[논문리뷰] Triplet-Block Diffusion RWKV
링크: 논문 PDF로 바로 열기
저자: Ke Lin, Yiyang Luo, Zhaolong Su, Yunya Song, Anyi Rao
1. Key Terms & Definitions (핵심 용어 및 정의)
본 논문에서 제안하는 방법론과 핵심 개념을 이해하기 위한 주요 용어 및 정의는 다음과 같습니다.
- Triplet-block layout: 엄격한 Causal LM(Causal Language Model)에서 diffusion training을 가능하게 하기 위해, 각 논리적 생성 블록(logical generation block)을 훈련 샘플 내에서 세 개의 연속적인 물리적 블록(masked copy
b1, lossable masked copyb2, clean ground-truth copyb3)으로 구성하는 방법론입니다. - Pseudo-bidirectional Access: Triplet-block layout을 통해 달성되는 메커니즘으로, 본질적으로 단방향인 엄격한 Causal LM이 논리적 블록 내에서 이전에 처리된
b1의 unmasked 토큰을 활용하여 masked 토큰에 대해 사실상 양방향 컨텍스트(bidirectional context)를 확보하는 방식입니다. - RWKV (Reinventing RNNs for the Transformer Era): Transformer급 성능을 달성하면서도 O(L)의 추론 효율성(inference efficiency)을 제공하는 Attention-free, Linear-time Recurrent Neural Network 아키텍처입니다.
- Discrete-diffusion Language Models: 엄격한 순차적 디코딩(strictly sequential decoding)을 피하고 양방향 Attention을 사용하여 토큰 블록을 병렬로 denoising하는 언어 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Causal Transformer Language Models(LLMs)가 겪는 두 가지 핵심 한계를 해결하고자 합니다. 첫째, 기존 Causal Transformer LLMs는 엄격하게 순차적인 디코딩(strictly sequential decoding) 방식 때문에 병렬화가 어렵고, 이는 생성 속도의 병목 현상으로 이어집니다. 둘째, Attention 메커니즘의 쿼드라틱 비용(quadratic per-step attention cost)은 장문 컨텍스트(long-context) 추론 시 높은 계산 비용을 발생시킵니다.
이러한 한계를 극복하기 위해 Linear-time causal models와 Discrete-diffusion models가 각각 대안으로 제시되었지만, 이들을 통합하는 데 내재적인 불일치(inherent inconsistency)가 존재합니다. Diffusion models는 양방향 Attention을 요구하는 반면, Causal models는 단방향(unidirectional) 특성을 가집니다. 따라서 저자들은 Linear-time causal models의 O(L) 추론 효율성(inference efficiency)과 병렬, 양방향 discrete-diffusion의 장점을 결합하여 표준 Transformer 대비 생성 효율성을 크게 개선할 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 엄격하게 Causal LM을 Diffusion LM으로 전환하기 위해 B^3^D-RWKV를 제안하며, 이는 모델 backbone 아키텍처를 변경하지 않는 triplet-block layout 방법론을 핵심으로 합니다 [cite: 1, Figure 1]. 훈련 과정에서 각 논리적 생성 블록 i는 마스킹된 b1(i), 손실 계산을 위한 동일한 마스킹된 b2(i), 그리고 다음 블록을 위한 recurrent state를 갱신하는 clean ground-truth b3(i)의 세 가지 물리적 블록으로 구성됩니다 [cite: 1, Figure 1]. 이 구조는 Causal 모델이 b1(i)를 통해 이미 처리된 unmasked 토큰들을 활용하여 b2(i) 내의 masked 토큰들에 대해 pseudo-bidirectional access를 가능하게 합니다. 추론 시에는 블록 단위의 반복적인 denoising(block-wise iterative denoising) 샘플러가 사용되며, 모델은 각 단계에서 상위 1개(top-1) 토큰의 확률이 신뢰도 임계값 τ를 초과하는 위치를 commit하면서 한 번에 하나의 논리적 블록을 생성합니다 [cite: 1, Figure 1].
B^3^D-RWKV-7.2B는 8가지 태스크 벤치마크 스위트(8-task suite)에서 기존 모델들과 비교할 만한 정확도를 달성합니다 [cite: 1, Table 1]. 특히 RWKV-7 baseline 대비 디코딩 Throughput에서 평균 1.6배의 유의미한 속도 향상을 보였습니다 [cite: 1, Figure 2]. 특정 벤치마크, 예를 들어 ARC-C 및 RACE에서는 B^3^D-RWKV가 다른 모델들을 능가하는 성능을 보였는데, 이는 pseudo-bidirectional access가 추론 능력(reasoning capabilities)을 향상시켰기 때문으로 분석됩니다 [cite: 1, Table 1]. 샘플링 파라미터를 조절하면 품질 저하를 최소화하면서 최대 2.02배의 속도 향상도 가능합니다. 또한, sampling steps와 **commit threshold τ**는 Throughput과 정확도(accuracy) 간의 trade-off를 조절하는 중요한 인자임이 확인되었습니다. 예를 들어, 32 steps 및 τ=0.9 설정에서 ARC-E 벤치마크에서 79.3%의 정확도와 213 tok/s의 Throughput을 달성했습니다 [cite: 1, Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 아키텍처 변경 없이 엄격하게 Causal LM을 Diffusion LM으로 전환하는 triplet-block layout 훈련 방법론을 성공적으로 제안했습니다. 이를 통해 개발된 B^3^D-RWKV는 기존 RWKV 모델 대비 평균 1.6배의 일반적인 Throughput 향상을 달성하면서도, 기존 모델들과 유사한 성능 수준을 유지했습니다. 이 연구는 사전 훈련된 Causal LM을 Diffusion LM으로 효율적으로 변환하는 새로운 방법을 제시함으로써, 해당 분야에 중요한 시사점을 제공합니다. 특히, Linear-time 모델의 효율성과 Diffusion 모델의 병렬 생성 능력을 결합하여 LLM의 추론 속도를 가속화하고, 빠른 생성이 요구되는 다양한 시나리오에서의 활용 가능성을 확장할 수 있습니다.
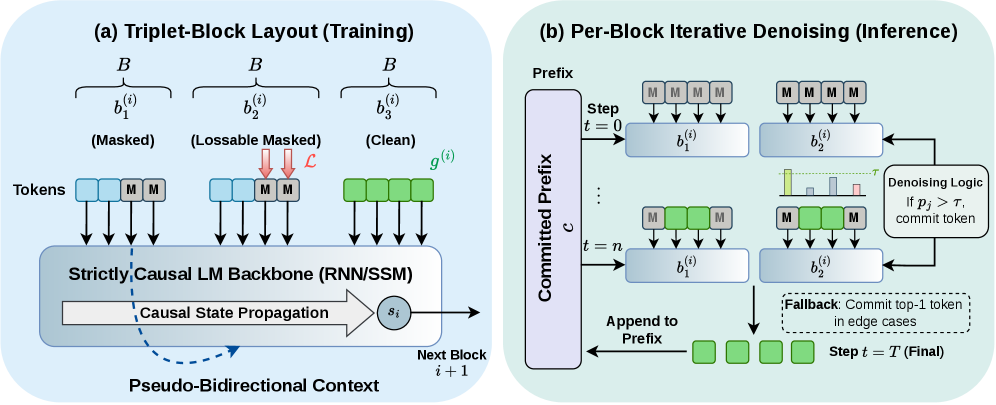
Figure 1 — 제안 방법론의 개요 및 추론 과정
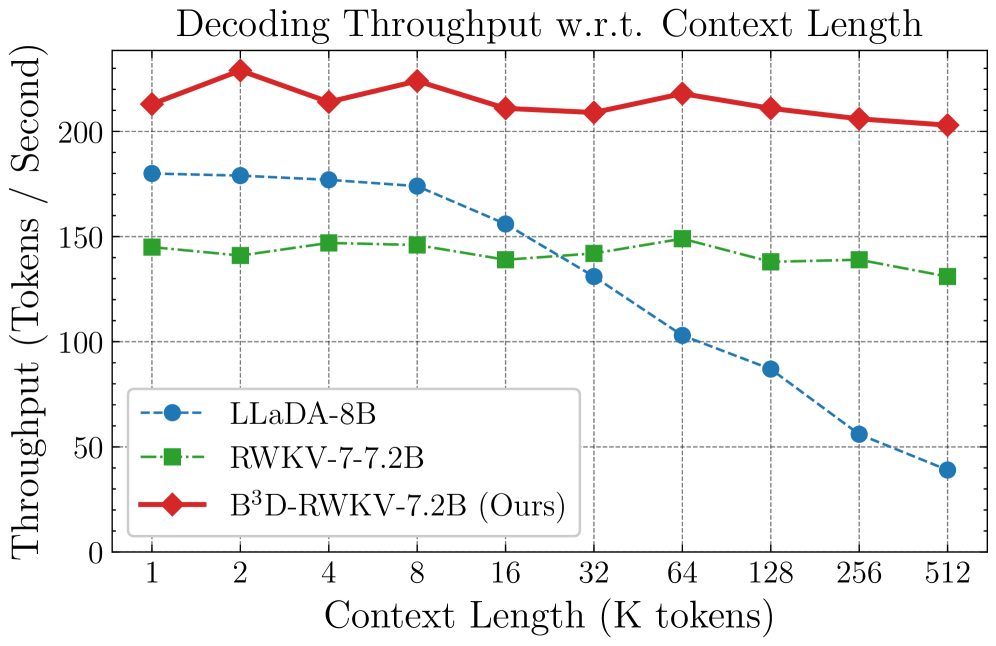
Figure 2 — 추론 Throughput 비교
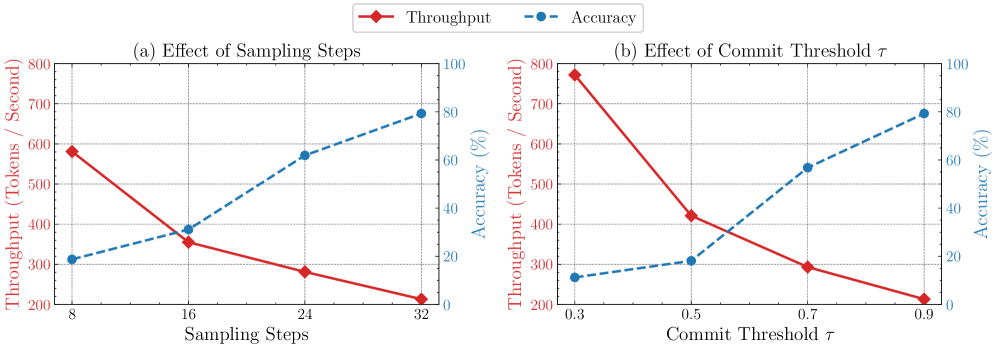
Figure 3 — Sampling 파라미터 영향
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] The Fragility of Chain-of-Thought Monitoring Across Typologically Diverse Languages
- 현재글 : [논문리뷰] Triplet-Block Diffusion RWKV
- 다음글 [논문리뷰] Verus-SpecGym: An Agentic Environment for Evaluating Specification Autoformalization
댓글