[논문리뷰] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yi Jing, Zao Dai, Jinwu Hu, Zijun Yao, Lei Hou, Juanzi Li, Xiaozhi Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sparse Autoencoder (SAE): LLM의 hidden representation을 미세하게 분해하여 해석 가능한 희소(sparse) 특징으로 추출하는 mechanistic interpretability 도구입니다.
- SaeRL: SAE를 사용하여 학습 데이터의 Diversity, Difficulty, Quality를 모델링하고, 이를 기반으로 데이터 엔지니어링 전략(배치 구성, 커리큘럼, 필터링)을 최적화하는 프레임워크입니다.
- Moderate Batch Mixing: 클러스터 내의 일관성을 유지하면서도, 다른 클러스터와 일부 샘플을 교환하여 학습 과정에서 Diversity를 확보하고 모델의 일반화 성능을 높이는 전략입니다.
- Difficulty Proxy: SAE feature를 사용하여 샘플의 난이도를 예측하는 regressor로, 학습 초기부터 점진적으로 어려운 데이터를 학습하는 Curriculum Ordering을 가능하게 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM post-training에서 데이터 엔지니어링이 모델 성능 향상의 핵심임에도 불구하고, 기존 방식들은 주로 외부 피드백(인간 선호도, 보상 모델, rollout 결과 등)에 의존하여 비용이 높고 효율성이 제한적이라는 문제에서 출발한다. 모델 내부에 존재하는 데이터 처리에 관한 풍부한 정보는 데이터 엔지니어링에 충분히 활용되지 못하고 있다. 저자들은 모델의 Model Internals에 포함된 intrinsic signal을 활용하면 외부 피드백 없이도 효과적인 데이터 엔지니어링이 가능할 것이라고 가설을 세운다 [Figure 1]. 따라서 본 연구는 SAE를 활용하여 모델의 내부 상태로부터 유용한 정보를 추출하고, 이를 통해 post-training 과정을 최적화하는 방법을 제안한다.
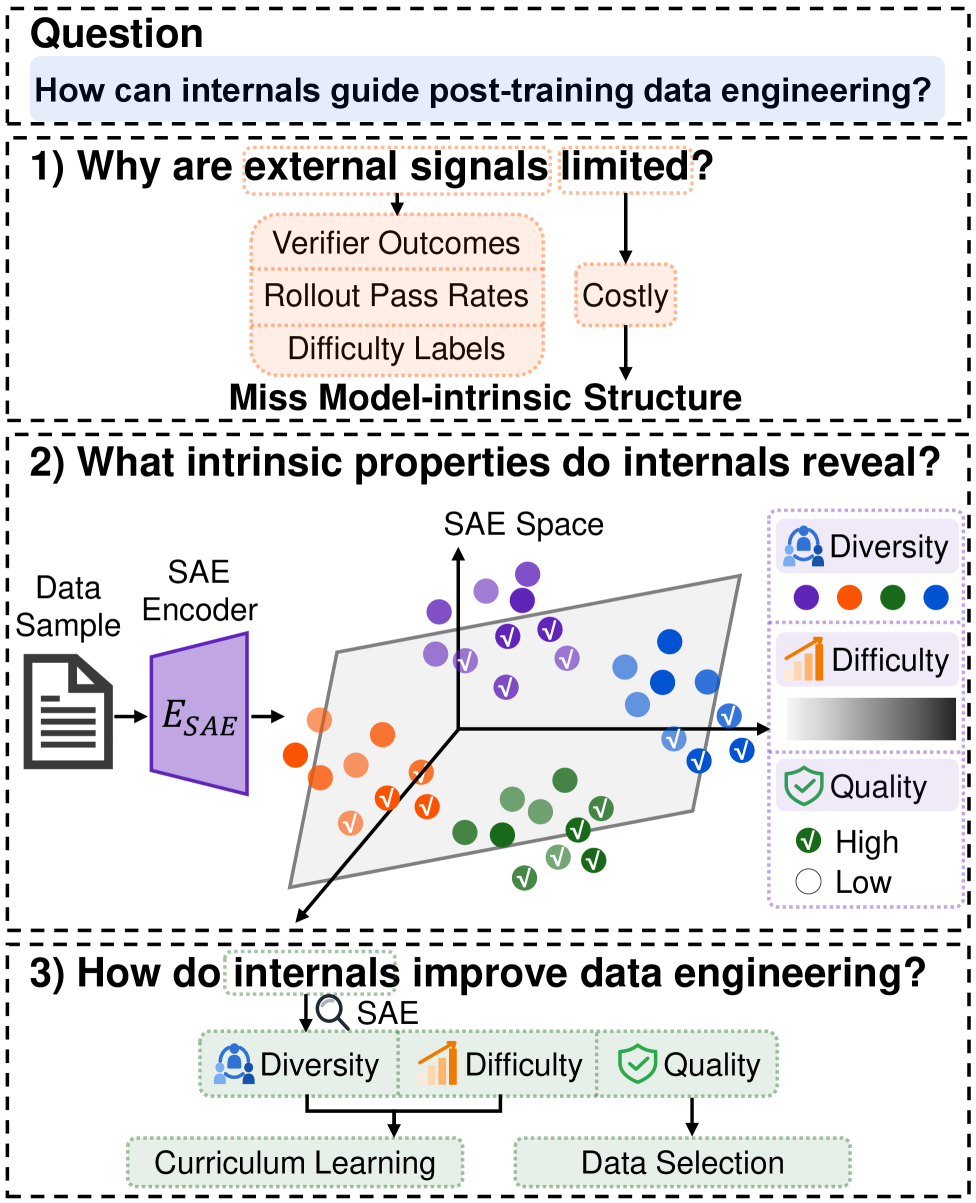
Figure 1 — SaeRL 개념 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SaeRL 프레임워크를 제안하며, 이는 모델의 내부 SAE activations를 모델링하여 Diversity, Difficulty, Quality를 도출하고 구체적인 데이터 엔지니어링 Operation으로 매핑한다 [Figure 2]. 데이터 Diversity를 위해 SAE 공간에서 클러스터링 후, Moderate Batch Mixing을 적용하여 배치 간 다양성을 조절한다. Difficulty는 학습된 ElasticNet regressor를 통해 추정하며, 이를 통해 easy-to-hard 방식의 커리큘럼을 구축한다. Quality 측면에서는 타겟 분포의 샘플을 식별하기 위한 Linear Classifier를 사용하여 저품질 데이터를 필터링한다. 실험 결과, Qwen2.5-Math-1.5B/7B 모델에서 SaeRL은 기존 GRPO 대비 평균 정확도를 3.00% 향상시켰으며, 20% 더 적은 학습 단계(training steps)로 목표 성능에 도달하는 성과를 보였다 [Table 4]. 또한, 다양한 RL 알고리즘과 모델 규모에서도 일관된 성능 향상을 입증하였다 [Table 5].
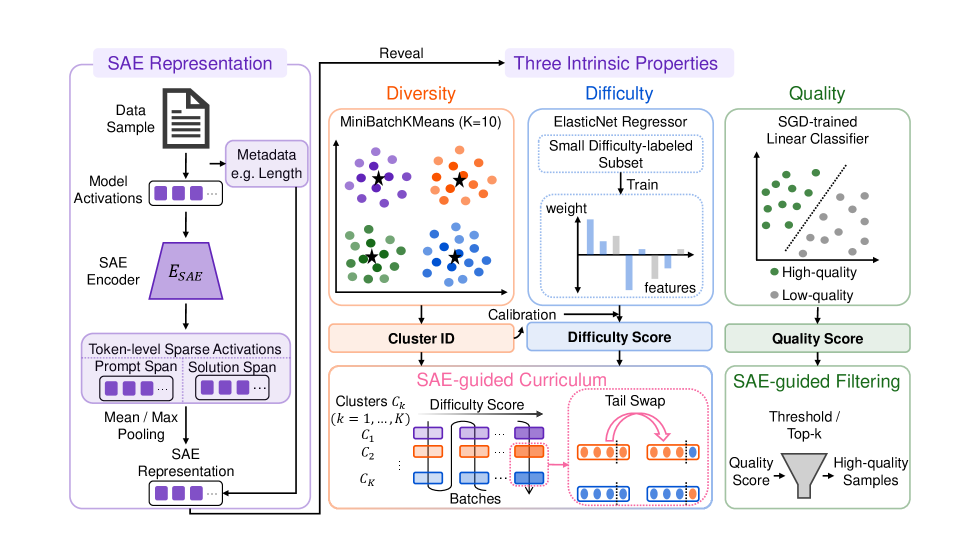
Figure 2 — SaeRL 파이프라인 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모델 내부의 Sparse Autoencoder 표현이 LLM post-training을 위한 강력한 데이터 엔지니어링 signal이 될 수 있음을 입증하였다. SaeRL 프레임워크는 외부 피드백에 대한 의존도를 낮추면서도 학습 효율과 최종 성능을 동시에 개선할 수 있음을 보여준다. 이 연구는 모델의 내부 상태를 해석하는 것을 넘어, 이를 직접적으로 학습 전략에 활용하는 'actionable mechanistic interpretability'의 가능성을 제시한다. 향후 연구는 더욱 다양한 도메인과 복잡한 환경에서의 적용 가능성을 탐구할 것으로 기대된다.
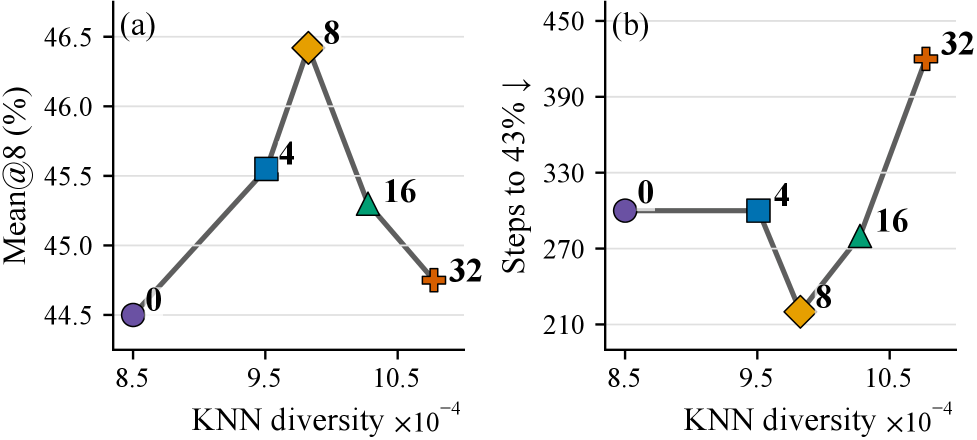
Figure 3 — 배치 다양성과 성능 관계
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Demystifying On-Policy Distillation: Roles, Pathologies, and Regulations
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
- [논문리뷰] Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
Review 의 다른글
- 이전글 [논문리뷰] GradSentry: Gradient Spectral Entropy for Backdoor Sample Filtering in Large Language Model Fine-Tuning
- 현재글 : [논문리뷰] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
- 다음글 [논문리뷰] HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
댓글