[논문리뷰] Advancing Creative Physical Intelligence in Large Multimodal Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Cheng Qian, Hyeonjeong Ha, Jiayu Liu, Jeonghwan Kim, Emre Can Acikgoz, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MM-CreativityBench: 물리적으로 제약된 환경에서 도구의 창의적 재사용(creative tool repurposing) 능력을 평가하기 위해 설계된 인터랙티브 벤치마크입니다.
- Affordance-Grounded Alignment: 모델이 물리적 속성과 기능적 제약 사항을 기반으로 도구 사용을 추론하도록 유도하는 preference learning 프레임워크입니다.
- Direct Preference Optimization (DPO): 모델이 Grounded reasoning을 선호하도록 학습시키기 위해, 긍정적인(positive) 경로와 오류가 포함된 부정적인(negative/hard-negative) 경로를 대비시키는 학습 기법입니다.
- System 1 Inference: 기존 LMM이 흔히 보이는 빠르고 직관적이지만 추론의 깊이가 얕고 근거가 부족한 판단 방식을 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 대규모 다중모달 모델(LMM)이 인식 및 추론 능력은 크게 발전했음에도 불구하고, 비일상적인 상황에서 사물을 창의적으로 재사용하는 물리적 지능이 여전히 부족하다는 문제의식에서 출발합니다. 기존 모델들은 텍스트 기반의 지식에는 능숙하지만, 실제 물리 환경에서 사물의 기하학적 구조나 재질 등 세밀한 속성을 기반으로 한 Grounding(지면화) 수행에는 한계를 보입니다. 특히 모델들이 표면적으로는 그럴듯한 답변을 생성하지만, 실제로는 물리적으로 불가능하거나 근거가 없는 'hallucination'된 판단을 내리는 경우가 많습니다. 이러한 문제를 해결하기 위해 모델이 환경을 직접 탐색하고 세밀한 시각적 근거를 수집하는 과정 중심의 평가와 학습 체계가 필요함을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모델의 창의적 추론을 시각적 근거 기반의 인터랙티브 프로세스로 정의하고, MM-CreativityBench와 Affordance-Grounded Alignment 학습법을 제안합니다. 이 방법론은 모델이 환경을 관찰하고 객체와 부품(part)을 단계별로 검사하며 최적의 도구를 선택하는 다중 턴(multi-turn) 탐색 정책을 학습하게 합니다. [Table 1]에 명시된 바와 같이, 본 벤치마크는 기존 연구들과 달리 Fine-Grained Creativity와 Visual Grounding을 인터랙티브 프로토콜 내에서 포괄적으로 평가합니다.

Table 1 — 제안하는 벤치마크와 기존 연구들의 차별점 및 평가 항목 요약
주요 실험 결과, SFT(Supervised Fine-Tuning)와 DPO(Direct Preference Optimization)를 결합한 모델은 학습 전 모델 대비 Gold Correct Rate를 Qwen3-4B 모델 기준 0.156에서 0.417로, Qwen3-8B 모델 기준 0.192에서 0.393으로 대폭 향상시켰습니다. 또한, Average Number of Exploration Turns가 현저히 감소하여 보다 효율적이고 선택적인 탐색 정책을 갖추게 되었음을 확인했습니다. [Table 3]과 [Table 4]의 결과는 단순히 모델의 파라미터 규모를 키우는 것보다, 세밀한 시각적 근거를 판단하는 정책 학습이 창의적 물리 지능 향상에 핵심적임을 입증합니다.

Table 3 — 모델별 벤치마크 정량적 성과 지표 비교
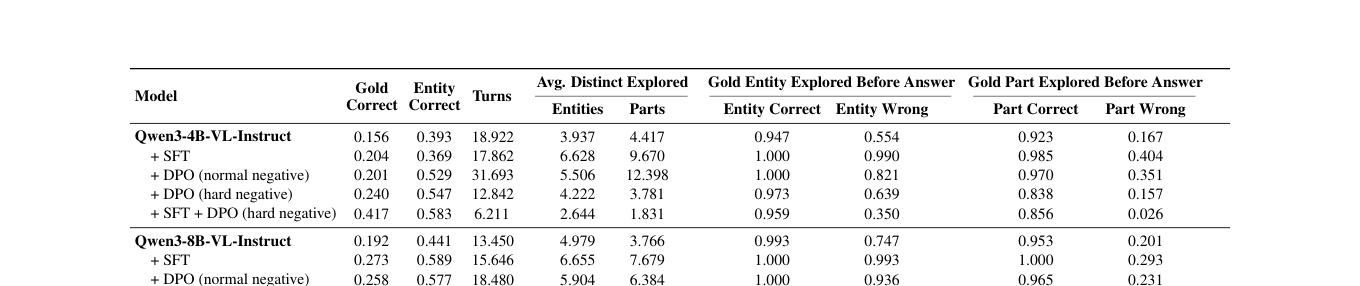
Table 4 — 학습 기법(SFT, DPO)에 따른 성능 변화 및 탐색 효율 지표
4. Conclusion & Impact (결론 및 시사점)
본 연구는 창의적 지능이 단순한 생성 능력이 아닌, 시각적 증거에 기반한 탐색과 물리적 속성 추론의 결합임을 증명하며 관련 분야의 새로운 방향성을 제시합니다. 특히 Hard-negative DPO를 활용한 학습이 모델의 환각 현상을 줄이고 물리적 타당성을 확보하는 데 매우 효과적임을 입증했습니다. 이는 향후 로봇 공학 및 Embodied AI가 미지의 환경에서 복잡한 도구 재사용 문제를 해결하는 데 중요한 기술적 토대가 될 것으로 기대됩니다. 본 벤치마크는 학계와 산업계가 LLM을 넘어선 '물리적 지능'을 가진 차세대 다중모달 모델을 개발하는 데 핵심적인 가이드라인을 제공할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Selective Training for Large Vision Language Models via Visual Information Gain
- [논문리뷰] SciVideoBench: Benchmarking Scientific Video Reasoning in Large Multimodal Models
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
Review 의 다른글
- 이전글 [논문리뷰] AI Research Agents Narrow Scientific Exploration
- 현재글 : [논문리뷰] Advancing Creative Physical Intelligence in Large Multimodal Models
- 다음글 [논문리뷰] AgensFlow: A Coordination-Policy Substrate for Multi-Agent Systems
댓글