[논문리뷰] Orca: The World is in Your Mind
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yihao Wang, Yuheng Ji, Mingyu Cao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Next-State-Prediction: 단순히 다음 토큰이나 프레임을 예측하는 것을 넘어, 세상의 상태(State) 전이를 모델링하여 물리 법칙과 인과 관계를 내재화하는 핵심 학습 패러다임입니다.
- Unconscious Learning: 레이블 없이 연속적인 비디오 데이터로부터 자연스러운 상태 전이를 학습하는 방식으로, 세상의 역학(Dynamics)을 내재화합니다.
- Conscious Learning: 언어적 명령이나 지시 사항을 조건으로 하여, 특정 이벤트 단위의 의미 있는 상태 전이를 학습하는 방식입니다.
- World Latent Space: 위 두 학습 방식을 통해 Encoder가 구축한 통합된 표현 공간으로, 다양한 하위 작업(Readout)의 인터페이스 역할을 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 일반적인 지능을 구현하기 위해 단순한 예측 모델을 넘어 세상을 이해하고 행동하는 General World Foundation Model인 Orca를 제안합니다. 기존의 LLM 기반 Next-Token-Prediction이나 영상 생성 모델의 Next-Frame-Prediction 등은 특정 작업에 특화되어 있어 물리적 세계의 동적 진화와 인과 관계를 포괄하는 데 한계가 있습니다. 저자들은 관찰 가능한 현상과 숨겨진 물리적 법칙을 모두 모델링하기 위해 Next-State-Prediction 기반의 새로운 접근 방식을 도입합니다 [Figure 1].

Figure 1 — Orca의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
Orca는 Encoder-Decoder 아키텍처를 기반으로 하며, 시각 및 언어 데이터를 활용해 World Latent Space를 학습합니다 [Figure 1]. 저자들은 dense한 자연 상태 전이를 배우는 Unconscious Learning과, instruction 기반의 sparse하고 의미 있는 전이를 학습하는 Conscious Learning이라는 두 가지 보완적 패러다임을 설계하였습니다 [Figure 2]. 프리트레이닝 후 Orca의 backbone은 고정(frozen)되며, 텍스트 생성, 이미지 예측, 행동 생성을 위해 경량화된 Modality-specific decoder만을 학습시켜 잠재 공간의 효과를 검증합니다 [Figure 4].
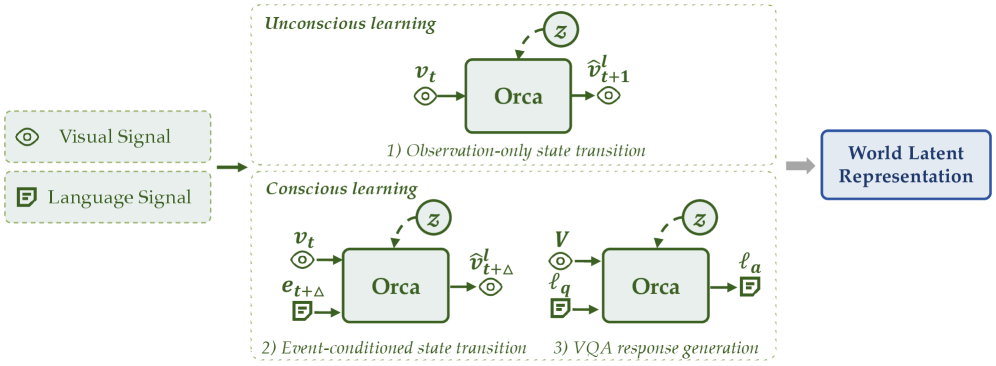
Figure 2 — Encoder 학습 패러다임
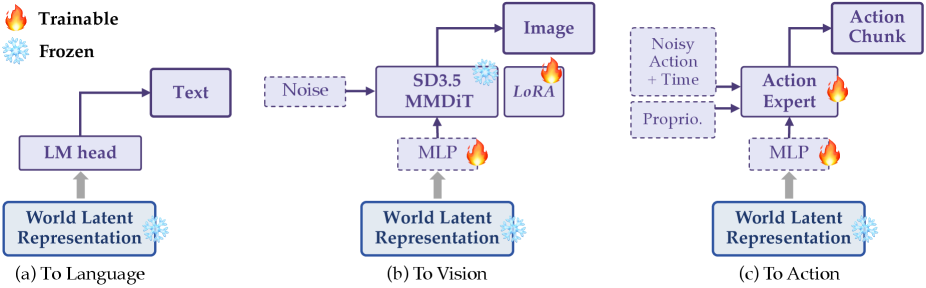
Figure 4 — Downstream Readout 구조
실험 결과, Orca는 모델 크기와 데이터 규모가 커짐에 따라 손실 함수 값이 지속적으로 감소하며 강력한 확장성(Scalability)을 보여주었습니다 [Figure 5]. 특히, 125K 시간의 비디오 데이터로 학습된 Orca의 latent space는 텍스트 생성, 이미지 예측, 행동 생성 등 다양한 downstream task에서 기존의 유사 규모 전문 모델들보다 우수한 성능을 기록했습니다 [Figure 6].
4. Conclusion & Impact (결론 및 시사점)
Orca는 일반적인 세계 모델(World Foundation Model)이 세상을 이해하고 예측하며 행동하는 데 필요한 통합적 학습 경로를 제시합니다. 본 연구는 상태 전이 모델링이 고차원적인 인지 능력을 발달시키는 데 효과적임을 입증하였으며, 특히 로봇 데이터가 부족한 상황에서도 비디오 데이터 기반 학습을 통해 embodied action 성능을 향상시키는 emergent capability를 확인했습니다. 이는 향후 일반 인공지능(AGI)을 향한 지속 가능한 세계 모델 개발에 중요한 지침이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
- [논문리뷰] TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
Review 의 다른글
- 이전글 [논문리뷰] Multi-Block Diffusion Language Models
- 현재글 : [논문리뷰] Orca: The World is in Your Mind
- 다음글 [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
댓글