[논문리뷰] Multi-Block Diffusion Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yijie Jin, Jiajun Xu, Yuxuan Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-Block Diffusion (MultiBD): 단일 블록이 아닌 일련의 연속적인 블록(running-set)을 동시(concurrently)에 디코딩하여 inter-block parallelism을 달성하는 추론 방식입니다.
- Multi-block Teacher Forcing (MultiTF): BD-LM을 MBD-LM으로 변환하기 위한 post-training 방법론으로, 추론 시의 bounded running-set과 heterogeneous slot-wise noise pattern을 모사하는 훈련 상태를 구성합니다.
- Block Buffer: 물리적 입력 형태를 고정시켜 CUDA Graph를 활용한 효율적인 추론을 가능하게 하는 메커니즘으로, 가변적인 running-set을 관리하고 prefix-cache 호환성을 유지합니다.
- Train-Inference Alignment: 훈련 중의 노이즈 패턴과 실제 추론 시 모델이 접하게 되는 노이즈 패턴 사이의 불일치를 최소화하여 생성 품질과 효율성을 동시에 확보하는 개념입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 BD-LM이 단일 블록 단위의 순차적 디코딩으로 인해 발생하는 비효율성(storing bubbles) 문제를 해결하고자 합니다 [Figure 1]. 기존 Teacher Forcing은 한 번에 하나의 noisy block만 학습하여 MultiBD 추론 구조와 호환되지 않으며, Discrete Diffusion Forcing (D2F)은 추론 시의 제약된 실행 조건과 실제 훈련 상태 간의 불일치(mismatch)를 야기합니다 [Figure 3]. 이러한 불일치는 성능 저하뿐만 아니라 효율적인 하드웨어 가속을 저해하는 요인이 됩니다. 따라서 저자들은 추론 시의 제약 조건을 훈련 단계에 통합하여 MultiBD의 이점을 극대화할 수 있는 새로운 학습 및 추론 프레임워크를 제안합니다.
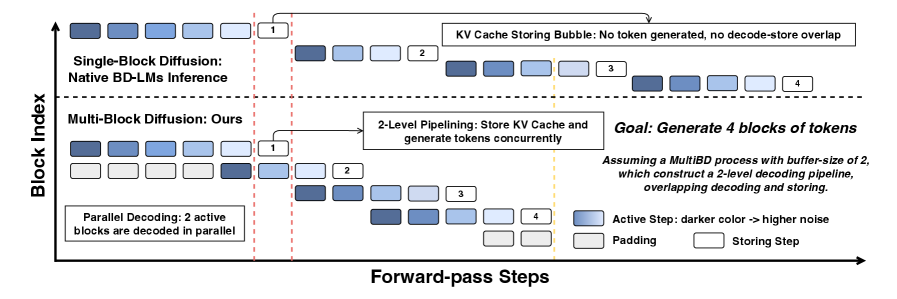
Figure 1 — SingleBD와 MultiBD의 병렬성 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Multi-block Teacher Forcing (MultiTF)를 통해 기존 모델을 MBD-LM으로 post-training하는 방법론을 제안합니다 [Figure 4]. MultiTF는 noise-group 단위의 훈련을 수행하며, 이때 Chain-uniform noise-scheduler를 도입하여 추론 환경과 유사한 slot-wise 노이즈 분포를 구현합니다. 또한, 효율적인 실행을 위해 Block Buffer를 도입하여 물리적 입력 형상을 고정(static-shape execution)시킴으로써 CUDA Graph 최적화를 구현합니다 [Figure 5]. 실험 결과, MBD-LLaDA2-Mini 모델은 이전 모델 대비 Tokens Per Forward pass (TPF)를 3.47에서 6.19로 약 78.4% 증가시켰으며, 정확도 또한 79.95%에서 81.03%로 향상되었습니다. 더불어 DMax와 결합한 MBD-LLaDA2-Mini-DMax 모델은 9.34의 TPF를 기록하며 높은 병렬성과 품질을 동시에 입증하였습니다.
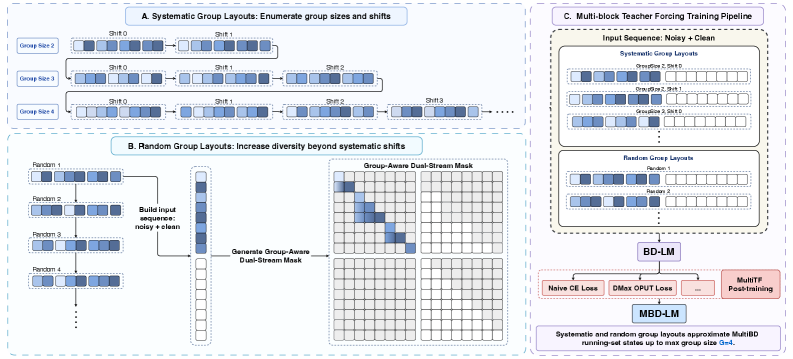
Figure 4 — MultiTF의 전체 훈련 과정
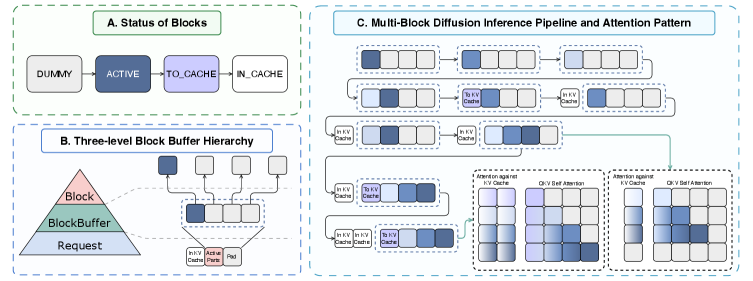
Figure 5 — MultiBD 추론 및 Block Buffer 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MBD-LM이라는 통합된 프레임워크를 통해 Diffusion Language Models의 병렬 디코딩 능력을 비약적으로 향상시켰습니다. 제안된 MultiTF와 Block Buffer는 훈련과 추론 간의 정렬을 최적화하여 대규모 언어 모델의 실무적인 추론 가속을 가능하게 합니다. 이 연구는 DLM 연구 분야에서 병렬성과 추론 효율성을 확보하기 위한 핵심적인 기술적 이정표를 제시하며, 향후 더 복잡한 생성 작업에 대한 Diffusion 기반 모델의 상용화 가능성을 높이는 데 기여할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
Review 의 다른글
- 이전글 [논문리뷰] MuSViT: A Foundation Vision Model for Sheet Music Representation
- 현재글 : [논문리뷰] Multi-Block Diffusion Language Models
- 다음글 [논문리뷰] Orca: The World is in Your Mind
댓글