[논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yangfan He, Yujin Choi, Jaehong Yoon, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Blind Trust Problem: 비디오의 품질 저하(Blur, Glare, Occlusion 등)를 고려하지 않고 모든 프레임을 동일한 신뢰도로 처리하여 reasoning 성능이 하락하는 현상을 의미합니다.
- Robust-TO: 프레임 단위의 신뢰도(Trustworthiness)를 명시적으로 평가하고, 이를 바탕으로 시각적 인식 도구들을 지능적으로 오케스트레이션하여 비디오 reasoning을 수행하는 에이전트 프레임워크입니다.
- GRPO (Group Relative Policy Optimization): Value network 없이 그룹 정규화된 보상을 통해 Advantage를 추정하여 정책을 최적화하는 강화학습 기법으로, 이 논문에서는 모델의 정확성, evidence 신뢰도, 효율성을 동시에 최적화하는 데 사용됩니다.
- Reliability-Relevance Score: 시각적 품질(Quality)과 쿼리 유사도(Query Relevance)를 결합하여 프레임을 선별하는 점수 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Video-LLM들이 실세계의 다양한 시각적 열화 환경에서 프레임별 신뢰도를 무시함으로써 발생하는 Blind Trust Problem을 해결하는 것을 목표로 합니다. 기존 모델들은 균일한 프레임 샘플링에 의존하며, 입력 데이터가 오염되었는지조차 인지하지 못한 채 추론을 진행하여 실제 성능이 크게 저하되는 한계가 있습니다. 이러한 silent failure는 자율주행이나 감시 시스템과 같은 안전이 중요한 분야에서 치명적인 오류로 이어질 수 있습니다. [Figure 1]에서 볼 수 있듯이, 기존 방식들은 무차별적인 샘플링으로 오염된 프레임을 그대로 reasoning 과정에 주입하여 결과를 왜곡하지만, 제안하는 방법론은 품질 프로파일링을 통해 신뢰할 수 있는 정보를 선별합니다.

Figure 1 — 기존의 무차별적 샘플링 방식과 본 논문의 품질 기반 선별 및 도구 라우팅 방식의 차이를 한눈에 보여주는 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Robust-TO 프레임을 통해 시각적 품질 평가, 도구 경로 설정(Tool Routing), 그리고 신뢰도 기반 증거 통합을 수행하는 3단계 파이프라인을 제안합니다. [Figure 2]와 같이 우선 assess_quality 도구를 통해 Blur, Brightness, Occlusion 수준을 프로파일링하고, 이를 바탕으로 가장 신뢰도 높은 프레임만을 필터링합니다. 이어지는 Confidence-Guided Tool Routing 단계에서는 GRPO를 활용하여 정확성(Correctness), 효율성(Sub-query efficiency), 신뢰도-비용(Confidence-cost)을 모두 최적화하며, 증거의 신뢰도(Confidence)와 프레임의 reliability를 결합한 (result, confidence) 인터페이스를 구축합니다.
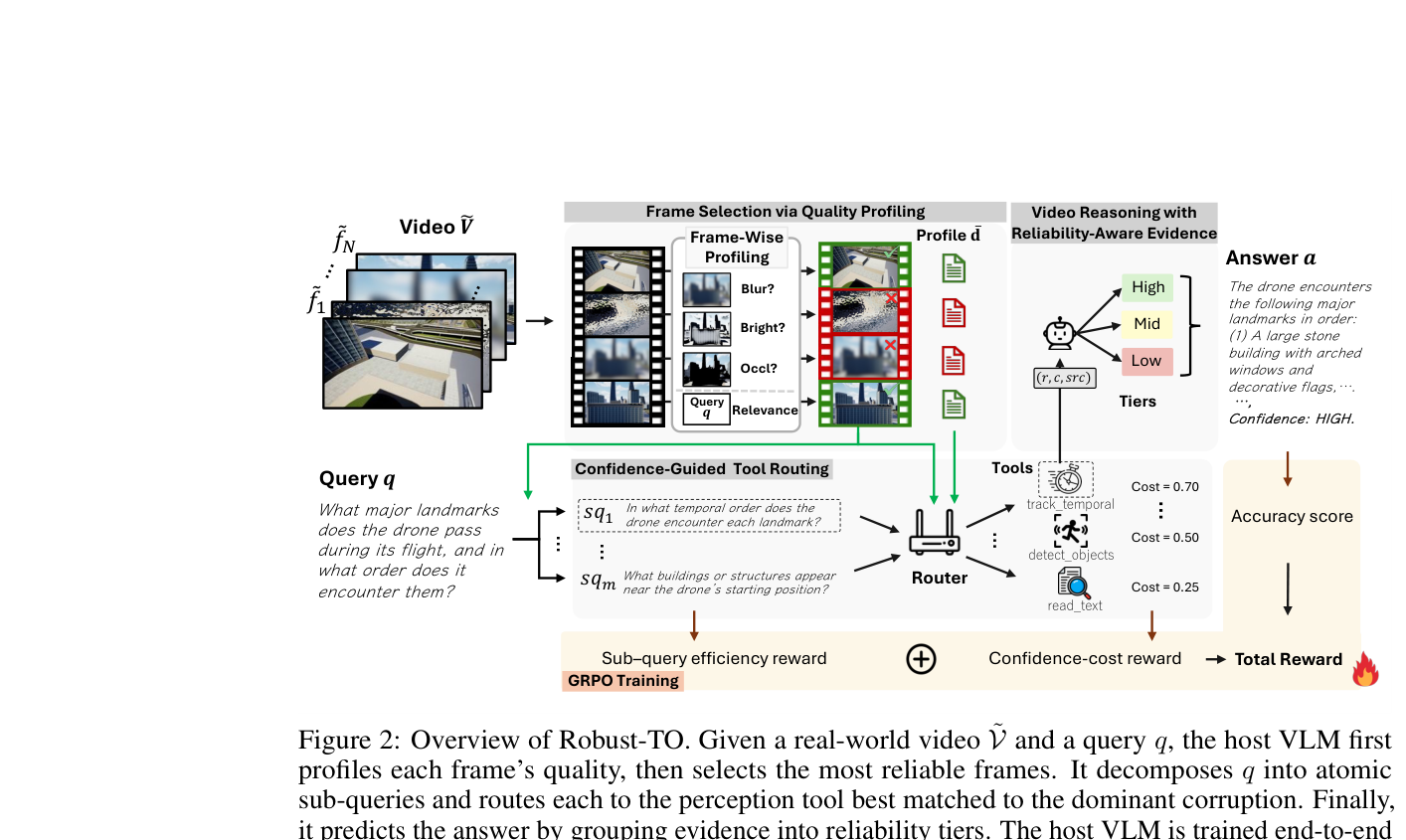
Figure 2 — 제안하는 전체 파이프라인(품질 프로파일링, 도구 라우팅, 신뢰도 기반 추론)을 상세히 설명하는 핵심 아키텍처 다이어그램
실험 결과, Robust-TO는 UrbanVideo-Bench 및 VSI-Bench에서 우수한 성능을 입증하였습니다. 특히 Qwen3-VL-7B를 백본으로 사용했을 때 클린 데이터 기준 56.4%의 평균 정확도를 기록하여, Gemini-2.5-Pro(46.2%)를 크게 상회하였습니다. [Table 2]에서 확인되듯, 다섯 가지 현실적인 corruption 환경에서도 Robust-TO는 54.3%의 평균 정확도를 유지하며 강력한 robust 성능을 보였습니다. 또한, 어댑티브 키프레임 선택 기법을 통해 처리 프레임 수를 기존 대비 35% 줄임과 동시에 정확도를 1.6%p 향상시켜 효율성까지 확보하였습니다.
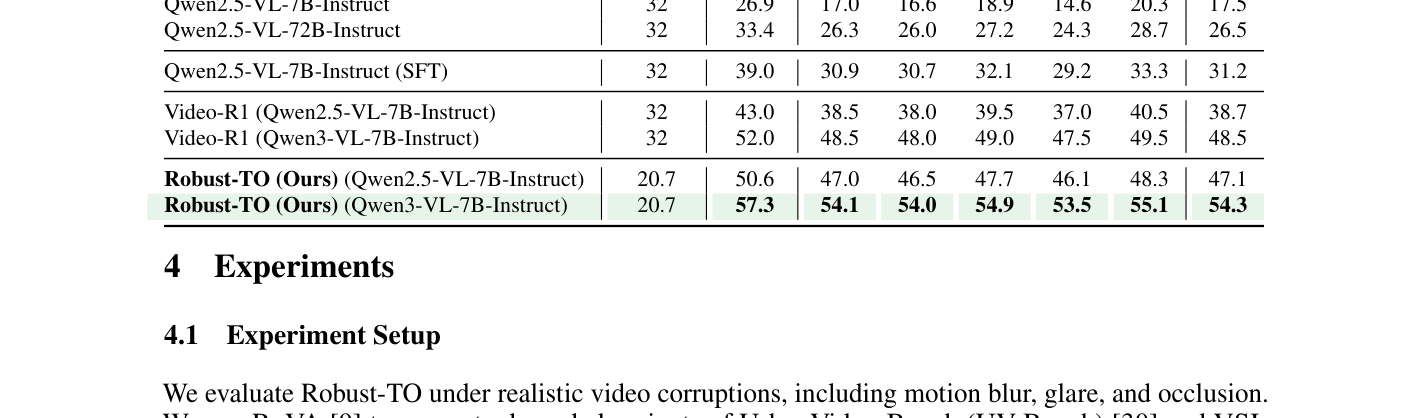
Table 2 — 다양한 영상 오염 환경에서 제안 모델의 뛰어난 성능 향상과 견고함을 보여주는 정량적 비교 데이터
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비디오 이해 분야에서 신뢰할 수 없는 데이터 처리에 의한 오작동 문제를 해결하기 위해 Confidence-Aware Tool Orchestration 프레임워크를 제안하였습니다. 본 연구는 입력 데이터의 시각적 품질을 직접적으로 추론의 신호로 활용함으로써, 더 안전하고 책임 있는(accountable) 영상 분석 시스템 구축의 기반을 마련했습니다. 본 연구에서 제시한 GRPO 기반의 강화학습 보상 설계와 도구 통합 인터페이스는 학계와 산업계의 비디오 reasoning 모델이 열악한 외부 환경에서도 견고하게 성능을 발휘하도록 유도하는 중요한 학술적 가치를 지닙니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
- [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
- [논문리뷰] DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
Review 의 다른글
- 이전글 [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- 현재글 : [논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
- 다음글 [논문리뷰] DanceOPD: On-Policy Generative Field Distillation
댓글