[논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
링크: 논문 PDF로 바로 열기
메타데이터
저자: Koorosh Roohi, Javad Rajabi, Andrew Fleet, Babak Taati, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Photomosaics: 근거리에서는 개별적인 타일(이미지)들이 보이고, 원거리에서는 전체적으로 하나의 일관된 장면을 형성하는 합성 이미지 기법입니다.
- Bootstrapped Tiled Denoising: 저해상도에서 전체적인 레이아웃(Global structure)을 먼저 생성한 뒤, 이를 upscaling 및 renoising하여 개별 타일 단위로 독립적인 denoising을 수행하는 제안 방법론입니다.
- Global Coherence: 고해상도 생성 시에도 전체 장면이 의도한 타겟 구조를 정확하게 유지하는 특성을 지칭합니다.
- Tile Autonomy: 각 타일이 독립적으로 생성되어 그 자체로도 고품질의 의미 있는 이미지를 형성하는 성질을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 생성 모델이 고해상도 Photomosaic 생성 시 발생하는 전역 구조 유지와 타일 수준의 상세 묘사 사이의 상충(Trade-off) 문제를 해결하고자 합니다. 기존의 직접적인 고해상도 생성 방식은 계산 비용이 지나치게 높으며, 단순한 patch-based tiling 접근법은 타일 간의 조화가 부족하여 전역적인 구조를 상실하는 한계가 있습니다. 저자들은 Photomosaic이 요구하는 이중 스케일(Dual-scale) 특성을 만족시키기 위해 전역 구조와 국부적 타일을 분리하여 처리하는 새로운 프레임워크가 필요함을 명시합니다 [Figure 2].
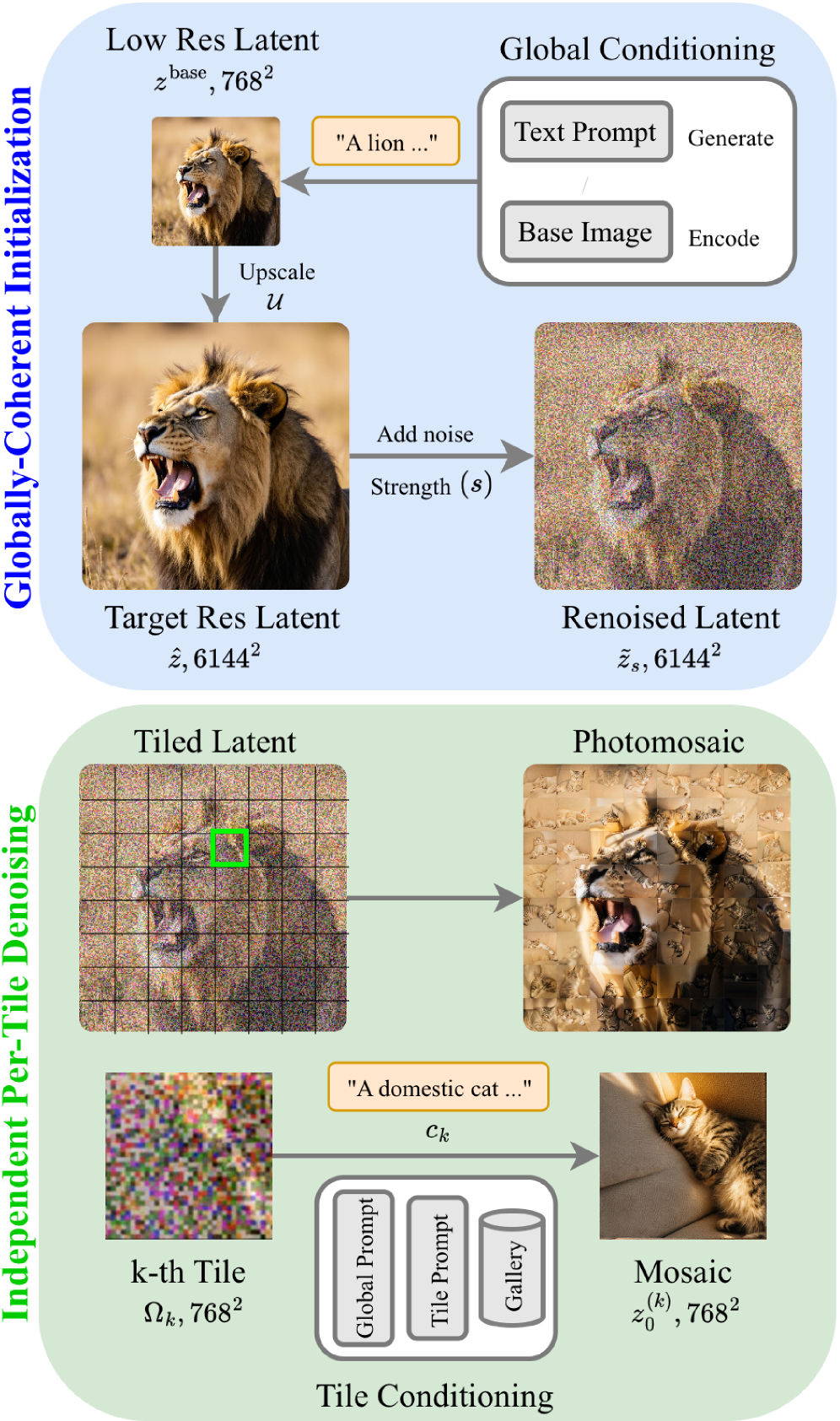
Figure 2 — PhotoQuilt 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 pretrained diffusion 모델을 별도의 학습 없이 활용하는 PhotoQuilt 프레임워크를 제안합니다. 먼저 저해상도에서 전체 타겟 레이아웃을 생성하여 z_base를 고정하고, 이를 upscaling한 뒤 noise를 재주입(re-inject)함으로써 모델이 타일별 상세 내용을 채울 수 있는 생성 능력을 확보합니다 [Figure 2]. 이후 각 영역(Tile)은 독립적인 경로로 denoising이 수행되므로 quadratic attention cost 문제를 회피하며 대규모 캔버스에서도 효율적인 생성이 가능합니다. 실험 결과, PhotoQuilt는 StreamDiff나 Phomosaic과 같은 기존 Baseline 대비 Global structure와 Local realism 양측에서 우수한 성능을 보였습니다 [Table 1]. 특히 FLUX.1 및 FLUX.2 백본을 사용했을 때 정량적 지표인 PSNR과 SSIM에서 월등한 구조 보존 능력을 입증하였으며, 정성적으로도 각 타일의 자율성을 완벽히 확보한 결과를 보여줍니다 [Figure 3], [Figure 4].

Figure 3 — 고해상도 Photomosaic 생성 예시

Figure 4 — 기존 모델과의 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 별도의 학습(Training-free) 없이 고해상도 Photomosaic을 생성하는 효율적이고 확장 가능한 프레임워크인 PhotoQuilt를 성공적으로 제시하였습니다. 제안된 bootstrapped tiled denoising 절차는 전역적인 레이아웃과 국부적인 타일 상세를 효과적으로 결합하여, 기존의 생성 기법이 직면했던 스케일 간의 상충 문제를 해소했습니다. 이 방법론은 다양한 diffusion 백본에 적용 가능한 범용성을 지니며, 향후 고해상도 합성 이미지 생성 분야 및 산업계의 복합 미디어 제작 프로세스에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
- [논문리뷰] Training-Free Multi-Concept LoRA Composition with Prompt-Aware Weighting
- [논문리뷰] Block Cascading: Training Free Acceleration of Block-Causal Video Models
- [논문리뷰] DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
- [논문리뷰] LightCache: Memory-Efficient, Training-Free Acceleration for Video Generation
Review 의 다른글
- 이전글 [논문리뷰] Orca: The World is in Your Mind
- 현재글 : [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
- 다음글 [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
댓글