[논문리뷰] MemTrain: Self-Supervised Context Memory Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziheng Li, Xingrun Xing, Haoqing Wang, Zhi-Hong Deng, Yehui Tang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Context Memory: LLM 에이전트가 전체 입력 기록을 기억하는 대신, 각 턴(turn)마다 정보를 압축하여 고정된 크기의 상태(state)로 유지하는 기법입니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 메모리 훈련 및 에이전트 최적화에 사용하는 강화학습 알고리즘으로, 여러 샘플링된 trajectory 간의 상대적 보상을 통해 정책을 업데이트합니다.
- End-to-End Masked Reconstruction: Wikipedia 데이터에서 엔티티를 마스킹한 후, 여러 단계의 메모리 업데이트 과정을 거쳐 이를 복원하게 함으로써 효과적인 메모리 유지 및 활용을 학습시키는 프록시 태스크입니다.
- Intermediate Memory Recall (IMR): 전체 trajectory 중 중간 단계의 메모리 상태를 활용하여 이전 입력의 정보를 복원하게 함으로써, 메모리 내 정보의 완성도와 충실한 압축을 유도하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 장기적인 컨텍스트를 처리해야 하는 LLM 에이전트에서 Memory 병목 현상을 해결하는 것을 핵심 문제로 다룹니다 [Figure 1]. 기존의 연구들은 전체 입력 기록을 컨텍스트에 모두 포함시키는 방식을 사용했으나, 이는 계산 비용의 급격한 증가를 초래합니다. 이를 대체하기 위해 제안된 Context Memory 기반 에이전트들은 주로 다운스트림 태스크에 대한 강화학습(RL)에 의존하고 있어, 고비용의 주석 데이터가 필요하고 데이터 다양성이 부족하다는 한계가 있습니다. 따라서 본 연구는 범용적인 메모리 능력을 향상시키기 위한 자기지도 학습(Self-Supervised) 프레임워크인 MemTrain을 제안합니다.
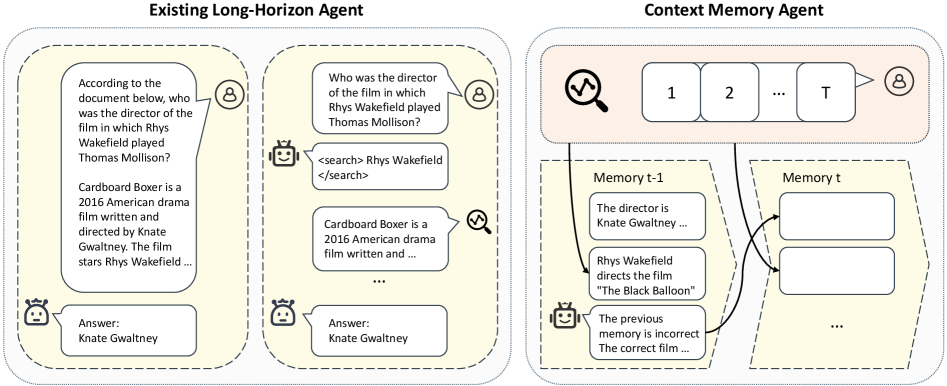
Figure 1 — 기존 컨텍스트 방식과 Memory Agent 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
MemTrain은 두 가지 결합된 프록시 태스크를 통해 메모리 기능을 훈련하는 프레임워크를 구축합니다 [Figure 2]. 첫째, End-to-End Masked Reconstruction을 통해 최종 결과를 예측하며 메모리 유지 능력을 학습하고, 둘째, Intermediate Memory Recall을 통해 중간 메모리 상태에서의 정보 보존 능력을 명시적으로 강화합니다. 이 두 목표는 GRPO를 통해 공동 최적화됩니다. 실험 결과, MemTrain을 사전 훈련(pre-training)으로 사용한 후 다운스트림 태스크를 수행할 경우 성능이 크게 향상되었습니다. Qwen2.5-7B-Instruct 모델 기준, 직접적인 태스크 학습 대비 Long-Text Multi-Hop QA에서는 최대 17.67포인트, Multi-Hop QA With Search Tool에서는 8.50포인트의 성능 향상을 기록하며, 특히 문맥 길이가 매우 긴 환경에서도 우수한 Length Generalization 성능을 보였습니다 [Table 1, Table 2].
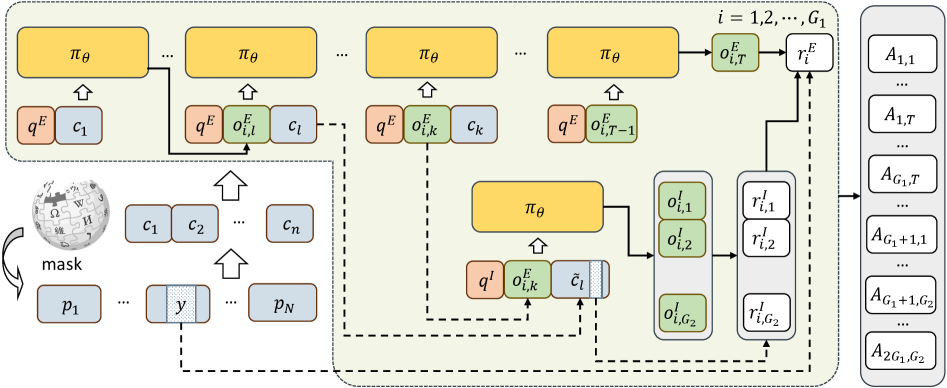
Figure 2 — MemTrain 롤아웃 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM 에이전트의 범용적인 메모리 역량을 자기지도 방식으로 강화할 수 있는 MemTrain 프레임워크를 성공적으로 제시하였습니다. 이 연구는 고비용의 주석 데이터 없이도 Wikipedia와 같은 대규모 비지도 데이터를 활용하여 에이전트의 메모리 완성도와 활용 능력을 높일 수 있음을 증명했습니다. 향후 장기 컨텍스트를 다루는 에이전트 설계 및 효율적인 에이전트 학습 패러다임에 있어 중요한 기점이 될 것으로 기대됩니다.
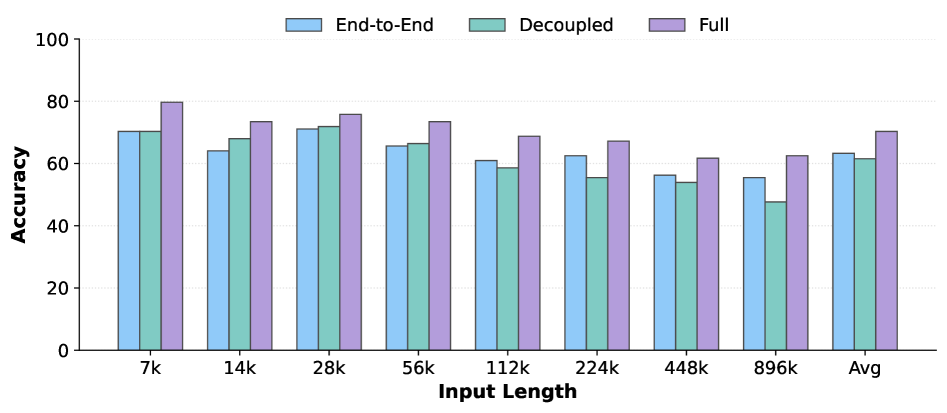
Figure 3 — 컴포넌트별 Ablation 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
- [논문리뷰] Agentic Critical Training
- [논문리뷰] ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
Review 의 다른글
- 이전글 [논문리뷰] MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
- 현재글 : [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- 다음글 [논문리뷰] MeshWeaver: Sparse-Voxel-Guided Surface Weaving for Autoregressive Mesh Generation
댓글