[논문리뷰] AgentFugue: Agent Scaling for Long-Horizon Tasks through Collective Reasoning
링크: 논문 PDF로 바로 열기
저자: Yuyang Hu, Hongjin Qian, Shuting Wang, Jiongnan Liu, Tong Zhao, Xiaoxi Li, Zheng Liu, Zhicheng Dou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
본 섹션은 논문에서 핵심적으로 다루는 기술 용어들을 정의한다.
- Scaling Out: 동일한 태스크를 목표로 하는 다수의 피어(Peer) 에이전트의 수 또는 다양성을 증가시켜, 명시적인 역할 특화나 워크플로우 오케스트레이션 없이도 상호작용을 통해 역량 향상을 도모하는 접근 방식.
- Shared Reasoning Hub (ℋ): AgentFugue의 핵심 구성 요소로, 에이전트 간의 중간 추론 진행 상황을 압축하여 기록하고, 다른 에이전트가 자신의 현재 탐색에 유용한 정보를 선택적으로 접근할 수 있도록 중개하는 외부 통신 레이어 [Figure 1].
- Episode: 에이전트의 로컬 컨텍스트 예산에 의해 결정되는 연속적인 상호작용 기록 청크로, 요약되어
Episode Note로 허브에 기록되는 정보 교환의 단위. - Episode Note:
Episode의 팀 관련 내용을 압축하여 다른 에이전트가 볼 수 있도록 허브에 기록된 간결한 요약으로, 에이전트가 팀의 광범위한 진행 상황을 파악하는 데 사용된다. - Intent-driven Reading: 에이전트가 현재의 필요에 따라 특정 팀원의 원시
Episode콘텐츠를 허브에 요청하고, 허브가 이를 합성하여 맞춤형 증거 또는 지침을 반환하는 메커니즘으로, 선택적이고 심층적인 정보 접근을 가능하게 한다.
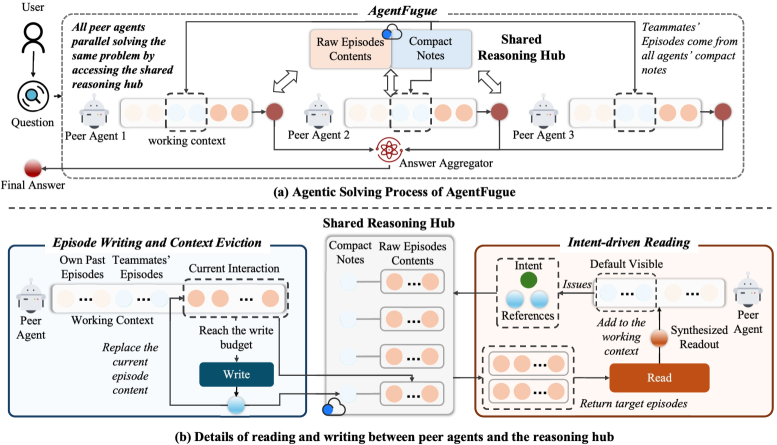
Figure 1 — AgentFugue 아키텍처
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 언어 모델(LLM) 기반 에이전트의 Long-Horizon Tasks 수행 능력 향상에 Scaling Out 전략이 기여할 수 있는지에 대한 연구를 수행한다. 기존 LLM 에이전트의 발전은 주로 더 강력한 모델, 더 나은 도구, 효율적인 스캐폴딩 등을 통한 단일 에이전트의 Scaling Up에 집중되어 왔다. 그러나 이러한 Scaling Up 방식은 단일 Trajectory의 강도를 높이지만, 탐색의 폭(Breadth of Exploration)을 제한하여 복잡한 Long-Horizon Tasks 해결에 한계가 있다.
기존 Multi-Agent Systems 연구는 주로 에이전트에게 특정 역할을 할당(Role Specialization)하거나, 태스크를 하위 태스크로 분해(Task Decomposition)하여 명시적인 Workflow Orchestration을 설계하는 데 중점을 두었다. 또한, Multi-agent Debate와 같은 논의 기반 접근 방식도 존재했으나, 동일한 태스크를 수행하는 피어(Peer) 에이전트들이 사전 정의된 책임 없이도 역량을 향상시킬 수 있는지에 대한 Scaling Out의 잠재력은 상대적으로 덜 탐구되었다.
이러한 Peer Setting에서는 여러 에이전트가 병렬로 탐색하면서 다양한 부분적인 추론 경로, 중간 증거, 또는 실패한 브랜치를 발견할 수 있지만, Communication이 없으면 이들은 고립된 탐색으로 남아 결과를 사후에 병합해야 하는 비효율성이 발생한다. 반대로 무제한 Communication은 유용한 신호가 노이즈에 묻히거나 탐색의 다양성이 빠르게 붕괴될 위험이 있다. 따라서, 저자들은 피어 에이전트들이 선택적으로 중간 진행 상황을 교환하면서도 각자의 탐색 방향을 유지하는 Collective Reasoning 메커니즘의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 피어 에이전트 간의 Collective Reasoning을 구현하기 위해 Shared Reasoning Hub를 중심으로 설계된 AgentFugue 프레임워크를 제안한다 [Figure 1]. 이 Hub는 중앙 집중식 Planner가 아닌 외부 Communication Layer 역할을 하며, 각 에이전트가 일련의 상호작용(Episode)을 완료할 때마다 해당 에이전트가 확인했거나 시도했거나 배제한 것에 대한 간결한 Episode Note를 기록한다. 이후 다른 에이전트들은 자신의 현재 탐색에 유용한 부분적인 진행 상황에 선택적으로 접근할 수 있다.
AgentFugue는 두 가지 핵심 Operation을 통해 Shared Reasoning Hub를 구현한다. 첫째, Episode Writing은 에이전트의 로컬 Context Window가 특정 Write Budget에 도달하면 현재 세그먼트를 Episode로 마감하고, Hub Model(Mwrite)이 이를 압축하여 Episode Note(zi,e)를 생성한다 [Figure 1]. 이 과정에서 에이전트의 작업 컨텍스트에 있는 원시 Episode 콘텐츠는 Eviction되고 Episode Note로 대체되어, 컨텍스트 용량을 확보하고 다른 에이전트와의 공유에 적합한 형태로 변환된다. 둘째, Intent-driven Reading은 에이전트가 현재 컨텍스트(𝒞i,t)를 기반으로 필요한 정보 유형(Intent, qi,t)과 참조할 팀원의 Episode References(ℰi,t)를 지정하여 Hub에 요청하면, Hub Model(Mread)이 이를 합성하여 맞춤형 Readout(ri,t)을 반환한다 [Figure 1]. 이 Two-level Design은 Episode Note를 통한 광범위한 인식과 Intent-driven Reading을 통한 선택적 심층 탐색을 가능하게 하여 Communication의 효율성을 높인다.
Hub는 Qwen3.5-9B 백본으로 초기화되며, Supervised Fine-tuning (SFT)과 End-to-End Reinforcement Learning의 일환인 Group Relative Policy Optimization (GRPO)을 통해 최적화된다. GRPO는 Task Success와 Brevity Bonus를 결합한 Group-relative Advantages를 활용하여 Hub가 중간 진행 상황을 요약하는 것을 넘어 전체 에이전트 루프 내에서 유용한 Guidance를 제공하도록 학습시킨다.
저자들은 BrowseComp, WideSearch, HLE 세 가지 Long-Horizon Benchmarks에서 AgentFugue를 평가했으며, 모든 벤치마크에서 강력한 베이스라인 대비 일관된 우위를 보였다 [Table 1]. 특히, DeepSeek-v4-Flash 백본을 사용하는 AgentFugue는 BrowseComp에서 71.2% 정확도를 달성하여 Swarm-Multi-Agent 대비 +15.0 포인트 향상되었고, HLE에서는 49.5% 정확도로 +5.5 포인트 향상되었다 [Table 1]. 이러한 결과는 Shared-Hub Coordination 메커니즘이 단일 벤치마크의 특이성에 국한되지 않고 다양한 태스크 유형에 걸쳐 Gains를 제공함을 시사한다.
또한, Homogeneous Teams (동일 모델 에이전트)와 Heterogeneous Teams (상이 모델 에이전트) 모두에서 Scaling Out의 효과를 검증했다 [Figure 2, Figure 4]. Homogeneous Teams의 경우, 에이전트 수가 증가함에 따라 Per-agent search and visit calls은 감소하고 Per-question memory traffic은 증가하여, 개별 에이전트가 Hub를 통해 부분적인 작업을 상속받아 더 Efficient해지는 동시에 Shared Coordination으로의 Effort Shift가 발생함을 보여주었다 [Figure 2(b)]. Heterogeneous Teams에서는 각 모델 Trajectory가 독립 실행형 성능보다 훨씬 우수했으며, 약한 모델들이 Hub를 통해 두 자릿수 Margin으로 가장 큰 Gain을 얻었다 [Figure 4(a)]. 이는 Complementary Backbones가 Intermediate Notes를 생성하여 Hub Usage를 크게 증가시켰음을 나타낸다 [Figure 4(b)].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Long-Horizon Agentic Reasoning의 새로운 Scaling Axis로서 Scaling Out의 잠재력을 탐구한다. 저자들은 단일 Trajectory의 강화를 넘어 다수의 피어 에이전트가 동일한 태스크를 해결하면서 상호 개선될 수 있다는 아이디어를 제시하고, 이를 Shared Reasoning Hub를 중심으로 한 AgentFugue 프레임워크로 구체화하였다. 이 Hub는 완료된 Episode에서 간결한 Note를 작성하고 Intent-driven Reading을 통해 팀원 Trajectory에 대한 접근을 지원한다.
실험 결과는 Homogeneous 및 Heterogeneous Teams 모두에서 AgentFugue의 Communication Layer가 팀 수준의 성능과 개별 Trajectory Quality를 모두 향상시켰음을 보여준다. 이는 Peer-agent Scaling이 단순히 독립적인 샘플링과 최종 Aggregation을 넘어선 독자적인 Capability Gains의 원천이 될 수 있음을 시사한다. 이 연구는 과학 연구 지원, 개방형 도메인 연구, 조사 분석 등 지식 집약적인 태스크에서 보다 효과적인 시스템을 구축하는 데 중요한 시사점을 제공한다.
하지만 Collective Reasoning은 Misleading Intermediate Hypotheses가 팀 전체에 전파될 수 있는 Failure Modes를 내포한다. 향후 연구에서는 Confidence Calibration, Diversity-aware Reading Policies, Adaptive Note Selection과 같은 Safeguards를 개발하여 Communication의 신뢰성을 높이면서도 Trajectory Diversity를 보존하는 방향으로 나아가야 할 것이다.
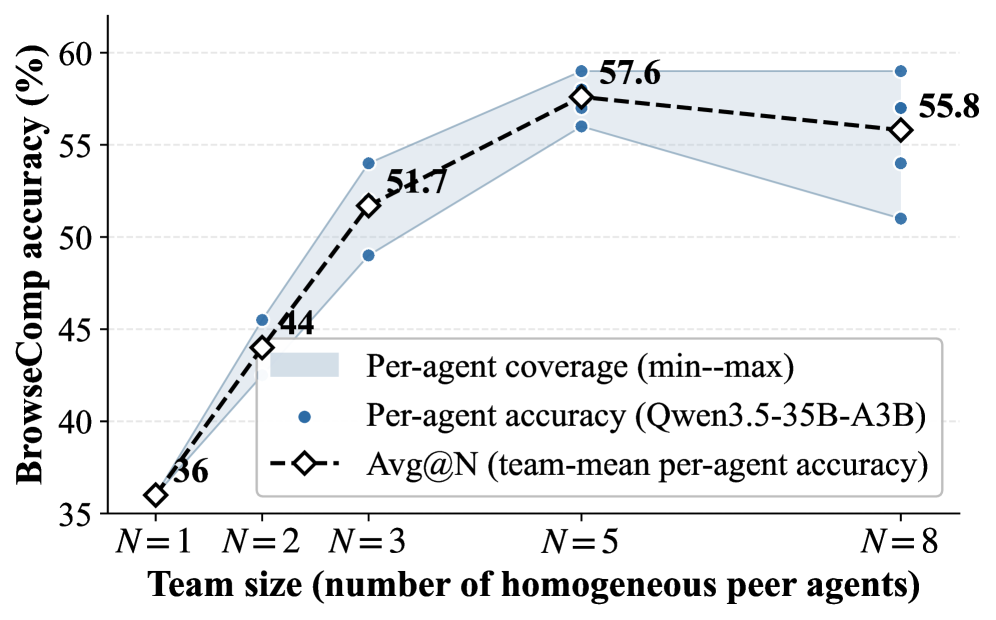
Figure 2 — 동종 팀 스케일링 성능
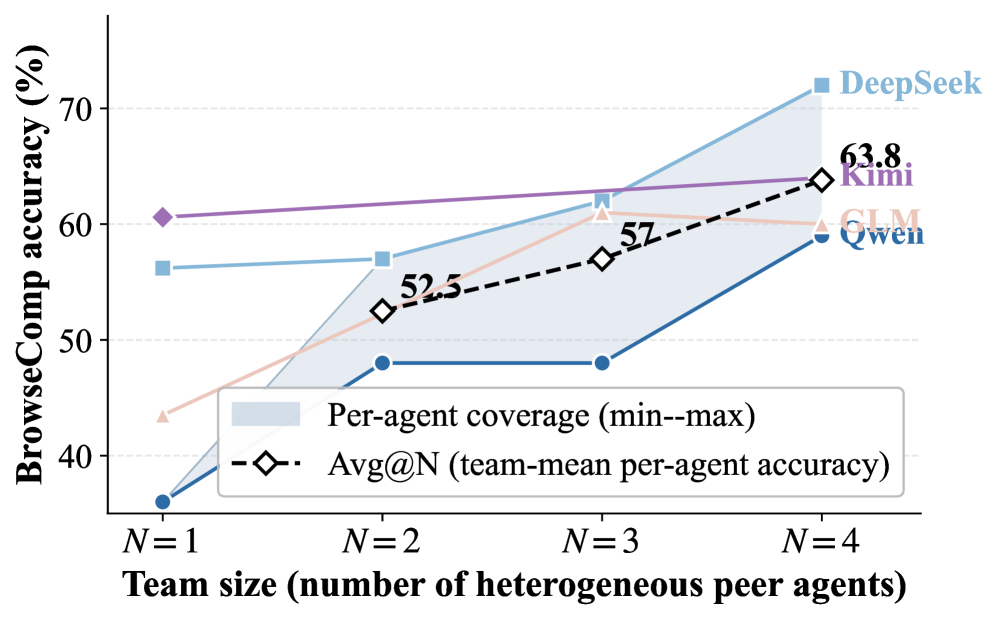
Figure 4 — 이종 팀 스케일링 성능
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] Agent Bazaar: Enabling Economic Alignment in Multi-Agent Marketplaces
- [논문리뷰] Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces
- [논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
- [논문리뷰] Hindsight Credit Assignment for Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
- 현재글 : [논문리뷰] AgentFugue: Agent Scaling for Long-Horizon Tasks through Collective Reasoning
- 다음글 [논문리뷰] AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
댓글