[논문리뷰] AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
링크: 논문 PDF로 바로 열기
저자: Shanghua Gao, Ada Fang, Marinka Zitnik, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- AutoScientists: 중앙 오케스트레이터 없이 공유된 상태를 기반으로 자율적으로 팀을 구성하고 실험을 수행하는 다중 AI 에이전트 시스템입니다.
- Shared State ($\mathcal{S}$): 에이전트들이 연구 결과, 제안서, 성공/실패 기록, 현재 챔피언 모델 등을 공유하고 협력하기 위해 참조하는 중앙 저장소입니다.
- Analyst Agent: 팀의 연구 지식을 유지하고, 미테스트 연구 방향을 감사하며, 효율적인 탐색을 위해 실험 제안(Proposal)을 생성하는 역할을 수행합니다.
- Experiment Agent: 제안된 연구를 Claim하여 코드를 수정하고 실험을 실행하며, 결과를 공유 상태에 기록하는 에이전트입니다.
- Noise-Aware Champion Validation: 확률적인 평가 지표의 노이즈를 고려하여, 통계적으로 유의미한 개선이 확인된 모델만을 챔피언으로 승격시키는 검증 프로토콜입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 과학적 탐구의 장기적인 연구 과정에서 발생하는 비효율적인 실험 반복과 고립된 탐색 문제를 해결하기 위해 AutoScientists를 제안합니다 [Figure 1]. 기존 AI 에이전트 연구들은 고정된 파이프라인이나 단일 연구 궤적을 따르는 경우가 많아, 실험 결과가 축적됨에 따라 연구 방향을 동적으로 수정하거나 실패한 경로를 기억하여 중복 탐색을 피하는 능력이 부족합니다. 특히 복잡한 과학적 실험에서는 새로운 가설이 연구 중간에 도출되는 경우가 많으나, 기존 방식은 연구 초기 단계에서 고정된 문제 분해를 가정하여 이러한 유연성을 제공하지 못합니다. 따라서 저자들은 에이전트들이 스스로 연구 방향을 조직하고, 상호 비평을 통해 비효율적인 실험을 걸러내며, 연구 성과와 실패를 공유하여 지속적으로 발전할 수 있는 분산형 다중 에이전트 프레임워크가 필요하다고 주장합니다.
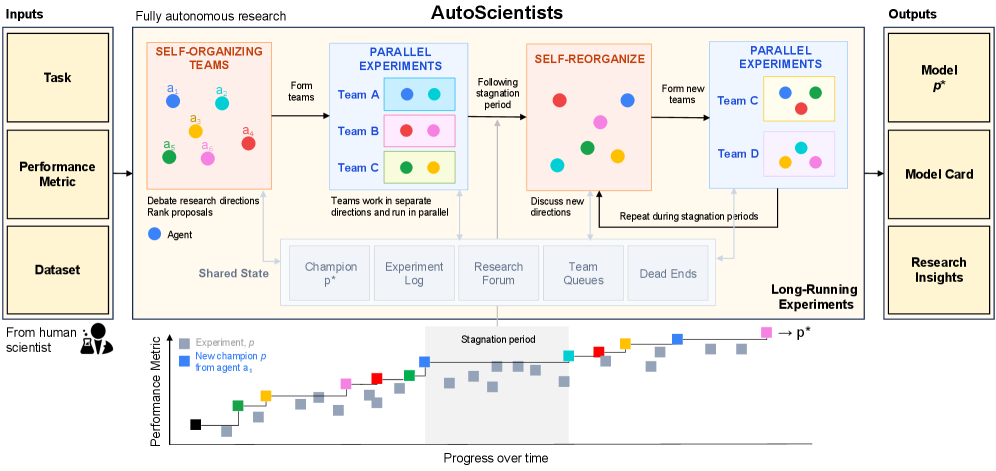
Figure 1 — AutoScientists 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
AutoScientists는 토론(Discussion) 단계와 실행(Execution) 단계를 반복하는 순환 구조로 설계되었습니다. 에이전트들은 토론 단계에서 연구 방향을 제안하고 팀을 자율적으로 구성하며, 실행 단계에서는 할당된 연구 방향에 따라 병렬로 실험을 수행합니다 [Figure 1]. 시스템의 모든 Coordination은 중앙 오케스트레이터 없이 공유된 Forum과 상태 저장소($\mathcal{S}$)를 통해 이루어지며, 팀 구조는 연구 성과에 따라 동적으로 재편됩니다. 주요 실험 결과로, BioML-Bench에서 AutoScientists는 24개 생의학 ML 작업 전반에서 평균 리더보드 백분위수 74.40%를 기록하며, 강력한 베이스라인인 Autoresearch의 66.07% 대비 +8.33%의 성능 향상을 보였습니다 [Figure 3]. 또한 GPT 훈련 최적화 실험에서는 Autoresearch 대비 1.9배 빠른 속도로 중간 검증 손실(Validation bits-per-byte)에 도달했으며, 기존 방법이 개선을 찾지 못하는 상황에서도 7개의 추가 개선 사항을 발굴하는 성과를 거두었습니다 [Figure 4]. 마지막으로 ProteinGym에서 단백질 적합성 예측 성능을 개선하여 Spearman 상관계수를 기존 대비 +6.5% 향상시켰습니다.
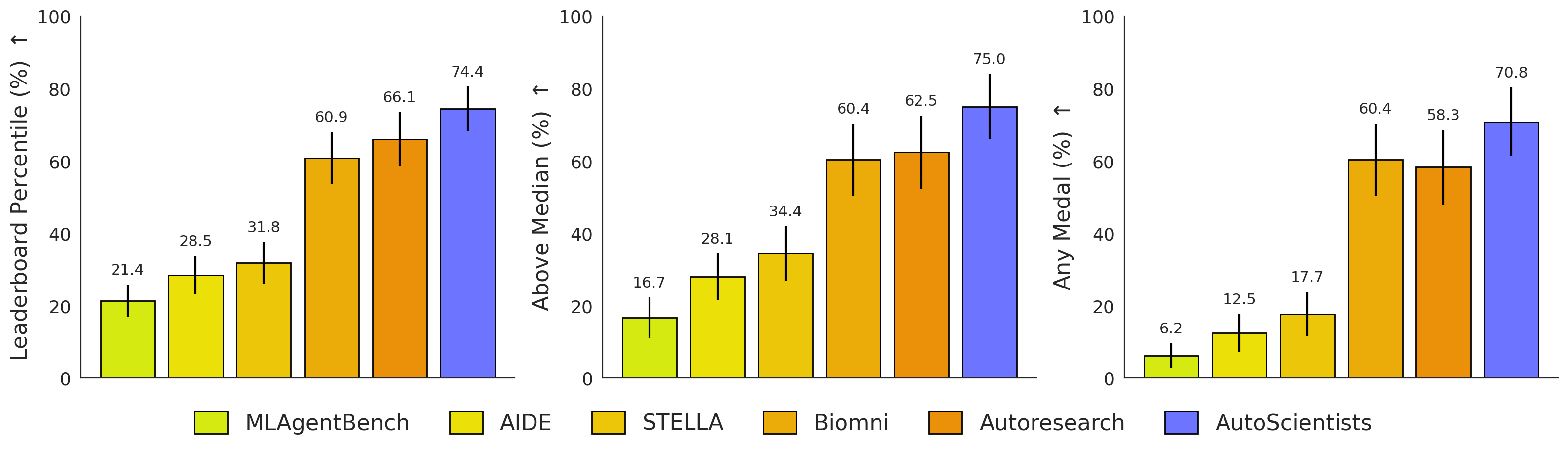
Figure 3 — BioML-Bench 성능 비교
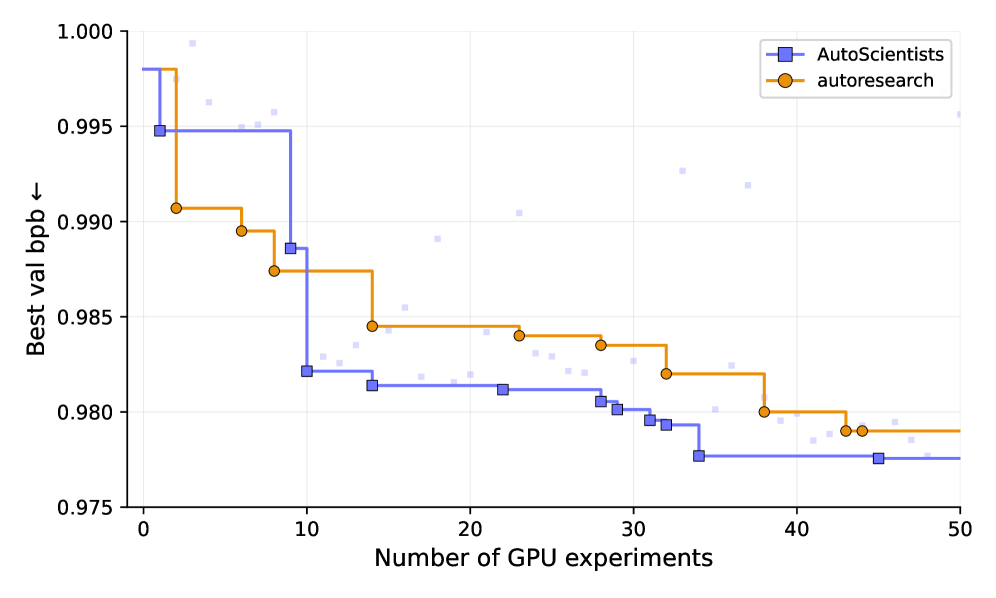
Figure 4 — GPT 훈련 최적화 성능
4. Conclusion & Impact (결론 및 시사점)
본 논문은 장기적인 과학적 실험을 위한 자율적이고 자기 조직적인 다중 에이전트 팀인 AutoScientists를 성공적으로 입증했습니다. 이 연구는 AI 에이전트가 고립된 작업 수행을 넘어, 연구 커뮤니티처럼 지식을 축적하고 실패를 학습하며 협력적으로 가설을 발전시킬 수 있음을 보여줍니다. 학계와 산업계에서는 이 연구를 통해 컴퓨팅 자원이 제한적인 환경에서도 연구 효율성을 극대화하고, 복잡한 과학적 가설 검증 프로세스를 자동화하는 데 있어 중요한 방법론적 토대를 제공받을 수 있을 것입니다. 향후에는 팀 크기의 동적 스케일링과 더욱 복잡한 다목적 최적화 문제로의 확장이 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
- [논문리뷰] Tracing Agentic Failure from the Flow of Success
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
- [논문리뷰] Safety Testing LLM Agents at Scale: From Risk Discovery to Evidence-Grounded Verification
Review 의 다른글
- 이전글 [논문리뷰] AgentFugue: Agent Scaling for Long-Horizon Tasks through Collective Reasoning
- 현재글 : [논문리뷰] AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
- 다음글 [논문리뷰] Chartographer: Counterfactual Chart Generation for Evaluating Vision-Language Models
댓글