[논문리뷰] OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xinchen Zhang, Bowei Liu, Jiale Liu, Chufan Shi, Yizhen Zhang, Junhong Liu, Youliang Zhang, Zhiheng Li, Yujiu Yang, Ling Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Meta-Verification: 모델이 단순히 결과의 참/거짓(Binary Decision)만을 판단하는 것을 넘어, 오류의 원인이나 근거를 생성하여 이를 학습 목표로 활용하는 방법론입니다.
- Symbolic Rationale: 오류 발생 지점을 텍스트가 아닌
Bounding Boxes나Keypoints와 같은 구조화된 기하학적 형태로 명시하는 메타-검증 신호입니다. - RLVR (Reinforcement Learning with Verifier Rewards): Verifier의 출력을 기반으로 보상을 설계하여 강화학습을 수행하는 학습 패러다임입니다.
- Decoupled Reinforcement Learning: Binary Decision을 위한 보상과 Meta-Verification을 위한 보상을 각각 독립적인 학습 목표로 분리하여 최적화 효율과 안정성을 높이는 전략입니다.
- M1-TTS (Multimodal Agentic Generation): Verifier가 생성한 기하학적 근거와 편집 명령을 사용하여 Unified Multimodal Model(UMM)이 반복적으로 이미지를 수정하는 agentic 생성 시스템입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 multimodal verifier의 이진 판단 방식이 가진 coarse한 피드백의 한계를 해결하고자 합니다. 대부분의 기존 verifier는 binary 판단에 의존하여 fine-grained한 오류 localization이 어렵고, textual explanation을 사용할 경우 model-based judge에 의존해야 하므로 추가적인 연산 비용과 reward hacking 위험이 발생합니다. 저자들은 이러한 제약을 극복하기 위해 더 구조화되고 안정적인 메타-검증 피드백 메커니즘이 필요하다고 정의합니다 [Figure 1].
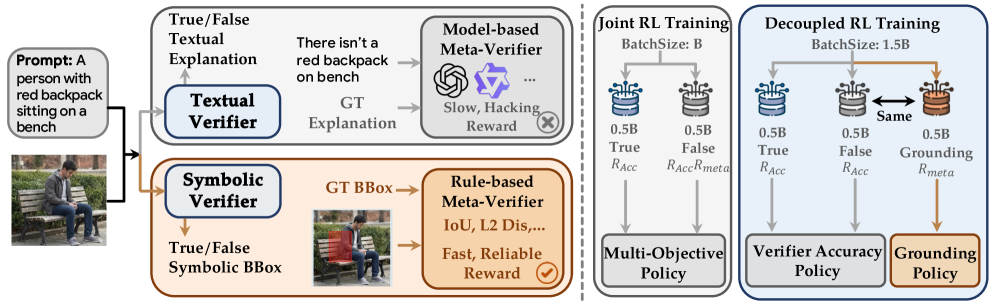
Figure 1 — 제안 방법론의 전체 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Symbolic Rationales 기반의 메타-검증과 Decoupled Reinforcement Learning이라는 새로운 학습 프레임워크를 제안합니다. 먼저, 텍스트 기반 설명 대신 Bounding Boxes와 같은 Symbolic 출력을 사용함으로써 rule-based 보상을 구현하여 reward hacking을 방지하고 계산 효율성을 극대화합니다 [Figure 2]. 또한, 이진 판단과 메타-검증이라는 이질적인 학습 목표를 하나의 보상으로 합치던 기존 joint training의 단점을 극복하기 위해, 이를 데이터셋 수준에서 분리하여 최적화하는 Decoupled 학습 전략을 도입합니다 [Figure 1]. 실험 결과, 제안 모델인 OmniVerifier-M1은 ViVerBench에서 기존 모델 대비 일관된 성능 우위를 보였으며, 특히 grounding 관련 태스크인 Bounding Box, Point, Counting 등에서 탁월한 정확도를 달성했습니다 [Table 1, Table 2]. 더욱이 M1-TTS 시스템은 WISE 및 T2I-CoreBench 벤치마크에서 반복적인 region-level self-correction을 통해 생성 품질을 획기적으로 향상시켰습니다 [Figure 4, Table 4].
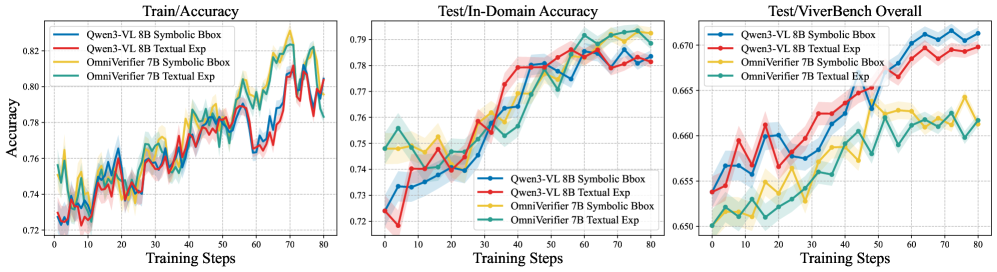
Figure 2 — 심볼릭 vs 텍스트 근거 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 multimodal 메타-검증의 핵심으로 symbolic 출력과 decoupled 강화학습 전략을 정립하여, 더 신뢰 가능하고 해석 가능한 시각적 검증 패러다임을 제시합니다. 이 접근 방식은 agentic generation 시스템이 복잡한 이미지 내 오류를 국소적으로 수정할 수 있게 함으로써, foundation model의 제어 가능성을 극대화하는 중요한 전기를 마련하였습니다. 향후 이 방법론은 일반적인 multimodal 생성 모델의 추론 및 편집 정확도를 개선하는 범용 프레임워크로 활용될 것으로 기대됩니다.
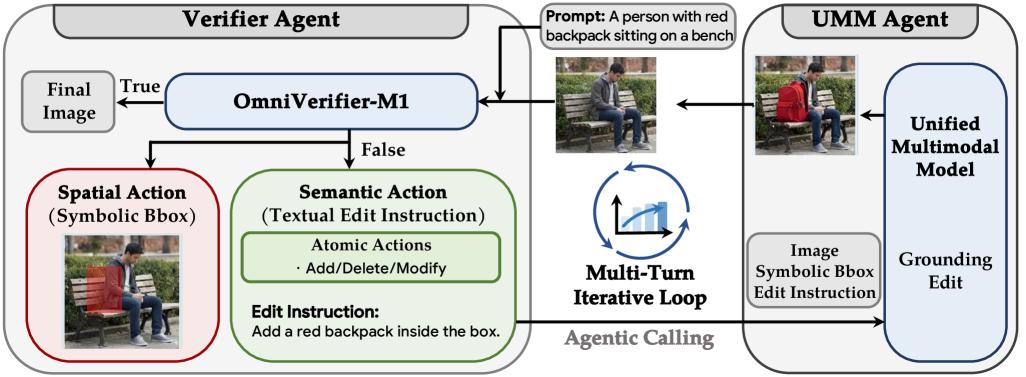
Figure 4 — M1-TTS 에이전트 생성 시스템
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
- 현재글 : [논문리뷰] OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
- 다음글 [논문리뷰] PEAM: Parametric Embodied Agent Memory through Contrastive Internalization of Experience in Minecraft
댓글