[논문리뷰] ResearchMath-14K: Scaling Research-Level Mathematics via Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guijin Son, Seungyeop Yi, Minju Gwak, Hyunwoo Ko, Wongi Jang, Youngye Yu, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- ResearchMath-14k: 학술 문헌에서 추출 및 정제하여 구축한 14,056개의 연구 수준(research-level) 수학 문제 데이터셋.
- Agentic Pipeline: Extractor와 Refiner 에이전트를 활용하여 비정형 문서에서 문제를 추출하고, 표준화된 형식으로 재구성하는 자동화된 파이프라인.
- ResearchMath-Reasoning: 다양한 모델들이 생성한 220K개의 수학적 추론 궤적(trajectories) 데이터셋.
- Factuality Metric: 생성된 추론 과정 내 인용(citations)이 실제 존재하는 문헌인지 확인하여 모델의 환각(hallucination)을 탐지하는 평가 지표.
- Agent-Judge: LLM을 에이전트로 활용하여 모델의 추론 과정이 올바른 lemma decomposition을 수행하는지, 혹은 허구의 인용을 포함하는지 정밀하게 분석하는 기법.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 최신 LLM이 기초적인 수학 경시 수준을 넘어 연구 수준(research-level)의 수학 문제를 해결하도록 유도하는 데 필요한 대규모 학습 데이터가 부족하다는 점을 해결하고자 한다. 기존의 공개 데이터셋은 대부분 경시대회 수준에 머물러 있거나, 평가용으로만 제한되어 있어 모델의 연구 수준 추론 역량을 강화하기 어렵다 [Table 1]. 또한, 최신 모델들은 연구 수준의 문제에 대해 피상적인 답변을 생성하거나 허구의 문헌을 인용하는 등 사실관계 오류가 심화되는 경향을 보인다. 저자들은 이러한 문제를 극복하기 위해 실제 수학적 문헌에서 추출한 문제들을 대규모로 확보하고, 이들을 정제하여 효율적인 학습 데이터로 변환하는 파이프라인을 제안한다 [Figure 2].
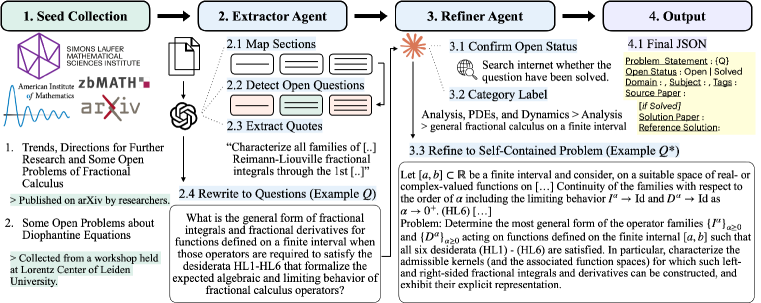
Figure 2 — 문제 추출 및 정제 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Extractor 에이전트가 다양한 학술 소스에서 후보 문제를 추출하고, Refiner 에이전트가 이를 누락된 정의와 배경지식을 포함한 독립적인 문제로 재구성하는 Agentic construction pipeline을 제안한다 [Figure 2]. 이후, 8개의 오픈 웨이트 모델로부터 생성된 220K개의 추론 궤적을 분석한 결과, newer generation 모델일수록 인용 횟수는 증가하지만 사실관계는 더 부정확해지는 "factuality-regression" 현상을 발견했다 [Figure 4]. 이러한 문제점을 보완하기 위해 Rule-based counter와 Agent-Judge를 결합하여 사실성이 검증된 ResearchMath-Reasoning-Filtered (5,000개 추론 궤적)를 생성하였다. 정량적 실험 결과, Qwen3 모델 시리즈(4B~30B)를 이 데이터셋으로 fine-tuning한 결과, 베이스 모델 대비 평균 9.2 점의 성능 향상을 기록하였다 [Figure 5]. 이는 정답이 검증되지 않은 복잡한 연구 수준 문제의 추론 궤적이라도, 잘못된 시도를 걸러내면 모델의 학습에 유용한 지도 신호(supervision signal)가 될 수 있음을 입증한다.
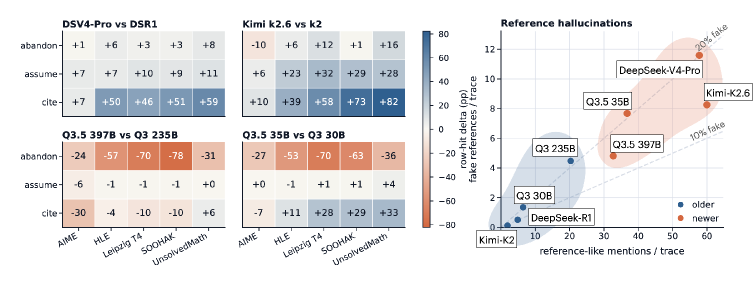
Figure 4 — 모델 세대별 인용 및 허위 사실 분석
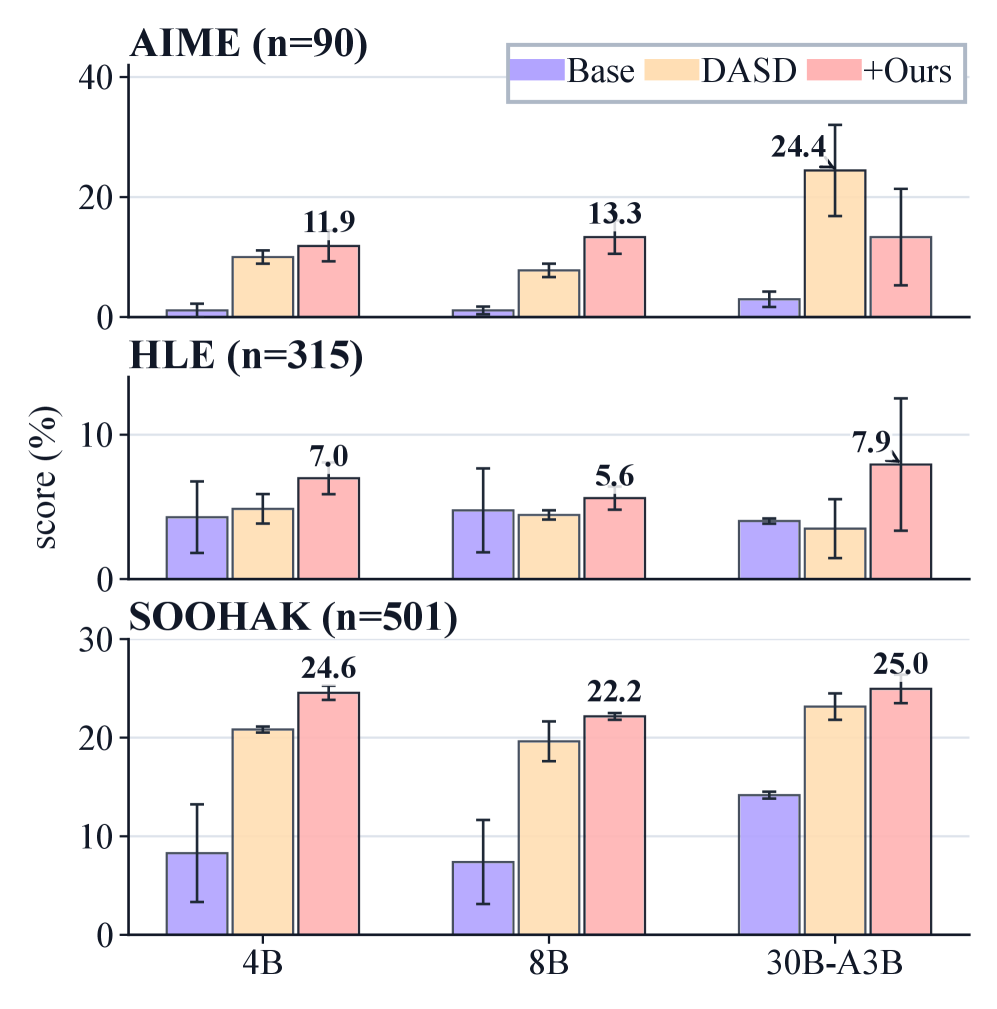
Figure 5 — 모델별 fine-tuning 성능 향상 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 연구 수준의 수학적 추론을 위한 최초의 대규모 데이터셋인 ResearchMath-14k를 구축하고 이를 활용한 분석 결과를 제시하였다. 연구 결과는 최신 LLM들이 인용의 스타일을 모방할 뿐, 실제 문제 해결을 위한 근본적인 lemma decomposition 능력을 갖추지 못하고 있다는 점을 시사한다. 그러나 이러한 불완전한 추론 과정조차도 엄격한 필터링을 거치면 모델 성능 개선에 유의미한 기여를 할 수 있다는 점을 확인했다. 본 연구의 결과물은 향후 더 높은 수준의 수학적 reasoning 모델을 개발하고, 에이전트 기반의 학습 데이터를 정제하는 파이프라인 구축에 중요한 지침이 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MixSD: Mixed Contextual Self-Distillation for Knowledge Injection
- [논문리뷰] Linear representations in language models can change dramatically over a conversation
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
Review 의 다른글
- 이전글 [논문리뷰] ProRL: Effective Reinforcement Learning for Proactive Recommendation via Rectified Policy Gradient Estimation
- 현재글 : [논문리뷰] ResearchMath-14K: Scaling Research-Level Mathematics via Agents
- 다음글 [논문리뷰] Rethinking Memory as Continuously Evolving Connectivity
댓글