[논문리뷰] EfficientRollout: System-Aware Self-Speculative Decoding for RL Rollouts
링크: 논문 PDF로 바로 열기
메타데이터
저자: Minseo Kim, Minjae Lee, Seunghyuk Oh, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Rollout Generation: RL 학습 과정에서 정책 모델이 환경과 상호작용하며 응답을 생성하는 과정으로, 현재 RL 파이프라인에서 가장 큰 Latency 병목 지점입니다.
- Speculative Decoding (SD): 빠르고 가벼운 Drafter 모델로 후보 토큰을 생성하고, 타겟 모델이 이를 병렬로 검증(Verify)하여 추론 속도를 높이는 기법입니다.
- Self-Speculative Decoding (Self-SD): 별도의 외부 Drafter 모델 없이 타겟 모델의 일부 구조(Layer skipping, Quantization 등)를 활용하여 Drafter를 직접 구성하는 방식입니다.
- Block Efficiency ($\tau$): SD에서 Drafter와 타겟 모델의 한 번의 검증 사이클을 통해 평균적으로 생성되는 토큰의 수로, SD의 성능을 결정하는 핵심 지표입니다.
- Roofline Modeling: 연산 능력(Compute capacity)과 메모리 대역폭(Memory bandwidth)을 기반으로 시스템의 이론적 성능 한계를 분석하여 최적의 작동 regime을 결정하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 RL 학습 과정에서 발생하는 Rollout 생성의 고질적인 Latency 문제를 해결하기 위해 고안되었습니다. 기존의 Autoregressive (AR) 디코딩 방식은 응답이 길어질수록 순차적인 연산으로 인해 효율이 급격히 저하되며, 특히 학습이 진행됨에 따라 변화하는 정책 분포와 Rollout 후반부의 Shrinking-batch 현상이 시스템의 연산 자원 활용을 방해합니다. 기존의 SD 접근 방식들은 별도의 Drafter pretraining이 필요하거나 온라인 적응(Online adaptation)의 복잡성 문제로 인해 동적으로 변하는 RL 정책을 따라가는 데 한계가 있었습니다 [Figure 1]. 따라서 본 연구는 실시간으로 변화하는 정책에 적응하면서도 시스템 환경을 고려한 효율적인 SD 프레임워크 구축을 목표로 합니다.
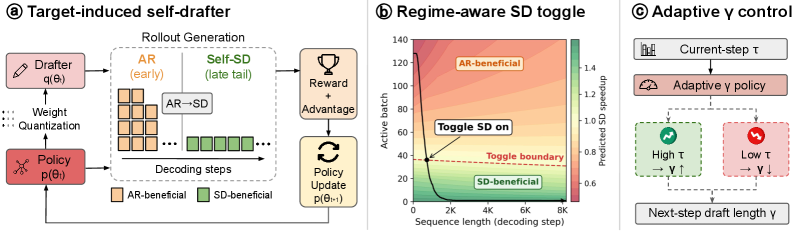
Figure 1 — EfficientRollout 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문에서 제안하는 EfficientRollout은 타겟 모델의 가중치를 양자화하여 Drafter로 사용하는 Weight-quantized 방식의 Self-SD 프레임워크입니다. 이 방법은 별도의 모델 학습 없이도 현재 타겟 정책과 완전히 동기화된 Drafter를 매 학습 단계마다 생성할 수 있습니다. 또한, Roofline Modeling을 기반으로 현재 디코딩 상태가 Compute-bound인지 Memory-bound인지를 판단하여 SD 사용 여부를 결정하는 Regime-aware SD toggle 정책을 도입하였습니다 [Figure 2]. 나아가 학습 과정에서 정책이 고도화됨에 따라 변화하는 수용률(Acceptance rate)을 측정하여 Adaptive draft-length를 실시간으로 조절함으로써 최적의 Block efficiency를 유지합니다. 실험 결과, EfficientRollout은 기존의 고속 AR 기준 대비 Rollout Latency를 최대 19.6%, 전체 End-to-End 학습 시간을 최대 12.7% 단축하면서도 최종 모델의 품질을 완벽하게 보존하였습니다.
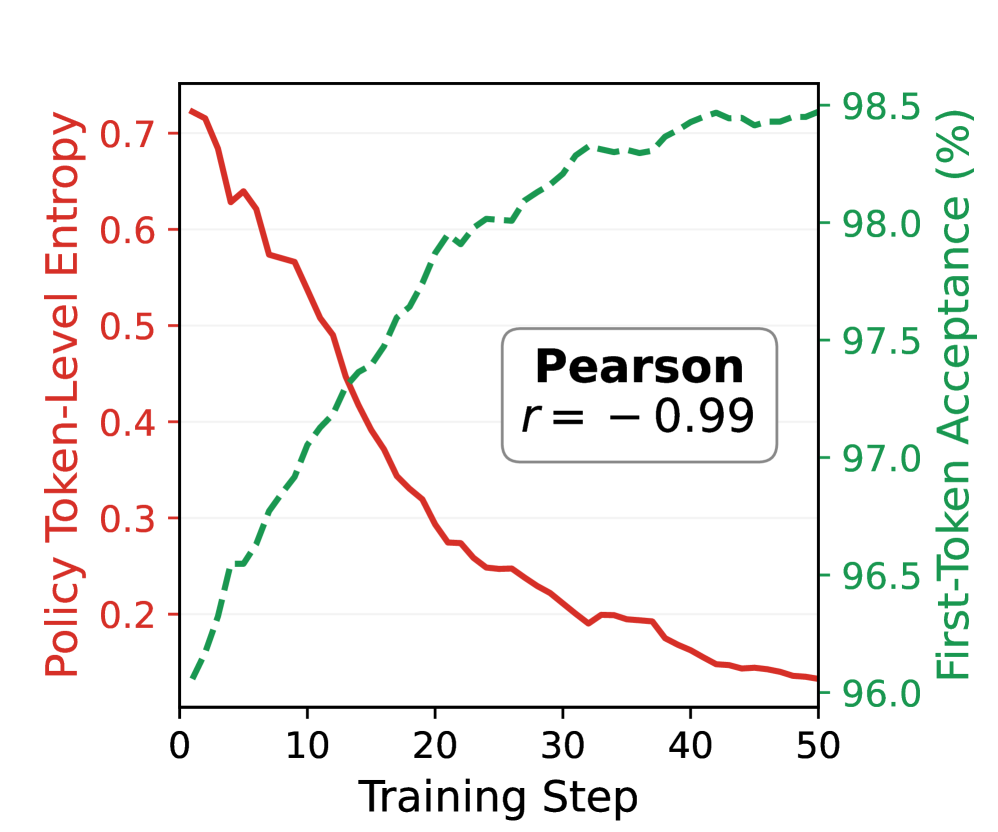
Figure 2 — RL Rollout의 디코딩 특성 분석
4. Conclusion & Impact (결론 및 시사점)
EfficientRollout은 RL Rollout 디코딩의 병목 현상을 시스템 인지적(System-aware) 관점에서 효과적으로 해결한 혁신적인 프레임워크입니다. 본 연구는 별도의 Drafter pretraining이나 복잡한 온라인 업데이트 없이도 타겟 모델 자체를 활용한 Quantized self-SD가 RL 학습 효율을 크게 향상할 수 있음을 입증했습니다. 이는 대규모 언어 모델의 RL 후학습(Post-training) 파이프라인에서 디코딩 오버헤드를 획기적으로 줄여, 더욱 빠르고 효율적인 모델 학습 환경을 제공할 것으로 기대됩니다. 또한 제안된 Roofline-based 토글 및 적응형 제어 정책은 범용적인 추론 및 학습 가속화 시스템 설계에 중요한 학술적 근거를 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
- [논문리뷰] OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Rethinking Shrinkage Bias in LLM FP4 Pretraining: Geometric Origin, Systemic Impact, and UFP4 Recipe
- [논문리뷰] DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
Review 의 다른글
- 이전글 [논문리뷰] CEO-Bench: Can Agents Play the Long Game?
- 현재글 : [논문리뷰] EfficientRollout: System-Aware Self-Speculative Decoding for RL Rollouts
- 다음글 [논문리뷰] Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
댓글