해 이를 해결하였습니다. MMPO는 단순히 결과에만 의존하던 기존의 강화학습 방식에서 벗어나, memory 최적화의 중간 과정에 대한 dense한 감독(supervision)을 가능하게 함으로써 더 안정적인 에이전트 구축의 토대를 마련했습니다. 이러한 접근 방식은 AGI를 향한 에이전트 아키텍처 설계와 대규모 context 환경에서의 정보 관리 전략에 중요한 학술적·기술적 시사점을 제공합니다.
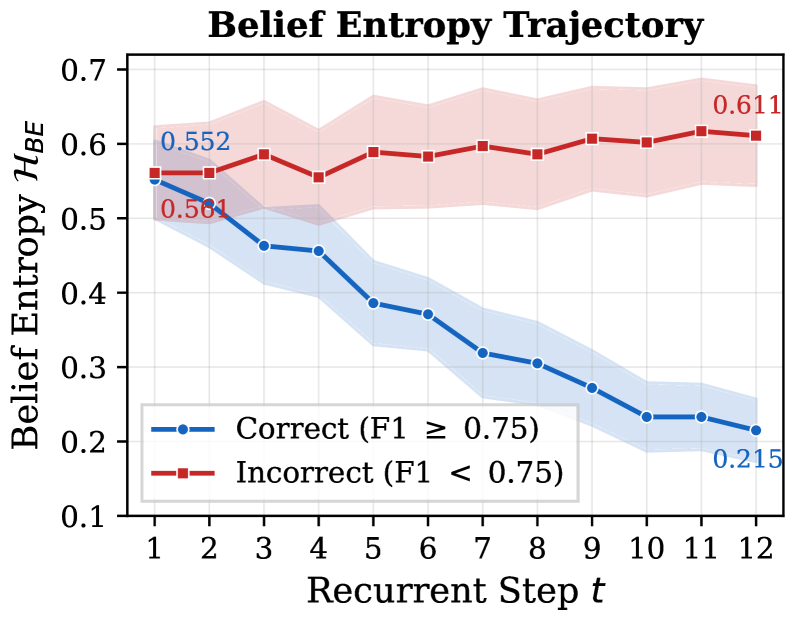
Figure 3 — Belief Entropy의 실증적 검증
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- [논문리뷰] ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
- [논문리뷰] A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
- 현재글 : [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- 다음글 [논문리뷰] Multimodal Music Recommendation System using LLMs
댓글