[논문리뷰] MoZoo:Unleashing Video Diffusion power in animal fur and muscle simulation
링크: 논문 PDF로 바로 열기
저자: Dongxia Liu, Jie Ma, Xiaochen Yang, Jiancheng Zhang, Bin Xia, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- MoZoo: Coarse mesh input으로부터 고품질의 동물 fur와 muscle dynamics를 포함한 비디오를 생성하는 Generative Dynamics Solver 프레임워크입니다.
- RAR-RoPE (Role-Aware RoPE): 토큰의 기능(역할)에 따라 인덱스를 재매핑하여 다중 모달 입력 간의 정렬 문제를 해결하고, 참조 정보의 시간적 오프셋을 처리하는 기법입니다.
- Asymmetric Decoupled Attention (ADA): 잠재 시퀀스를 기능적 세그먼트로 분할하고, 타겟 쿼리가 구조적 가이드와 텍스처 정보에 효율적으로 접근하도록 제한하여 정보 간섭을 방지하는 어텐션 메커니즘입니다.
- MoZooBench: 120개의 메쉬-비디오 쌍으로 구성된 동물 영상 생성 성능 평가를 위한 종합적인 벤치마크 데이터셋입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
- 전통적인 CG (Computer Graphics) 파이프라인에서 동물의 fur와 muscle dynamics를 시뮬레이션하는 작업은 고도의 전문성과 막대한 컴퓨팅 자원을 요구하는 노동 집약적인 과정입니다.
- 기존의 Diffusion Models 기반 방법론들은 주로 인간 피사체에 최적화되어 있거나 정적 이미지 기반의 참조에 의존하여, 동물 특유의 복잡한 기하학적 구조와 역동적인 fur 움직임을 고충실도로 생성하는 데 한계가 있습니다.
- 이러한 물리 기반 수정 단계의 복잡성을 해소하기 위해, 저자들은 coarse mesh를 입력받아 실사 수준의 동물을 생성하는 MoZoo 프레임워크를 제안하며, 전통적인 방식과 차별화되는 효율적인 생성 방식을 [Figure 2]를 통해 시각화하여 제시합니다.
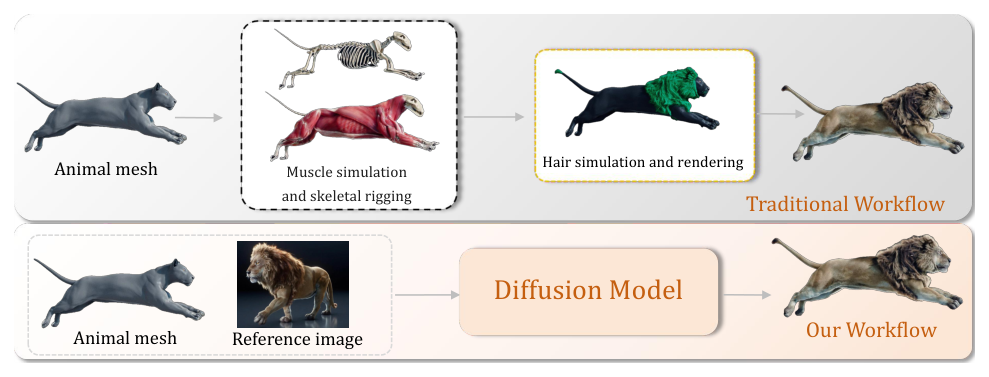
Figure 2 — 전통적인 시뮬레이션 파이프라인과 MoZoo 프레임워크의 차이를 보여주는 비교 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
- MoZoo는 Wan2.1을 백본으로 하며, RAR-RoPE를 통해 메쉬 동선과 참조 데이터 간의 정렬을 동기화하고 Asymmetric Decoupled Attention (ADA)를 통해 구조적 정보와 텍스처 정보를 명시적으로 분리하여 처리합니다.
- 본 방법론은 텍스트 프롬프트, 이미지, 비디오 등 다중 모달 입력을 통해 동물의 외형과 움직임을 제어하며, 특히 참조 비디오 내의 동적인 질감을 타겟 메쉬에 고충실도로 전송하는 데 탁월한 성능을 보입니다.
- MoZooBench 기반 정량 평가 결과, Ours (Video) 모델은 Subject Consistency 점수에서 97.84, SSIM은 0.922를 달성하여 기존 기법인 VACE 및 Refacade 대비 전반적인 지표에서 우수한 성능을 입증했습니다 [Table 1].
- 특히, LPIPS 수치에서 가장 낮은 값을 기록하며 참조 데이터와 시각적 유사도가 압도적으로 높음을 증명했고, 다중 모달 입력 체계 하에서 PSNR 값 역시 20.75로 가장 높은 수치를 기록했습니다.
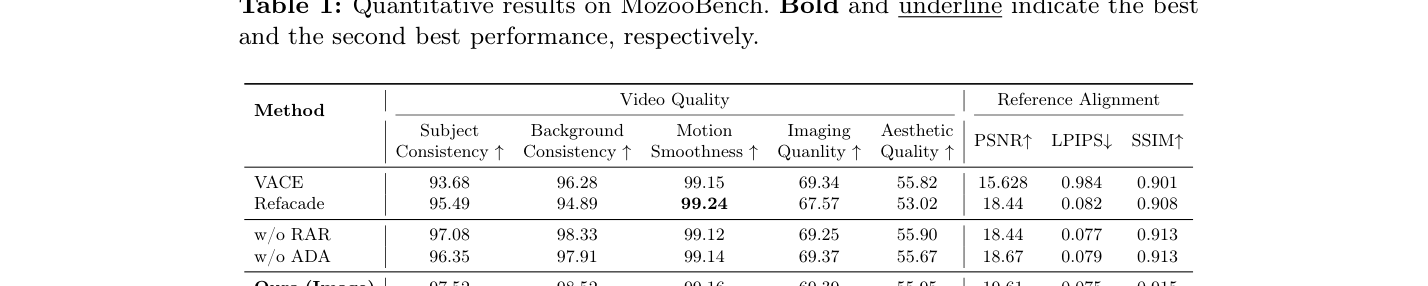
Table 1 — 제안 모델과 기존 방식 간의 주요 성능 지표 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점)
- MoZoo는 복잡한 물리 시뮬레이션 단계를 비디오 확산 프레임워크 내의 단일 생성 프로세스로 대체하여 애니메이션 제작 효율을 획기적으로 향상시켰습니다.
- 제안된 두 가지 핵심 모듈인 RAR-RoPE와 ADA는 다중 참조 데이터 간의 간섭을 최소화하고 구조적 정렬을 유지하는 데 핵심적인 역할을 수행합니다.
- 향후 이 연구는 고품질 캐릭터 디자인 및 가상 세계 구축을 자동화하는 핵심 기술로서 영화, 게임 등 창의적 미디어 산업에 큰 파급력을 미칠 것으로 기대되며, 나아가 인체 시뮬레이션으로의 확장을 예고하고 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] 4D Human-Scene Reconstruction from Low-Overlap Captures
- [논문리뷰] ActWorld: From Explorable to Interactive World Model via Action-Aware Memory
- [논문리뷰] Echo-Memory: A Controlled Study of Memory in Action World Models
- [논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
- [논문리뷰] LongLive-RAG: A General Retrieval-Augmented Framework for Long Video Generation
Review 의 다른글
- 이전글 [논문리뷰] LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
- 현재글 : [논문리뷰] MoZoo:Unleashing Video Diffusion power in animal fur and muscle simulation
- 다음글 [논문리뷰] Native Audio-Visual Alignment for Generation
댓글