[논문리뷰] GradSentry: Gradient Spectral Entropy for Backdoor Sample Filtering in Large Language Model Fine-Tuning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haodong Zhao, Tianyi Xu, Tianhang Zhao, Zhuosheng Zhang, Gongshen Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Spectral Entropy: 본 논문에서 제안하는 지표로, 개별 샘플의 gradient 행렬 내 singular value 분포의 균일성을 측정하여 gradient 정보가 얼마나 다양한 방향으로 분산되어 있는지를 정량화합니다.
- lm_head: LLM의 최종 출력 projection layer를 지칭하며, 연구진은 이 모듈의 gradient가 backdoor 공격에 의한 출력 변조 신호를 가장 민감하게 포착한다는 점을 활용합니다.
- Truncated SVD: 고차원 gradient 행렬에서 상위 $k$개의 singular value만을 추출하여 계산 효율성을 높이고 노이즈를 제거하는 기법입니다.
- KDE (Kernel Density Estimation): 관측된 spectral entropy 점수들의 분포를 모델링하여, backdoor 샘플과 clean 샘플을 구분하는 임계값(Threshold)을 자동으로 탐색하는 통계적 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM fine-tuning 과정에서 발생하는 backdoor 공격을 효과적으로 탐지하고 제거하기 위한 새로운 filtering 기법을 제안합니다. 기존의 많은 샘플 filtering 연구들은 클러스터링(clustering) 기반의 접근 방식을 채택하고 있어, 대규모 데이터가 필요하거나 poisoned 샘플의 비율이 극단적일 경우 성능이 급격히 저하되는 한계가 있습니다 [Figure 1]. 또한, 이러한 방식들은 샘플 간의 pairwise 비교를 요구하여 연산 비용이 높고, 특정 fine-tuning 환경에 종속되는 경우가 많습니다. 따라서, 클러스터링을 배제하면서도 효율적이고 학습 방식에 구애받지 않는 강건한 방어 메커니즘이 필요합니다.
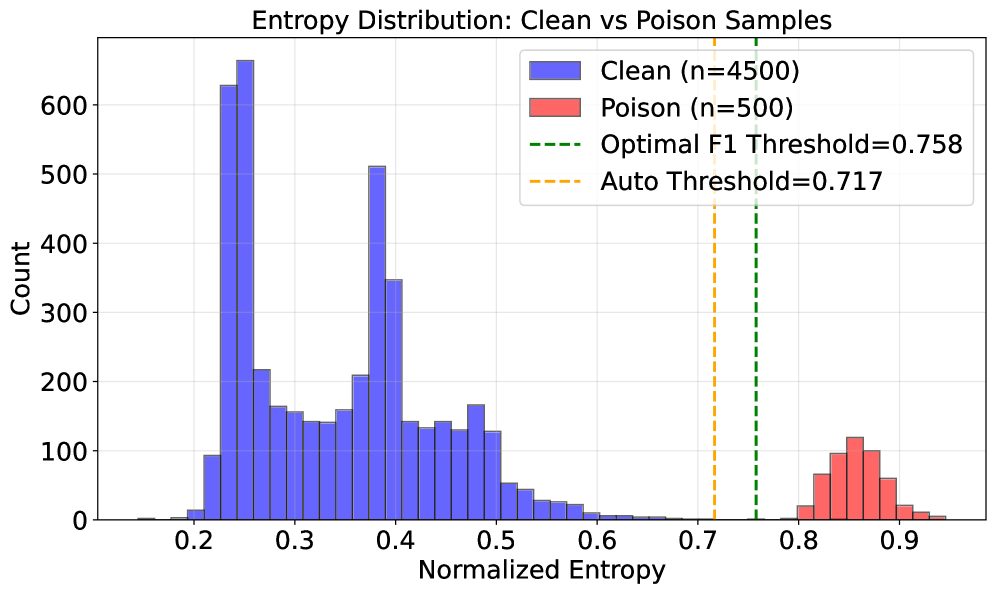
Figure 1 — GradSentry의 필터링 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 poisoned 샘플의 gradient가 clean 샘플 대비 더 높은 spectral entropy를 가진다는 핵심 통찰을 바탕으로 GradSentry를 제안합니다 [Figure 2]. 이 방법론은 각 샘플의 gradient를 lm_head로부터 추출한 뒤, Truncated SVD를 통해 상위 16개 singular value를 계산하여 spectral entropy를 산출합니다. 이후 KDE를 사용하여 전체 데이터셋의 entropy 분포에서 clean 샘플과 poisoned 샘플을 나누는 임계값을 자동으로 설정합니다. 실험 결과, GradSentry는 다양한 16가지 공격 환경에서 Attack Success Rate(ASR)를 0.00%로 완벽하게 억제하는 성과를 보였습니다 [Table 1]. 또한, 샘플 식별 성능 면에서도 100% Recall을 달성하며 기존 SOTA 기법인 GraCeFul보다 우수한 안정성을 입증했습니다 [Table 2]. 특히 1%에서 90%에 이르는 광범위한 poison ratio에서도 일관된 성능을 보이며, 데이터가 부족한 Low-Data Regime에서도 클러스터링 기반 모델들보다 압도적으로 우수한 robustness를 확인했습니다 [Figure 4].
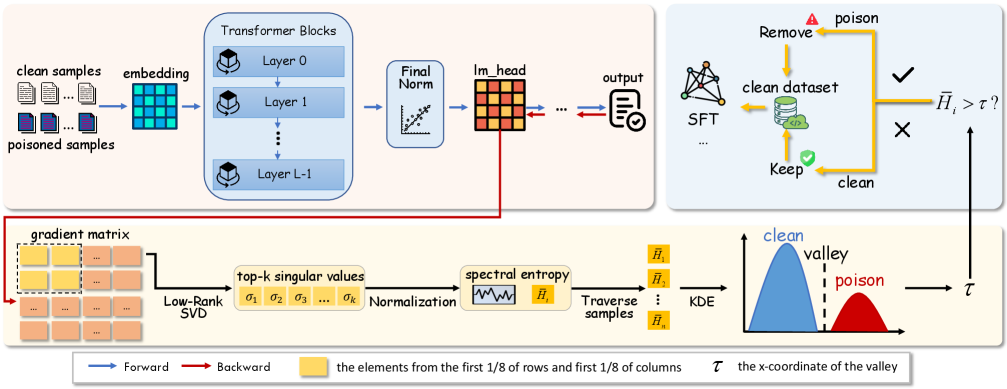
Figure 2 — GradSentry 파이프라인
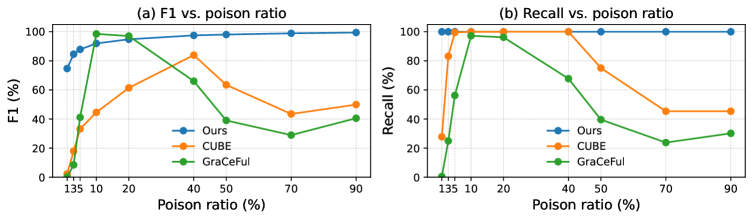
Figure 4 — 독률 변화에 따른 탐지 성능
4. Conclusion & Impact (결론 및 시사점)
본 논문은 gradient의 내재적 spectral 구조를 분석하는 것이 LLM backdoor 방어의 핵심적인 열쇠임을 입증했습니다. GradSentry는 복잡한 pairwise 비교나 클러스터링 과정 없이도 개별 샘플 단위의 정교한 필터링이 가능함을 보여주었으며, 이는 LLM fine-tuning의 안전성을 크게 향상시킬 수 있는 실용적인 도구입니다. 이 연구는 학계에 gradient 분석을 통한 모델 보안 프레임워크의 새로운 지평을 제시하였으며, 향후 다양한 생성형 모델 환경에서의 보안 강화 전략으로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RepSelect: Robust LLM Unlearning via Representation Selectivity
- [논문리뷰] AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
- [논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
- [논문리뷰] DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
- [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
Review 의 다른글
- 이전글 [논문리뷰] Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
- 현재글 : [논문리뷰] GradSentry: Gradient Spectral Entropy for Backdoor Sample Filtering in Large Language Model Fine-Tuning
- 다음글 [논문리뷰] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
댓글