[논문리뷰] CEO-Bench: Can Agents Play the Long Game?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haozhe Chen, Karthik Narasimhan, Zhuang Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- CEO-Bench: 가상의 스타트업을 500일간 운영하며 에이전트의 장기 전략 수립 및 실행 능력을 평가하는 벤치마크 환경.
- Python Interface: 에이전트가 34개의
Tool을 사용하여 비즈니스 데이터를 분석하고 기업 경영 의사결정을 내릴 수 있도록 제공되는 프로그래밍 가능한 인터페이스. - Partial Observability: 에이전트가 시장의 진정한 상태나 고객의 잠재적 선호도를 직접 볼 수 없으며, 노이즈가 섞인 데이터를 통해 이를 추론해야 하는 환경적 제약.
- Delayed Consequences: 현재의 의사결정(예: R&D, 마케팅)이 즉각적인 성과로 이어지지 않고 시간이 지난 후 재무 및 평판에 영향을 미치는 동역학적 특성.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 에이전트 평가 방식이 단기 작업(Short-horizon tasks)에 치우쳐 있어, 실제 세계의 복잡한 의사결정 과정을 검증하지 못한다는 문제 의식에서 출발한다 [Figure 1]. 현대의 에이전트는 특정 태스크 수행에는 능숙해졌으나, 장기간에 걸쳐 변화하는 환경에 적응하고, 노이즈가 많은 데이터를 해석하며, 상호 연결된 다수의 변수를 통합하여 전략적 목표를 달성하는 데에는 여전히 한계를 보인다. 기존 연구들은 환경이 안정적이거나 즉각적인 피드백이 제공되는 좁은 범위의 시나리오에 국한되어 왔다 [Figure 4]. 저자들은 이러한 한계를 극복하기 위해 에이전트가 불확실성과 장기적 보상 구조 속에서 지속적인 적응과 전략적 판단을 내릴 수 있는 도전적인 환경인 CEO-Bench를 제안한다.
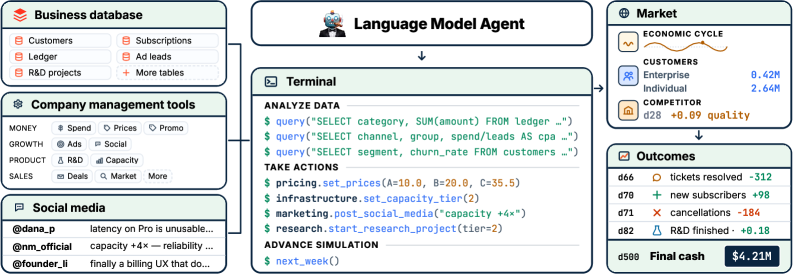
Figure 1 — CEO-Bench 환경 개요
Figure 4 — 스타트업 경영의 복잡성
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 에이전트가 500일간 가상의 기업 NovaMind를 운영하며 재무 제표, 데이터 분석, 시장 조사 등을 통해 최적의 경영 전략을 수립하도록 설계된 CEO-Bench 환경을 구축하였다. 이 환경에서 에이전트는 34개의 세분화된 도구를 사용하여 pricing, marketing, product development 등 다양한 경영 활동을 수행하며, 매 시점마다 데이터 분석과 파이썬 코딩을 통해 전략을 수정한다 [Table 1]. 주요 실험 결과, 대부분의 State-of-the-Art(SOTA) 모델들은 시뮬레이션 종료 전 파산하는 경향을 보였다 [Table 3]. 정량적으로는 오직 Claude Opus 4.8과 GPT-5.5만이 초기 자본금인 $1M 이상을 달성하며 시뮬레이션을 완료했으나, 이들조차 지속적으로 높은 수익을 창출하는 데에는 어려움을 겪었다 [Figure 2]. 모델 간 분석 결과, GPT-5.5와 Claude Opus 4.8은 전략적인 탐색을 지속하는 반면, 성능이 낮은 모델들은 수동적인 cash-preservation 전략에 머물러 있음을 확인하였다 [Figure 3].
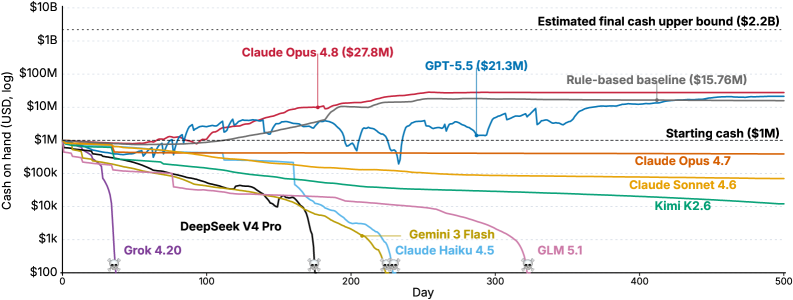
Figure 2 — 모델별 보유 현금 추이
4. Conclusion & Impact (결론 및 시사점)
본 연구는 CEO-Bench를 통해 에이전트의 지능을 장기적이고 복합적인 환경에서 평가할 수 있는 새로운 이정표를 제시하였다. 실험 결과, 최신 모델들조차 장기적 예측과 데이터 기반 전략 수정 능력에서 상당한 수준의 개선이 필요함을 시사한다. 이 벤치마크는 향후 자율 에이전트가 단순한 태스크 수행을 넘어, 실제 비즈니스나 복잡한 시스템 운영과 같은 고차원적인 지적 작업을 수행할 수 있도록 기술 발전을 이끄는 표준 평가 지표로 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
- [논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
- [논문리뷰] Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
Review 의 다른글
- 이전글 [논문리뷰] Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
- 현재글 : [논문리뷰] CEO-Bench: Can Agents Play the Long Game?
- 다음글 [논문리뷰] EfficientRollout: System-Aware Self-Speculative Decoding for RL Rollouts
댓글