[논문리뷰] Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zili Wang, Jiajun Chai, Lin Chen, Xiaohan Wang, Shiming Xiang, Guojun Yin
1. Key Terms & Definitions (핵심 용어 및 정의)
- MTP (Multi-Token Prediction): 메인 모델 이후의 여러 미래 토큰을 예측하도록 학습되는 모듈로, pretraining 단계에서 샘플 효율성과 추론 능력을 향상시키는 데 널리 사용됨.
- RLVR (Reinforcement Learning from Verifiable Rewards): 검증 가능한 보상 시스템을 통해 LLM의 추론 능력을 강화하는 post-training 표준 패러다임.
- Detach: MTP head의 gradient가 메인 모델로 역전파되지 않도록 차단하는 방식으로, 공동 학습 시 발생하는 성능 저하를 방지하기 위해 흔히 선택되는 기법.
- OCC (Optimal Coefficient Calibration): 제안하는 기법으로, MTP 학습 계수($\lambda$)를 실시간으로 보정하여 RL objective에 미치는 긍정적 효과를 극대화하는 adaptive scheme.
- Log-probability Gradient Proxy: 전체 모델의 gradient를 계산하는 대신, 작은 step 업데이트 간의 로그 확률 변화($\delta$)를 사용하여 gradient 상관관계와 분산을 효율적으로 추정하는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM post-training 과정에서 MTP와 RL objectives를 공동으로 학습할 때 발생하는 심각한 성능 저하 문제를 해결하고자 한다. 기존 RL framework들은 이러한 성능 저하를 방지하기 위해 MTP gradient를 차단하는 Detach 방식을 표준으로 채택해 왔으며, 이는 MTP가 가진 잠재적 이점(multi-step representation 및 효율적 추론)을 충분히 활용하지 못하게 만든다. 저자들은 이 실패의 근본 원인을 최적화 관점에서 분석하고, 세 가지 학습 체계(Detach, Cross-Entropy loss, Policy loss)가 왜 각각 성공하거나 실패하는지에 대한 이론적 근거를 제시한다 [Figure 1].
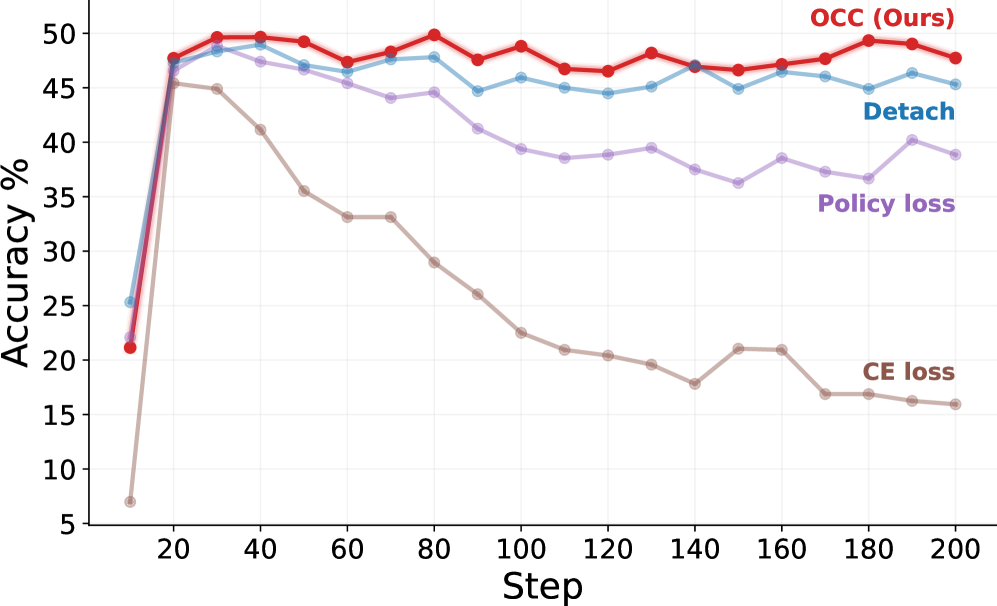
Figure 1 — 모델별 성능 저하 및 MTP 학습 체계 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MTP가 RL objective에 미치는 per-step 효과를 1차 상관관계 항(first-order correlation term)과 2차 섭동 페널티(second-order perturbation penalty)로 분해하는 이론적 프레임워크를 제안한다. 분석 결과, Policy loss 체계는 초기에는 상관관계가 지배하여 성능을 향상시키지만, 학습이 진행될수록 상관관계는 감소하고 섭동 페널티가 지속되면서 성능이 하락하는 위상 전이(phase transition)를 겪는다 [Figure 2], [Figure 3]. 이에 대응하여 제안된 OCC는 실시간으로 최적의 계수 $\lambda_t$를 추적하여 학습 과정 전반에서 성능 개선을 유지한다. 실험 결과, OCC는 6개의 수학적 추론 벤치마크에서 기존 Detach 및 Policy loss 대비 일관된 우위를 점하며, 평균 정확도에서 최고 성능(예: MiMo-7B-RL w/ DAPO 환경에서 61.7%)을 달성하였다 [Table 1]. 특히 OCC는 정확한 gradient 계산 비용 없이 log-probability proxy만을 사용하여 negligible한 비용으로 효율적인 성능 개선을 보였다 [Figure 5].
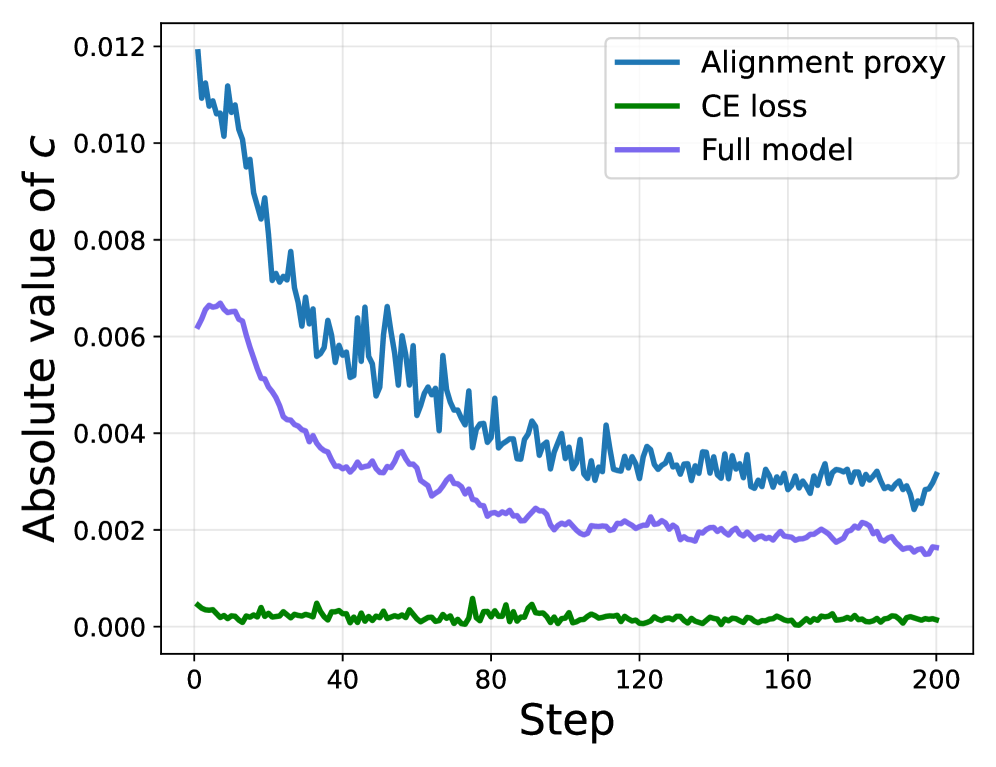
Figure 2 — 계수 성분 변화 및 학습 동역학 분석
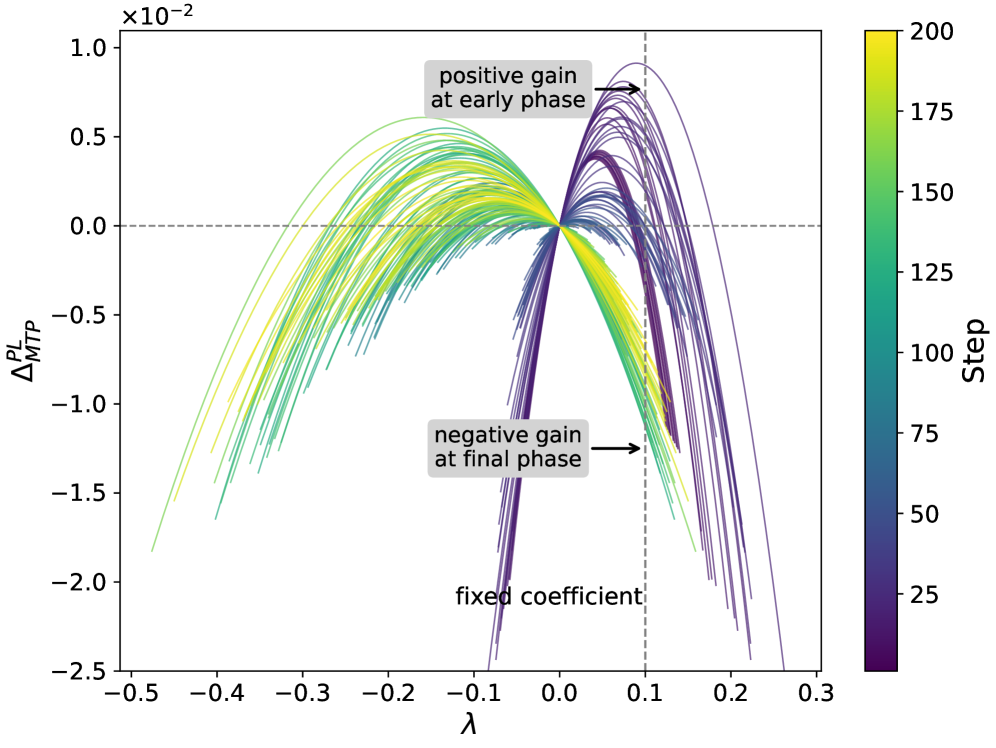
Figure 3 — 학습 단계별 정책 정렬 이득의 진화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MTP와 RL의 공동 학습 실패가 정적 계수 설정에 따른 위상 전이 때문임을 규명하고, OCC를 통해 이를 성공적으로 해결하였다. 이 연구는 LLM post-training에서 MTP를 효과적으로 결합할 수 있는 principled한 전략을 제공하며, 연산 자원 효율성 측면에서도 매우 실용적이다. 향후 이 방식은 추론 중심의 고성능 LLM 개발에 필수적인 기술적 토대가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learn Hard Problems During RL with Reference Guided Fine-tuning
- [논문리뷰] Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
- [논문리뷰] InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
- [논문리뷰] Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
- [논문리뷰] Exploration v.s. Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
Review 의 다른글
- 이전글 [논문리뷰] HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
- 현재글 : [논문리뷰] Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
- 다음글 [논문리뷰] Learn from Weaknesses: Automated Domain Specialization for Small Computer-Use Agents
댓글