[논문리뷰] HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yansong Ning, Mianpeng Liu, Jingwen Ye, Weidong Zhang, Hao Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Hybrid-Reasoning LLMs: 사용자가 모델의 추론 노력(reasoning effort)을 직접 제어할 수 있도록
think(심층 추론) 모드와no_think(직접 응답) 모드 간의 전환을 지원하는 LLM입니다. - Thinking-Mode Switch Strategies: 모델의 추론 품질과 추론 비용(토큰 사용량) 간의 균형을 맞추기 위해, 언제 어떤 모드로 추론할지 결정하는 전략으로 Prompt-Tuning, Routing, Speculative 세 가지로 분류됩니다.
- Effectiveness-Efficiency Trade-off: 모델의 추론 정확도(Acc)와 출력 토큰 비용(Tok) 간의 상충 관계를 의미하며, 연구의 핵심 평가 지표입니다.
- Training Regimes: 모델의 추론 전환 능력을 최적화하기 위해 적용되는 학습 방식으로, Training-Free, SFT, Offline RL, Online RL 등이 포함됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Hybrid-Reasoning LLM의 효율적인 활용을 위한 핵심 과제인 '상황별 최적의 추론 모드 선택' 문제를 해결하고자 합니다. 기존 연구들은 각기 다른 모델, 데이터셋, 평가 환경에서 개별적으로 제안되었기 때문에, 전략 간의 실질적인 성능이나 효율성을 객관적으로 비교하기 어렵다는 한계가 있습니다. 저자들은 이러한 파편화된 평가 구조를 극복하기 위해 모든 전략을 통합적으로 비교할 수 있는 표준화된 벤치마크가 필요하다고 판단했습니다 [Figure 1].
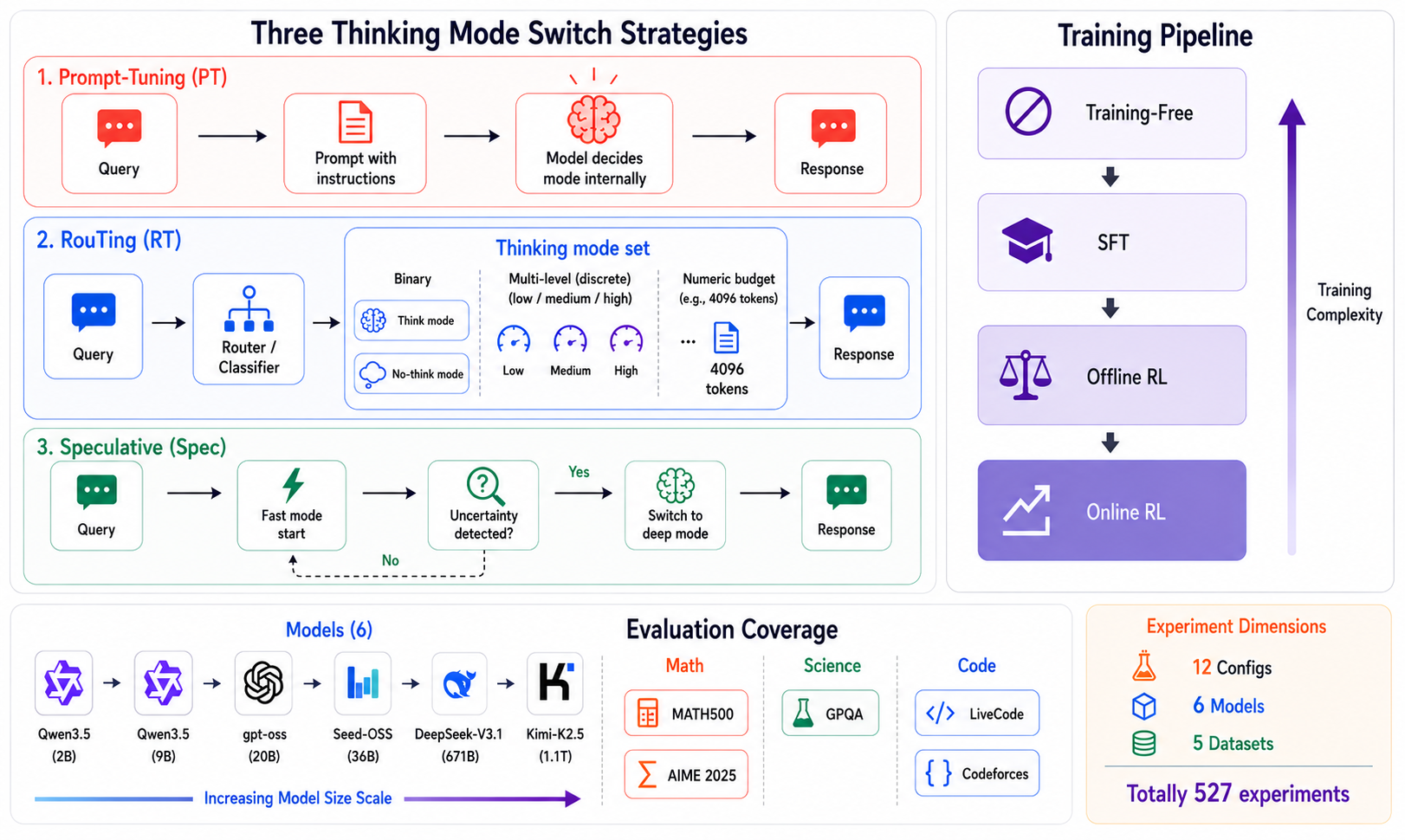
Figure 1 — HRBench 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Hybrid-Reasoning LLM의 추론 전환 전략을 평가하는 통합 프레임워크인 HRBench를 제안합니다. HRBench는 세 가지 전략(Prompt-Tuning, Routing, Speculative)과 네 가지 학습 방식(Training-Free, SFT, DPO, GRPO)을 직교 결합하여 12개의 통제된 평가 설정을 구성했습니다. 연구진은 6개의 LLM(2B~1.1T 파라미터)과 5개의 데이터셋을 활용하여 총 527번의 실험을 수행했으며, 12개 이상의 기존 연구 방법을 동일한 파이프라인에서 재구현했습니다 [Figure 1].
핵심 결과는 다음과 같습니다:
- 전략별 특성: Prompt-Tuning은 정확도와 토큰 절감 간의 Pareto-optimal trade-off를 달성하는 데 가장 유리하며, Routing은 정확도를 유지하면서도 안정적인 비용 감소를 보이고, Speculative는 추가 토큰 비용을 대가로 높은 정확도 향상을 도모합니다 [Figure 2].
- 규모 및 도메인 영향: 전략의 우위는 모델의 파라미터 크기와 태스크 도메인에 따라 변화하며, 예를 들어 코드 도메인에서는 Speculative 방식이 유효한 반면, 수학/과학 분야에서는 Prompt-Tuning이 더 효과적입니다 [Table 5, Figure 3].
- 학습 효과: 학습은 추론 자체의 성능보다는 모델이 불필요한 추론을 건너뛰는 능력을 향상시키며, 특히 GRPO는 Routing 전략에서 가장 높은 토큰 감소 효율을 달성했습니다 [Figure 4].
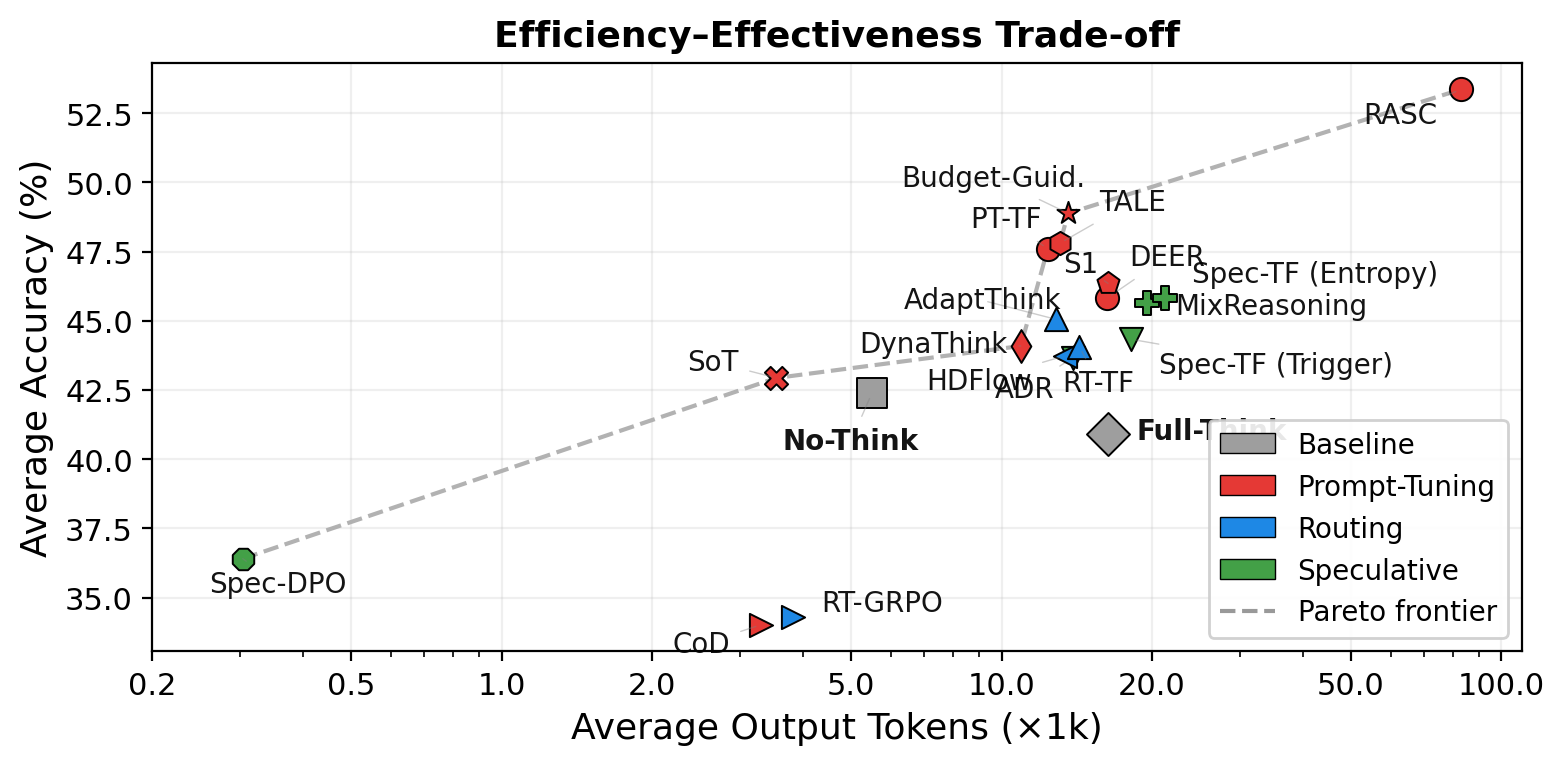
Figure 2 — 효율성-효과성 trade-off

Figure 4 — 학습 방식이 전환 전략에 미치는 영향
4. Conclusion & Impact (결론 및 시사점)
본 논문은 HRBench를 통해 다양한 추론 전략이 각기 다른 성능 프로파일을 가짐을 규명하고, 단일 전략이 모든 상황을 지배하지 않음을 증명했습니다. 이 연구는 모델 규모와 도메인에 맞는 적절한 효율화 전략을 선택해야 한다는 가이드를 제시하며, 향후 학계 및 산업계에서 비용 효율적인 고성능 추론 모델을 개발하기 위한 핵심적인 벤치마크 플랫폼이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LoSoNA: A Benchmark for Local Social Norm Adaptation in Group Conversations
- [논문리뷰] IntentGrasp: A Comprehensive Benchmark for Intent Understanding
- [논문리뷰] ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
- [논문리뷰] DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
- [논문리뷰] AthenaBench: A Dynamic Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Review 의 다른글
- 이전글 [논문리뷰] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
- 현재글 : [논문리뷰] HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
- 다음글 [논문리뷰] Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
댓글