[논문리뷰] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
링크: 논문 PDF로 바로 열기
저자: Minki Kang, Shizhe Diao, Ryo Hachiuma, Sung Ju Hwang, Pavlo Molchanov, Yu-Chiang Frank Wang, Byung-Kwan Lee
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Thinking-Acting Gap: reasoning models에서 기본 모드인 '생각(Thinking)'과 고변동성 보조 행동인 '도구 사용(Tool use)' 사이의 구조적 비대칭성으로 인해 발생하는 학습 저해 현상.
- GRPO (Group Relative Policy Optimization): 다수의 rollout을 그룹화하여 보상 평균 대비 상대적 우위(advantage)를 계산하여 정책을 업데이트하는 기존의 RL 기법.
- Tool-call Resampling: 실패한 도구 호출의 thinking prefix는 고정하고, 도구 호출 및 그 이후의 continuation만을 재샘플링하여 효과적인 학습 신호를 복구하는 AXPO의 핵심 기법.
- AXPO (Agent eXplorative Policy Optimization): thinking-acting gap을 좁히기 위해 도구 사용 실패 그룹에서 prefix를 수정하고 uncertainty-based ranking을 적용하여 탐색을 최적화하는 제안된 RL 알고리즘.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 vision-language models(VLMs)의 agentic reasoning 과정에서 발생하는 '도구 사용의 비효율성' 문제를 해결하고자 합니다. 기존의 GRPO와 같은 RL 기법을 적용할 경우, 도구 사용은 소수의 rollout에서만 시도되며, 도구 사용 시도 그룹이 전체적으로 실패(all-wrong)하는 비율이 높아 도구 호출 토큰에 대한 유효한 학습 신호가 생성되지 않는 한계가 있습니다. 이러한 비대칭성 때문에 모델은 도구 사용 능력을 충분히 학습하지 못하고, thinking-only 모델의 성능에 안주하는 경향이 있습니다. [Figure 2]는 이러한 기존 접근 방식의 문제를 명확히 보여주며, 왜 도구 호출 지점에서 추가적인 exploration이 필요한지를 설명합니다.
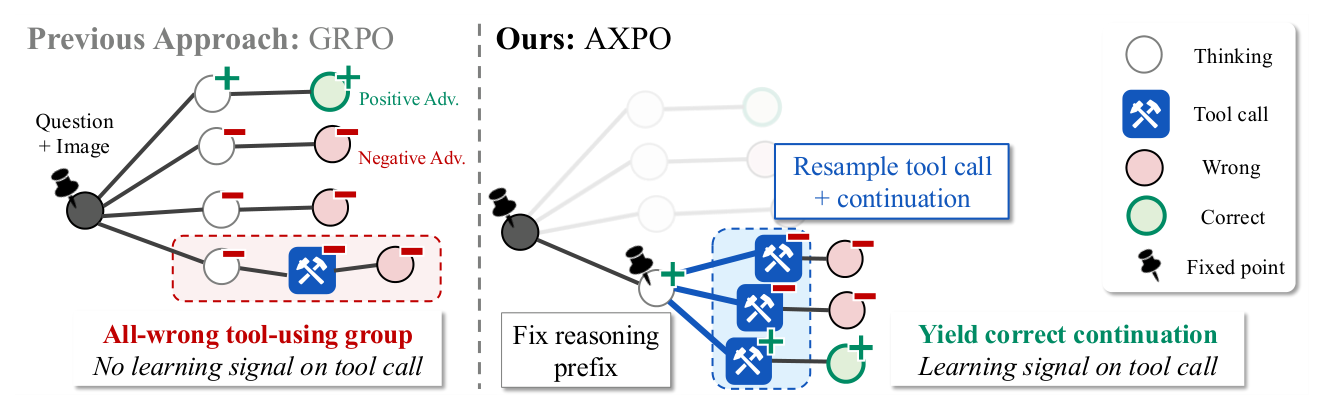
Figure 2 — GRPO의 실패 사례와 AXPO의 해결 기법을 대조하여 보여주는 핵심 개념도
## 3. Method & Key Results (제안 방법론 및 핵심 결과) AXPO는 모든 도구 사용이 실패한(all-wrong) 그룹을 타겟으로 하여, 해당 실패 rollout의 thinking prefix를 고정하고 도구 호출 및 continuation을 재샘플링함으로써 모델이 다양한 도구 사용 전략을 탐색하도록 강제합니다. 특히, 16개의 샘플링을 통해 얻은 다양한 도구 호출 패턴을 기반으로, uncertainty(신뢰도)가 가장 낮은 prefix를 우선적으로 선택하여 최적화함으로써 효율적인 탐색을 보장합니다. 제안된 방법론은 Qwen3-VL-Thinking 2B/4B/8B 모델에서 SFT + GRPO 대비 Pass@1에서 평균 +1.8 pp(8B 기준), Pass@4에서 우수한 성능 향상을 입증하였습니다. 특히 8B 모델은 32B Base 모델의 Pass@4 성능을 상회하며 파라미터 대비 압도적인 효율성을 보였습니다. [Table 1]에서 볼 수 있듯이, 모든 벤치마크와 스케일에서 SFT + AXPO는 기존 baseline을 뛰어넘는 안정적인 성능 개선을 보여줍니다.
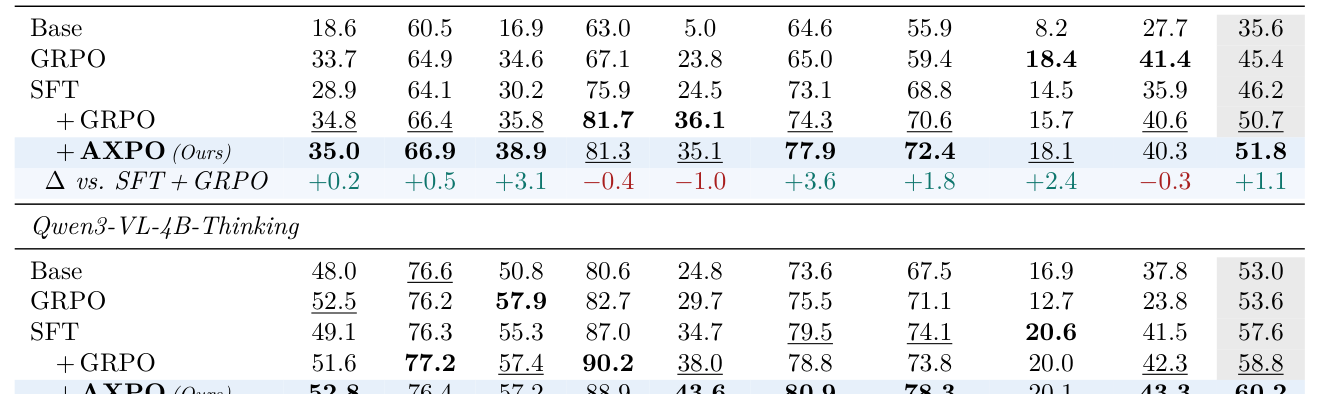
Table 1 — 제안 모델(AXPO)과 기존 baselines의 벤치마크 성능 비교표
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 agentic reasoning 모델 학습에서 도구 사용의 취약점을 분석하고, 이를 해결하기 위한 효과적인 전략으로서 AXPO를 제안합니다. 이 기법은 고비용의 추가 rollout 없이도 도구 사용 실패 그룹에서의 gradient 신호를 복구함으로써, 모델의 추론 및 행동 결합 능력을 획기적으로 개선합니다. 이 연구는 대규모 언어 모델뿐만 아니라 시각 정보를 도구로 처리하는 멀티모달 에이전트의 학습 파이프라인에서 탐색(exploration)의 중요성을 재조명하였으며, 향후 다양한 도구 환경과 기반 모델로의 확장 가능성을 제시하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] TRivia: Self-supervised Fine-tuning of Vision-Language Models for Table Recognition
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] DrugGen 2: A disease-aware language model for enhancing drug discovery
Review 의 다른글
- 이전글 [논문리뷰] AgensFlow: A Coordination-Policy Substrate for Multi-Agent Systems
- 현재글 : [논문리뷰] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
- 다음글 [논문리뷰] AgentFugue: Agent Scaling for Long-Horizon Tasks through Collective Reasoning
댓글