[논문리뷰] OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yunyang Ge, Xianyi He, Zezhong Zhang, Bin Lin, Bin Zhu, Xinhua Cheng, Li Yuan
1. Key Terms & Definitions (핵심 용어 및 정의)
- Skiparse-2D Attention: 영상의 공간적 지역성(spatial locality)을 보존하기 위해 기존 1D 패턴을 높이와 너비 차원으로 확장 적용하여, 토큰 상호작용의 효율성을 극대화한 sparse attention 메커니즘.
- Sparse Sequence Parallel (SSP): Skiparse-2D Attention의 로컬 등가성을 활용하여, sparse 패턴 전환 시 단 한 번의 All-to-All 통신만으로 데이터를 동기화함으로써 통신 비용을 75% 절감하는 병렬 처리 전략.
- HiF8 Quantization: 지수와 가수의 비트를 동적으로 할당하여 8-bit precision 환경에서도 넓은 dynamic range를 제공하며, 별도의 fine-grained rescaling 없이도 학습 안정성을 보장하는 8-bit 부동소수점 포맷.
- Mix-GRPO: Denoising 과정에서 초기 단계는 stochastic SDE, 후기 단계는 deterministic ODE를 혼합하여 샘플링함으로써, RL 학습 효율을 높이고 sparse 모델의 성능 저하를 방지하는 강화학습 기반의 정렬(alignment) 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Diffusion Transformers(DiTs) 기반 비디오 생성 모델이 가진 2차 복잡도의 연산 비용 문제를 해결하고, 고해상도 비디오 생성 효율을 높이는 것을 목표로 한다. 기존의 학습 기반 sparse attention 모델들은 복잡한 동적 토큰 선택 전략을 사용하여 FlashAttention 커널과의 결합이 어렵거나 하드웨어 부하가 크다는 한계가 있다. 또한, 기존 sequence parallelism 전략은 sparse attention 패턴과 결합할 때 불균형한 워크로드를 유발하여 연산 효율을 저해한다. 저자들은 이러한 문제를 극복하기 위해 통신 효율적이고 하드웨어 친화적인 새로운 비디오 생성 아키텍처인 OSP-Next를 제안한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Skiparse-2D Attention을 통해 비디오의 공간적 지역성을 활용하고, SSP를 적용하여 병렬 연산 효율을 극대화하는 프레임워크를 제시한다 [Figure 1], [Figure 3]. 모델 구조는 양 끝단의 full attention 계층과 중앙의 Skiparse 계층을 혼합한 spindle-shaped 설계를 채택하여 성능과 효율을 최적화하였다 [Figure 4]. 저자들은 HiF8 quantization을 적용하여 정밀도 손실을 최소화하는 동시에 8-bit 학습 환경을 구축하였으며, 최종적으로 Mix-GRPO를 통해 Sparse 모델 특유의 성능 하락을 보완하였다 [Figure 6]. 실험 결과, OSP-Next는 VBench 총점 83.73%를 기록하여 Wan2.1 baseline을 능가하는 성능을 입증하였다 [Table 1]. 특히, NVIDIA H200 GPU 환경에서 5초 길이 720P 영상 생성 시 최대 1.64배의 단일 GPU 속도 향상을 보였으며, Ascend 950PR 기반의 OSP-Next-HiF8 모델은 최대 2.27배의 추론 속도 개선을 달성하였다 [Table 2].
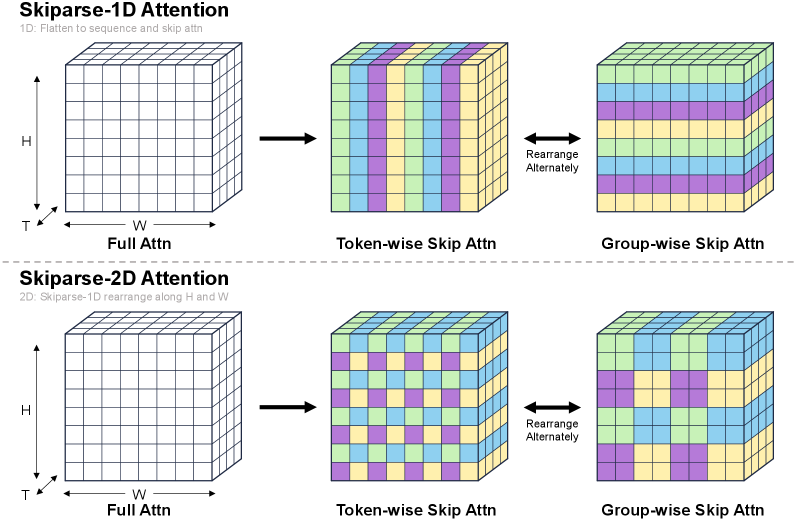
Figure 1 — Skiparse-2D Attention 메커니즘
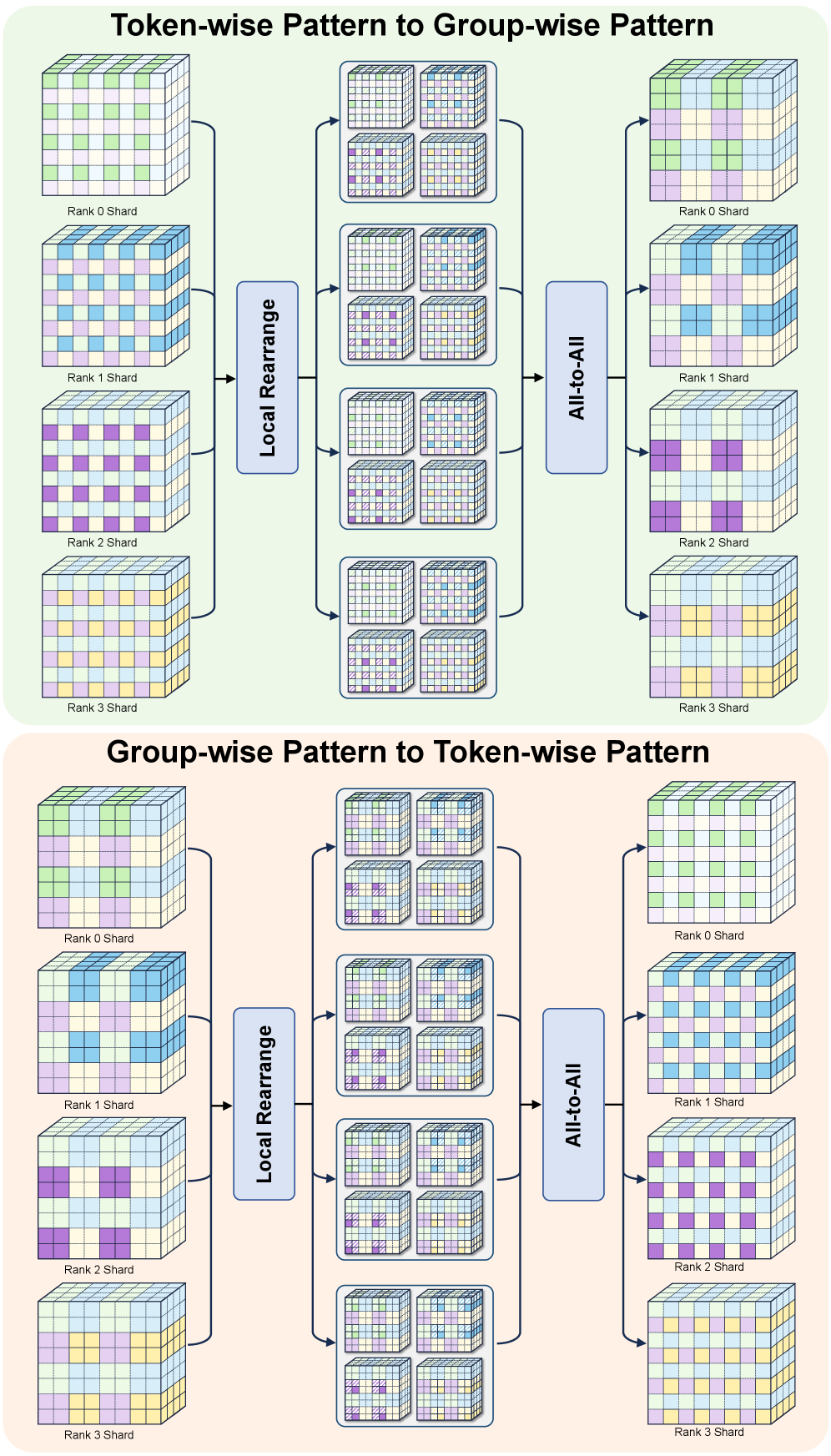
Figure 3 — Sparse Sequence Parallel (SSP) 워크플로우
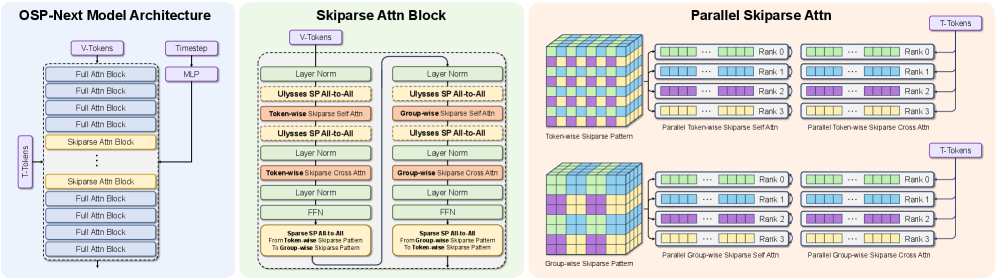
Figure 4 — OSP-Next의 하이브리드 모델 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 효율적인 sparse attention과 병렬화 전략, 그리고 정교한 quantization 및 RL 정렬 기법을 결합하여 고품질 비디오 생성의 새로운 파이프라인을 제시하였다. 제안된 OSP-Next는 하드웨어 플랫폼에 관계없이 일관된 성능 우위와 속도 향상을 보여줌으로써, 대규모 비디오 생성 모델의 실제 배포 가능성을 높였다는 점에서 중요한 시사점을 가진다. 본 연구는 향후 컴퓨팅 자원이 제한된 환경에서도 대규모 생성 모델을 효율적으로 운영하려는 학계 및 산업계 연구에 핵심적인 가이드라인을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LiteAttention: A Temporal Sparse Attention for Diffusion Transformers
- [논문리뷰] SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention
- [논문리뷰] EfficientRollout: System-Aware Self-Speculative Decoding for RL Rollouts
- [논문리뷰] OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
- [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
Review 의 다른글
- 이전글 [논문리뷰] Models That Know How Evaluations Are Designed Score Safer
- 현재글 : [논문리뷰] OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
- 다음글 [논문리뷰] OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
댓글