[논문리뷰] Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shengyuan Ding, Xilin Wei, Xinyu Fang, Haodong Duan, Dahua Lin, Jiaqi Wang, Yuhang Zang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Non-Markov Game: 현재 관측값(Observation)만으로는 최적의 행동(Action)을 결정할 수 없으며, 과거의 히스토리를 통해 Hidden State를 추론해야 하는 게임 환경을 의미합니다.
- RNG-Bench: Reconstructive Non-Markov Games의 약자로, MLLM의 In-context State Tracking 능력을 평가하기 위해 제안된 벤치마크 스위트입니다.
- Memory Gap: 모델의 실제 성능과, 진실된 Hidden State 정보를 제공받았을 때의 성능 사이의 차이를 나타내는 지표로, 실패 원인이 '기억력(잊어버림)'에 있는지 '의사결정' 자체에 있는지 분별합니다.
- Closed-loop: 모델이 환경과 상호작용하며 매 단계 행동을 생성하고, 그 행동이 다음 관측값에 즉각적인 영향을 미치는 실시간 피드백 루프를 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM이 현재 눈에 보이는 정보 외에 과거의 관측값을 기억하고 이를 활용해야 하는 Non-Markov 상황에서의 한계를 해결하고자 합니다. 기존 벤치마크들은 은닉 상태를 재구성하는 능력과 다른 에이전트 기술들을 혼재시키거나, 에피소드가 끝난 후 기억을 테스트하는 방식으로 기억력을 제대로 격리하지 못했습니다. 특히 복잡한 상호작용 환경에서 하나의 기억 오류가 연속적인 관측값의 왜곡을 초래하여 에피소드 전반에 악영향을 미치는 remember-to-act 시나리오에서의 평가가 결여되어 있습니다 [Figure 1]. 따라서 저자들은 인위적인 혼동 변수를 제거하고 기억 능력만을 정밀하게 측정할 수 있는 새로운 벤치마크가 필요하다고 판단했습니다.
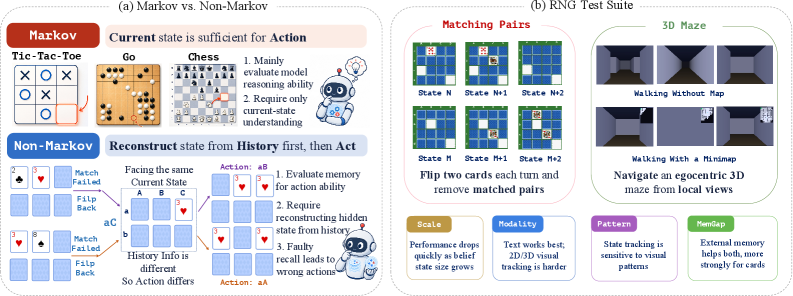
Figure 1 — RNG-Bench의 개념 및 게임 환경
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Matching Pairs와 3D Maze라는 두 가지 보완적인 환경으로 구성된 RNG-Bench를 제안합니다 [Figure 2]. Matching Pairs는 카드 위치와 기호를 기억하는 정적/범주적 상태 추적을, 3D Maze는 egocentric 시각 정보를 바탕으로 공간 지도를 구축하는 동적/공간적 상태 추적 능력을 평가합니다. 핵심 성과로, Memory Gap 지표를 도입하여 대부분의 실패가 복잡한 추론보다는 앞선 관측값을 잊어버리는 것에서 기인함을 정량적으로 입증했습니다. 실험 결과, 대규모 모델들조차 그리드 크기가 커짐에 따라 성능이 급격히 하락하며, 특히 텍스트 기반 관측과 달리 시각적 정보 처리 과정에서 Belief State 추적의 병목 현상이 발생함을 확인했습니다 [Figure 3]. 추가적으로, Qwen3.5-9B 모델에 시뮬레이터에서 획득한 최적 정책 데이터를 적용한 Supervised Fine-tuning(SFT) 결과, 성능 향상뿐만 아니라 외부 벤치마크로의 긍정적인 전이 효과(Transfer)를 보였습니다 [Table 7].
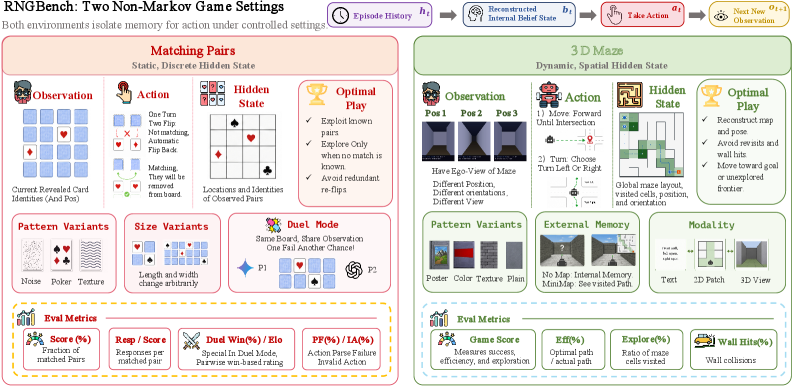
Figure 2 — 두 가지 핵심 환경 비교
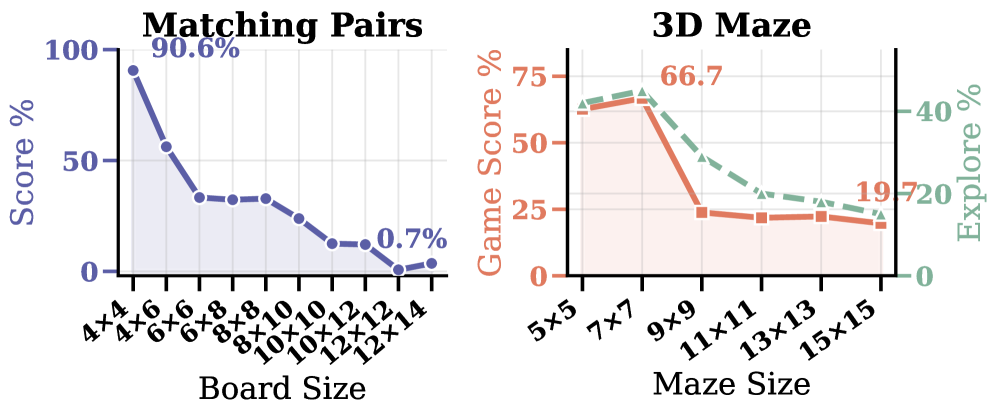
Figure 3 — 은닉 상태 스케일에 따른 성능 하락
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MLLM의 Non-Markov 환경 적응력을 평가하는 실용적인 프레임워크인 RNG-Bench를 제시함으로써, 미래의 Embodied AI 및 다중 턴 에이전트 모델의 핵심 역량인 In-context State Tracking 연구의 기반을 마련했습니다. 특히 모델의 행동 이력이 단순한 정보가 아닌 Belief State 유지를 위한 핵심 채널임을 밝혀낸 점은 향후 모델 설계에 중요한 시사점을 제공합니다. 이 연구는 MLLM이 단순한 시각-언어 모델을 넘어 실세계의 동적 환경에서 어떻게 기억을 유지하고 활용해야 하는지에 대한 정량적 가이드라인을 학계와 산업계에 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] IndustryBench-MIPU: Benchmarking Multi-Image Attribute Value Extraction for Industrial Products
- [논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
- [논문리뷰] LLM Agents Can See Code Repositories
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- [논문리뷰] Late-Layer Fusion is Enough: Dual-Path Vision Token Routing for Multimodal Large Language Models under Visual Saturation
Review 의 다른글
- 이전글 [논문리뷰] Beyond Alignment: Value Diversity as a Collective Property in Multicultural Agent Systems
- 현재글 : [논문리뷰] Beyond the Current Observation: Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
- 다음글 [논문리뷰] CEO-Bench: Can Agents Play the Long Game?
댓글