[논문리뷰] LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
링크: 논문 PDF로 바로 열기
저자: Feng Han, Zhixiong Zhang, Zheming Liang, Yibin Wang, Jiaqi Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Carrier Sensitivity: 동일한 의미 정보가 텍스트에서 이미지(pixel) 형식으로 변환될 때 발생하는 모델 성능의 급격한 저하 현상을 의미합니다.
- Modality Gap: 텍스트와 이미지 표현 공간 사이의 비대칭적인 distributional gap으로, 모델이 의미적으로 동일한 내용을 서로 다른 carrier에서 일관되게 처리하지 못하게 하는 원인입니다.
- LoMo (Local Modality Substitution): 입력 텍스트 내 특정 span을 렌더링된 이미지로 대체하여, 'text → visual → text' 형태의 interleaved 시퀀스를 생성함으로써 cross-modal 표현의 불변성을 강제하는 데이터 구축 패러다임입니다.
- MIR (Modality Integration Rate): VLM의 디코더 레이어 내에서 시각적 토큰과 텍스트 토큰의 표현 분포 차이를 Fréchet Distance로 측정하여 cross-modal alignment 수준을 평가하는 지표입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 최신 VLM들이 텍스트 질문을 그에 대응하는 렌더링된 이미지로 교체했을 때 발생하는 성능 저하 문제, 즉 carrier sensitivity 문제를 해결하고자 합니다. 기존 연구(Baseline) 데이터셋은 텍스트는 쿼리(query)로, 이미지는 참조(reference)로 활용하는 비대칭적 역할을 수행하도록 구성되어 있어, 모델이 동일한 의미를 가진 서로 다른 carrier(텍스트 vs. 이미지)를 정렬하지 못하는 한계가 있습니다 [Figure 1]. 이러한 데이터 편향은 cross-modal alignment 부족으로 이어지며, 결과적으로 모델이 서로 다른 모달리티 사이의 표현 불변성(representational invariance)을 학습하지 못하는 치명적인 약점이 됩니다.
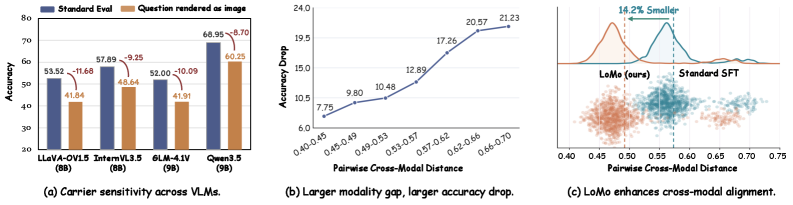
Figure 1 — Carrier sensitivity와 modality gap 현상
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 모델 구조 변경이나 추론 오버헤드 없이, 데이터 수준에서 cross-modal alignment를 강화하는 LoMo를 제안합니다 [Figure 2]. LoMo는 세 가지 단계를 거치는데, 먼저 입력 텍스트를 구조적으로 분석하여 중앙의 의미 단위 span을 추출하고(Structure-Aware Span Localization), 이를 텍스트 또는 LaTeX 렌더러를 통해 이미지로 변환한 뒤(Visual Rendering), 실제 문서 이미지에서 발생할 수 있는 노이즈를 반영한 Perceptual Distortion을 적용합니다. 이러한 변환을 통해 학습 목적 함수에 암묵적인 cross-modal alignment 항이 추가되어, 모델이 텍스트와 픽셀 사이의 깊은 결합을 학습하게 됩니다. 실험 결과, LoMo는 LLaVA-OneVision-1.5-8B 모델에서 Standard SFT 대비 2.67점, Qwen3.5-9B에서 2.82점의 성능 향상을 보였습니다 [Figure 3]. 특히, 동일한 linguistic content를 이미지로 전달하는 Rendered Evaluation 상황에서 성능 저하가 극적으로 완화되는 결과를 보였으며, paired cross-modal distance를 14.2% 감소시켜 강한 정렬 성능을 입증했습니다 [Figure 1].
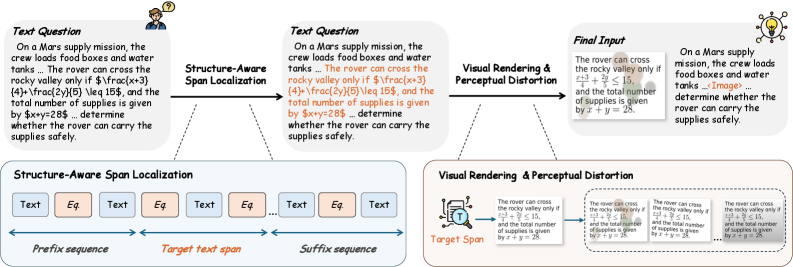
Figure 2 — LoMo 모델의 전체 아키텍처
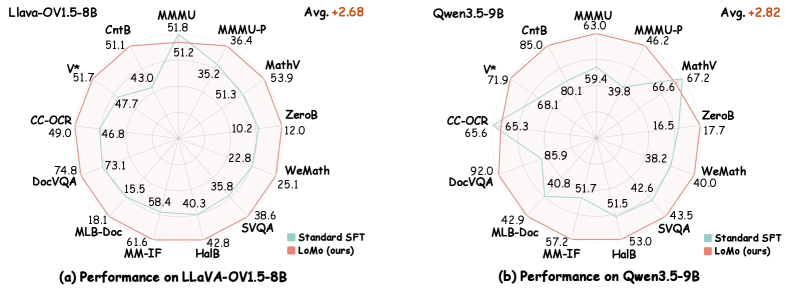
Figure 3 — Backbone 모델별 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 carrier sensitivity 현상이 VLM의 학습 데이터 내 불균형한 모달리티 역할에서 기인함을 규명하고, 이를 효과적으로 해결하는 LoMo 패러다임을 제안하였습니다. 이 연구는 architectural modification 없이도 모델의 깊은 cross-modal fusion을 유도할 수 있음을 입증하여, 학계와 산업계의 VLM 모델 학습 데이터 구축 방식에 중요한 지침을 제공합니다. 향후 LoMo는 문서 이해, Assistive reading, 다중 모달 추론 분야에서 보다 견고한 모델을 개발하는 데 핵심적인 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation
- [논문리뷰] SEED: Self-Evolving On-Policy Distillation for Agentic Reinforcement Learning
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] MedPMC: A Systematic Framework for Scaling High-Fidelity Medical Multimodal Data for Foundation Models
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
Review 의 다른글
- 이전글 [논문리뷰] LiteCoder-Terminal: Scaling Long-Horizon Terminal Environments for Learning Language Agents
- 현재글 : [논문리뷰] LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
- 다음글 [논문리뷰] MoZoo:Unleashing Video Diffusion power in animal fur and muscle simulation
댓글