[논문리뷰] AgensFlow: A Coordination-Policy Substrate for Multi-Agent Systems
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nicole Koenigstein
1. Key Terms & Definitions (핵심 용어 및 정의)
- AgensFlow: 다중 에이전트 시스템(MAS)의 조율을 정적인 파이프라인이 아닌, 반복적인 궤적(trajectory)을 통해 온라인으로 학습 가능한 정책으로 처리하는 오픈소스 프레임워크입니다.
- Folded Task Signatures: 사용자의 의도나 과제의 난이도와 같은 잠재적 상태를 직접 관측하는 대신, 관측 가능한 과제 특징, 핸드오프 상태, 신념(belief) 추정치를 결합하여 이산적인 상태 공간으로 추상화한 것입니다.
- skip:X: 특정 과제 단계나 에이전트 역할을 건너뛸 수 있게 하는 토폴로지 제어 액션으로, 시스템이 작업 환경에 따라 최적의 실행 경로를 스스로 학습하게 합니다.
- RelativeJudge: 절대적인 점수를 부여하는 대신 동일한 과제 클래스 내의 여러 실행 결과(궤적)를 비교하여 상대적인 품질을 평가함으로써, 보상 해킹(reward-hacking)을 방지하고 보다 정밀한 조율 신호를 제공하는 평가 메커니즘입니다.
- Policy Graph: 각 (signature, action) 쌍에 대한 방문 횟수, 평균 보상, 실패율 등을 저장하여 에이전트의 조율 정책을 가시화하고 감사(audit) 가능하게 만드는 학습 객체입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반의 다중 에이전트 시스템에서 발생하는 조율 불투명성과 고정된 파이프라인의 경직성 문제를 해결하고자 합니다. 기존의 연구들은 정적인 파이프라인이나 단발적인 모델 비교에 의존하여, 과제 유형이나 운영 제약에 따라 동적으로 변화해야 하는 에이전트의 기술 호출, 역할 할당, 토폴로지 결정 등을 최적화하는 데 한계를 보였습니다. 이러한 선택들은 서로 복잡하게 상호작용하기 때문에, 단순한 엔지니어링 직관만으로는 최적의 운영 정책을 탐색하기 어렵습니다. 따라서 본 논문은 조율 과정을 학습 가능한 온라인 정책 문제로 재정의하여 보다 견고하고 가시적인 시스템 설계를 제안합니다 [Figure 2].
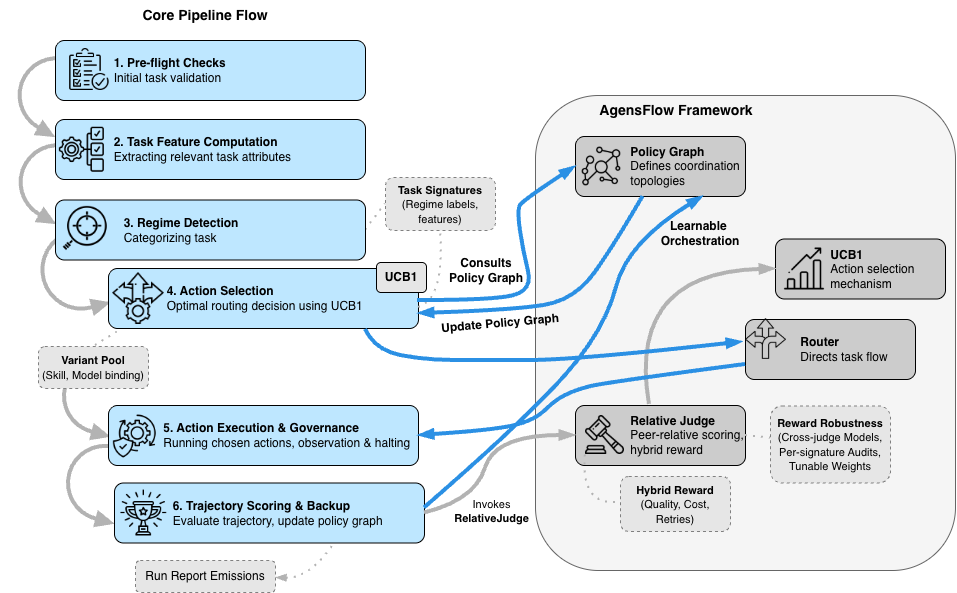
Figure 2 — AgensFlow 시스템 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 다중 에이전트 오케스트레이션을 partially observable한 순차적 결정 과정으로 모델링하고, 이를 온라인으로 학습하는 AgensFlow를 제안합니다. 시스템은 입력된 과제 상태를 Folded Task Signatures로 변환한 후, UCB1 기반의 알고리즘을 사용하여 skill protocol, 모델 바인딩, 그리고 skip:X를 포함한 최적의 조율 액션을 결정합니다 [Figure 2]. 주요 실험 결과, AgensFlow는 조율이 많이 필요한 과제 클래스(예: cross-document multi-vendor reasoning)에서 고정된 파이프라인 베이스라인 대비 유의미한 성능 향상을 보였으며, 특히 C3 클래스에서 +0.181, C8 클래스에서 +0.156의 품질 개선을 달성했습니다 [Table 3]. 또한 warm-start 전략을 통해 기존에 학습된 정책 그래프를 활용함으로써, 새로운 도메인에서도 탐색 비용(exploration cost)을 약 10%~21% 절감하면서도 plateau 품질을 안정적으로 유지함을 확인했습니다 [Figure 4]. 이러한 결과는 학습된 조율 정책이 고정된 정적 배선(static wiring)보다 조율 중심의 워크플로우에서 우수하다는 것을 뒷받침합니다.
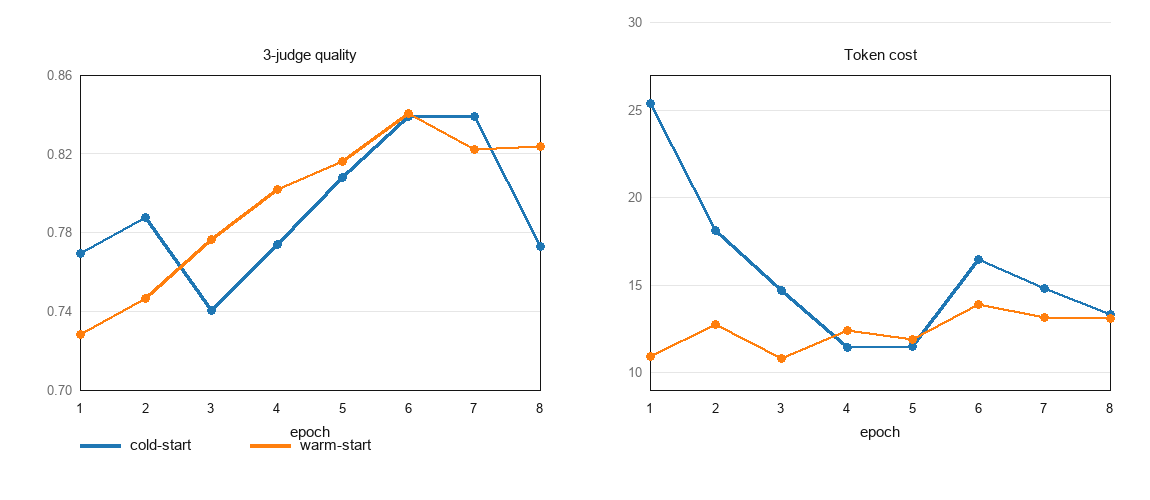
Figure 4 — Warm-start 학습 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 다중 에이전트 시스템의 조율 정책을 반복적인 경험을 통해 온라인으로 학습 가능한 객체로 변환함으로써, 시스템의 가시성과 성능을 동시에 개선하는 프레임워크를 제시했습니다. 연구는 조율 표면(coordination surface)이 매우 방대하고 과제 regimes에 민감하여 직관만으로 설계할 수 없음을 밝혀냈으며, 보상 신호의 견고함을 확보하기 위해 평가(Evaluation)를 시스템의 핵심 구성 요소로 통합해야 함을 강조합니다. 이 연구는 향후 복잡한 도메인에서 에이전트 간의 동적 협업을 구현하려는 실무자와 연구자들에게, 성능과 투명성을 모두 갖춘 오케스트레이션 설계 지침을 제공하는 중요한 이정표가 될 것입니다.
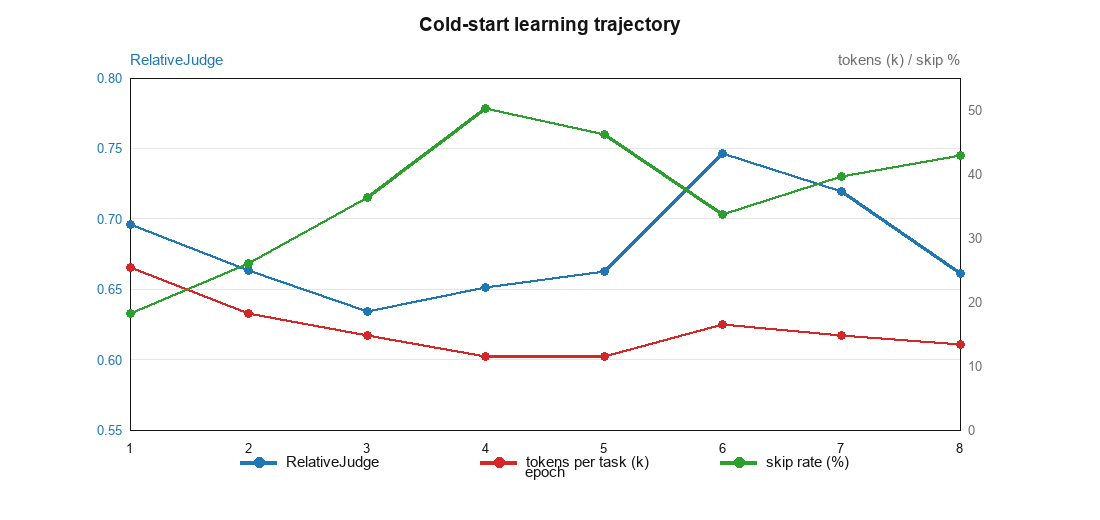
Figure 3 — 콜드 스타트 학습 궤적
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agent Bazaar: Enabling Economic Alignment in Multi-Agent Marketplaces
- [논문리뷰] Learning to Act and Cooperate for Distributed Black-Box Consensus Optimization
- [논문리뷰] Heterogeneous Agent Collaborative Reinforcement Learning
- [논문리뷰] Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
- [논문리뷰] RecGPT-V2 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] Advancing Creative Physical Intelligence in Large Multimodal Models
- 현재글 : [논문리뷰] AgensFlow: A Coordination-Policy Substrate for Multi-Agent Systems
- 다음글 [논문리뷰] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
댓글