[논문리뷰] MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Qian Kou, Xiaofeng Shi, Yulin Li, Xiaosong Qiu, Xinyang Wang, Hua Zhou, Cao Dongxing
1. Key Terms & Definitions (핵심 용어 및 정의)
- MechVQA: 기계 설계 도면 이해 능력을 평가하기 위해 구축된 데이터셋으로, Recognition, Reasoning, Judging의 3개 범주와 10개의 세부 태스크로 구성됨.
- MechVL: MechVQA 데이터셋을 활용하여 기계 도면 이해에 특화되도록 Supervised Fine-Tuning 및 Reinforcement Learning을 통해 학습된 도메인 특화 모델.
- DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization): 장문의 추론이 필요한 상황에서 강화학습의 안정성과 효율성을 높이기 위해 채택된 최적화 프레임워크.
- Taxonomy-aligned Reward: 모델의 답변 정확도, 포맷 준수 여부, 그리고 논리적 품질을 다각도로 평가하여 학습을 유도하는 다중 구성 보상 체계.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 범용 Multimodal Large Language Models (MLLMs)가 기계 공학 도면의 복잡성과 도메인 특수성을 제대로 해석하지 못하는 문제를 해결하고자 한다. 기존 MLLM은 도면 내 고밀도 주석과 기호 식별, 그리고 투영법 기반의 공간 관계 추론에서 잦은 오류를 범하며, 이는 구조적 불일치로 이어진다 [Figure 1]. 기존 VQA 벤치마크들은 일반적인 이미지나 제한적인 공학적 상황에 치중되어 있어, 실제 산업 현장에서 요구되는 구조적 인식, 다중 뷰 일관성, 공학적 규격 해석을 포괄적으로 평가하기 어렵다는 한계가 존재한다 [Table 1]. 따라서 저자들은 신뢰할 수 있는 도면 이해 능력을 확보하기 위해 체계적인 벤치마크 데이터셋 구축과 이를 바탕으로 한 강화학습 기반의 개선 모델이 필요하다고 제안한다.
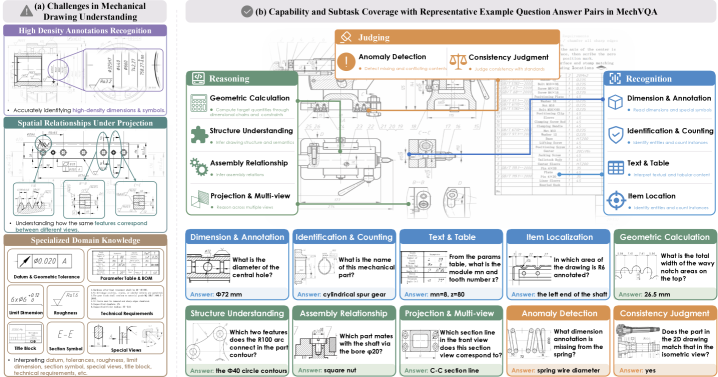
Figure 1 — 기계 도면 이해의 과제 및 데이터셋 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 고품질 도면 데이터를 선별하고 다단계 품질 관리 파이프라인을 통해 MechVQA를 구축하였으며, 이를 기반으로 MechVL 모델을 학습시킨다 [Figure 2]. 제안하는 방법론은 Supervised Fine-Tuning (SFT)을 통해 기본 정책을 확립한 후, DAPO 기반의 강화학습을 통해 기계 설계 도메인에 특화된 추론 능력을 고도화한다. 특히, 정확도, 포맷 일치도, 품질 평가(LLM-as-a-Judge)를 결합한 Taxonomy-aligned Reward 체계가 모델의 성능 향상에 결정적인 역할을 수행한다 [Table 2]. 실험 결과, MechVL-4B-RL은 가장 강력한 closed-source baseline 대비 MechVQA 전체 점수에서 7.57% 향상된 성능을 기록하였다. 특히, 복잡한 공간 추론과 표준 규격 해석이 요구되는 Item Localization (IL) 및 Structure Understanding (SU) 태스크에서 압도적인 성능 우위를 입증하였다 [Table 2].

Figure 2 — MechVQA 데이터 구축 및 모델 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 기계 공학 도면 이해를 위한 최초의 포괄적 벤치마크인 MechVQA와 도메인 특화 모델 MechVL을 성공적으로 도입하였다. 이 연구는 MLLM이 단순한 시각적 인식을 넘어, 엄격한 공학적 규격과 투영 규칙을 준수하는 전문적인 추론 영역으로 확장될 수 있음을 보여준다. 결과적으로, 본 연구에서 제안된 모델과 학습 파이프라인은 향후 기계 설계, 제조 검사, 그리고 다양한 산업 자동화 워크플로우에 MLLM을 안전하게 도입하기 위한 강력한 기술적 토대를 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
- [논문리뷰] Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models
- [논문리뷰] Toward Cognitive Supersensing in Multimodal Large Language Model
- [논문리뷰] Detect Anything via Next Point Prediction
- [논문리뷰] VaseVQA: Multimodal Agent and Benchmark for Ancient Greek Pottery
Review 의 다른글
- 이전글 [논문리뷰] MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
- 현재글 : [논문리뷰] MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
- 다음글 [논문리뷰] Meta-Cognitive Memory Policy Optimization for Long-Horizon LLM Agents
댓글