[논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hidir Yesiltepe, Jiazhen Hu, Tuna Han Salih Meral, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLA (Multi-Head Latent Attention): per-head KV 캐시를 공유되는 저차원(low-rank) 콘텐츠 잠재 표현과 분리된 위치 정보를 담은 키로 대체하여 메모리 사용량을 획기적으로 줄이는 기법입니다.
- KV Cache: autoregressive 추론 시 이전 토큰들의 Key와 Value 상태를 저장하는 메모리 버퍼로, 영상 생성 모델의 streaming 성능 및 메모리 효율을 결정짓는 핵심 요소입니다.
- 3D-RoPE (3D Rotary Positional Embedding): 영상의 시간, 높이, 너비 축을 고려하여 위치 정보를 인코딩하는 방식이며, VideoMLA에서는 head-shared 형태로 분리되어 적용됩니다.
- Causal Forcing: bidirectional teacher 모델을 autoregressive student 모델로 증류(distillation)하여 streaming 영상 생성을 가능하게 하는 학습 파이프라인입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 autoregressive 영상 확산 모델에서 streaming 생성 시 발생하는 방대한 KV 캐시 메모리 비용 문제를 해결하고자 합니다. 기존 연구들은 sliding-window 내에서 토큰의 재배치나 압축에 집중했으나, 근본적인 per-token, per-layer KV 레이아웃은 그대로 유지하여 메모리 제약이 여전히 존재합니다 [Figure 1]. 저자들은 기존의 dense한 per-head KV 캐시 구조를 저차원 잠재 공간으로 대체함으로써, 영상 생성 품질을 유지하면서도 모델의 운영 효율성을 최적화해야 할 필요성을 제기합니다.
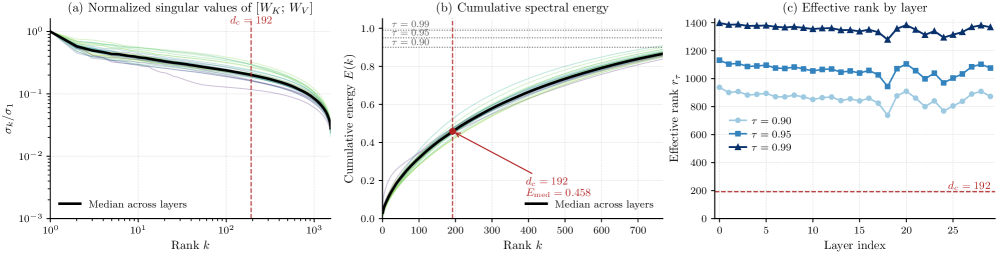
Figure 1 — 영상 attention의 비저차원성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VideoMLA를 제안하여 per-token KV 메모리를 92.7%까지 절감하며, 영상 확산 모델에 최적화된 MLA 아키텍처를 도입합니다 [Figure 3]. 제안하는 방식은 공유되는 저차원 콘텐츠 잠재 표현($c_{t}^{KV}$)과 head-shared decoupled 3D-RoPE 키를 사용하여 매 layer마다 dense한 정보를 재구성하는 구조입니다 [Figure 3]. 실험 결과, VideoMLA는 VBench 평가에서 60초 긴 호흡(long-horizon) 영상 생성 시 가장 높은 전체 점수(0.859)를 기록하며 기존 streaming baselines를 상회했습니다 [Table 2]. 특히, 단일 B200 GPU 환경에서 기존 모델 대비 1.23배의 처리량(throughput) 향상을 달성하며 추론 효율성을 입증했습니다 [Table 3]. 또한, 분석 결과 MLA의 성능이 사전 학습된 attention의 낮은 rank 때문이 아니라, 학습 과정에서 결정된 architectural bottleneck의 rank budget을 최적으로 활용하기 때문임을 확인했습니다 [Figure 2, Figure 8].
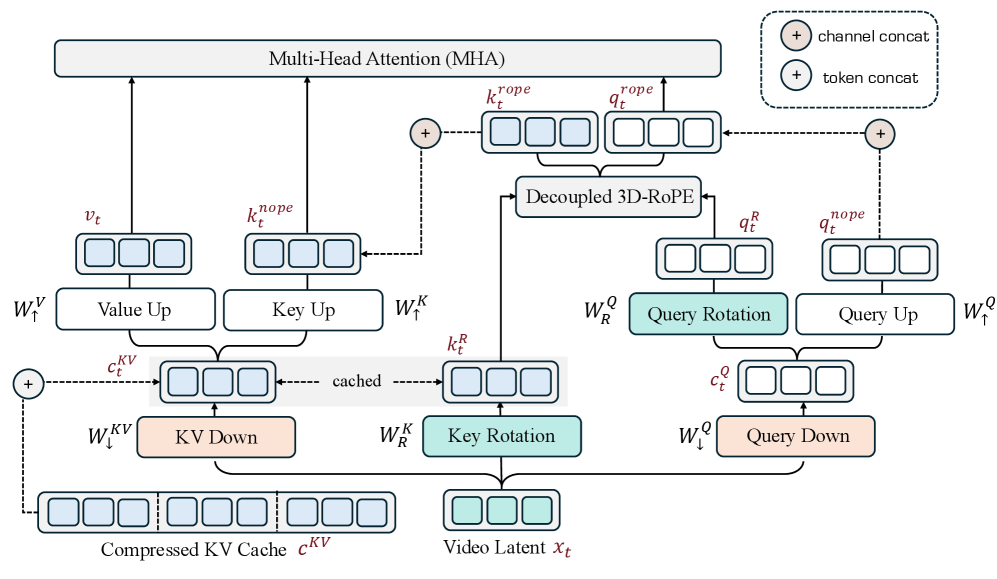
Figure 3 — VideoMLA 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 영상 확산 모델에서 처음으로 MLA 기반의 latent KV 캐싱 기법을 적용하여 메모리 효율성과 긴 영상 생성 품질이라는 두 마리 토끼를 잡았습니다. VideoMLA는 기존 모델들과 동일한 학습 파이프라인을 유지하면서도 KV 캐시 footprint를 극적으로 줄여, 더 긴 영상 생성과 더 큰 batch 처리를 가능하게 했습니다. 이 연구는 고화질 streaming 영상 생성 기술이 산업계 및 연구계에서 대규모로 배포되는 데 있어 중요한 메모리 효율성 가이드라인을 제시합니다.
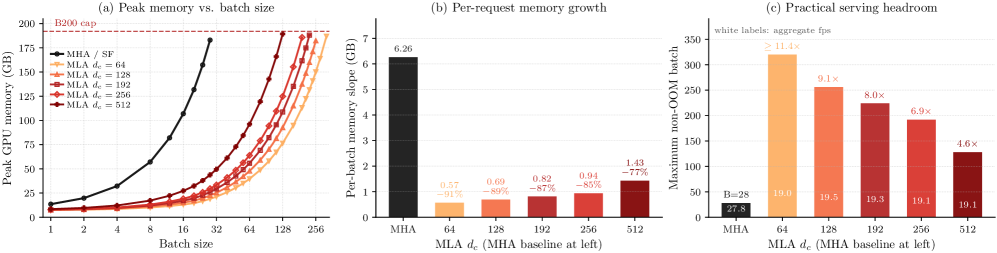
Figure 7 — 메모리 절감 및 배치 효율
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Smarter and Cheaper at Once: Byte-Exact KV-Cache Grafting Turns a Frozen Small Model into a Verified-Knowledge Flywheel
- [논문리뷰] 4D Human-Scene Reconstruction from Low-Overlap Captures
- [논문리뷰] Vidu S1: A Real-Time Interactive Video Generation Model
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
Review 의 다른글
- 이전글 [논문리뷰] VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
- 현재글 : [논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
- 다음글 [논문리뷰] When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
댓글