[논문리뷰] When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yifan Zeng, Yiran Wu, Yaolun Zhang, Wentian Zhao, Kun Wan, Qingyun Wu, Huazheng Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-Agent RL (MARL): 다수의 에이전트가 특정 워크플로우 내에서 역할을 나누어 상호작용하며 강화학습을 통해 공동으로 성능을 최적화하는 방식입니다.
- Isolated-Policy (IP): 각 역할(Role)마다 독립적인 파라미터를 갖는 별도의 Policy를 할당하여 학습하는 전략입니다.
- Shared-Policy (SP): 워크플로우 내 모든 역할이 단일 Policy를 공유하여 업데이트하는 전략으로, 파라미터 효율성을 극대화합니다.
- Gradient_amplification: 동일한 역할을 수행하는 다수의 에이전트가 공유하는 Policy를 업데이트할 때 발생하는 현상으로, 동일한 방향의 그래디언트가 증폭되어 특정 역할의 Policy가 빠르게 변질되는 현상입니다.
- Sp_role_capture: Shared-Policy 환경에서 특정 역할이 더 많은 그래디언트 기여도를 가질 때, 공용 Policy가 해당 역할의 성향으로만 편향되는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다중 에이전트 LLM 워크플로우의 end-to-end 강화학습 시 발생하는 성능 불안정성과 그 원인을 체계적으로 규명하는 것을 목표로 합니다. 기존 연구들은 개별 워크플로우에 특화된 알고리즘을 제안하는 데 그쳤으며, 왜 특정 환경에서 학습이 성공하거나 실패하는지에 대한 근본적인 메커니즘을 설명하지 못했습니다 [Figure 1]. 저자들은 이러한 한계를 극복하기 위해 워크플로우(Eval-Opt, Voting, Orch-Workers), 모델 규모(0.6B, 1.7B, 4B), 작업(Math, Code), 정책 공유 전략(IP vs SP)의 조합을 통한 대규모 통제 실험을 수행하였습니다.
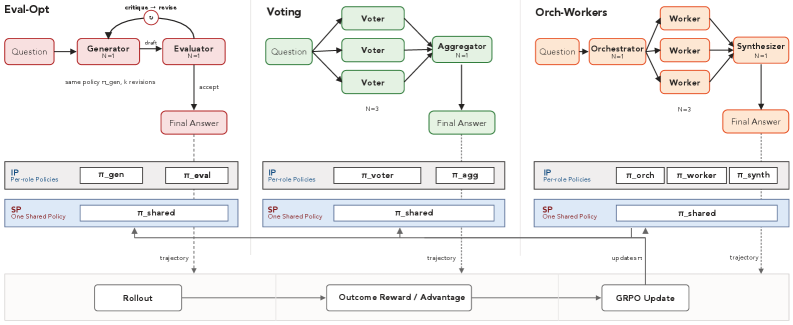
Figure 1 — 워크플로우 및 정책 공유 전략 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 세 가지 주요 워크플로우와 두 가지 Policy-Sharing 전략을 바탕으로 대조 실험을 진행하였습니다 [Figure 1]. Isolated-Policy(IP)는 대체로 더 높은 최고 성능(Ceiling)을 기록하지만, 특정 학습 단계 이후 성능이 급락하는 'terminal accuracy cliff' 현상이 잦았습니다. 반면, Shared-Policy(SP)는 학습 초기에는 안정적이나 최고 성능은 IP보다 낮은 경향을 보였습니다 [Table 1], [Figure 3]. 실험 결과, 다중 에이전트 RL은 대부분의 경우 기본 모델(Base Model) 대비 성능 개선을 보였으나, 그 정도는 워크플로우와 작업의 상호작용에 따라 결정되었습니다 [Figure 2]. 특히 IP에서는 gradient_amplification 현상이 발생하여 동일 역할 에이전트들이 잘못된 답변으로 수렴하는 경향이 관찰되었고, SP에서는 sp_role_capture로 인해 정책이 지배적인 역할에 편향되는 모습이 확인되었습니다 [Table 2], [Figure 6].
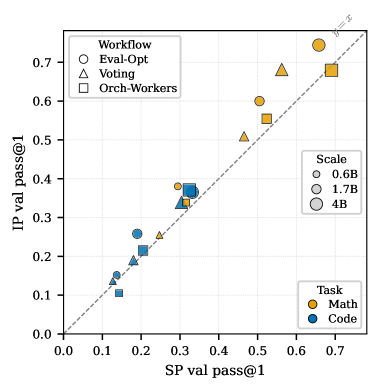
Figure 3 — IP와 SP 성능 비교
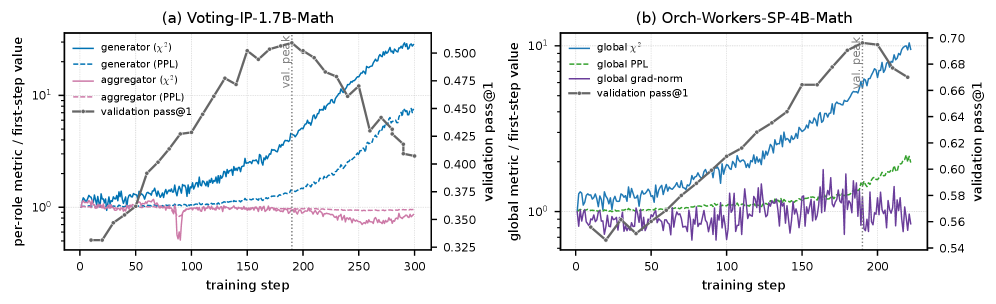
Figure 6 — 학습 실패(Cliff) 구간의 동역학
4. Conclusion & Impact (결론 및 시사점)
본 연구는 다중 에이전트 LLM 시스템의 강화학습 성능이 정책 공유 방식과 워크플로우 구조에 따른 '학습 압력의 전달 채널'에 의해 결정됨을 입증하였습니다. 이 결과는 단순히 정책 공유 여부가 안정성을 보장하는 것이 아니라, 설계 단계에서부터 워크플로우의 특성에 맞춰 Policy를 독립적으로 분리할지 혹은 공유할지를 신중히 결정해야 함을 시사합니다. 본 논문에서 제시한 Gradient Dynamics 기반의 분석 프레임워크는 향후 에이전트 기반 AI 시스템의 설계 및 최적화 과정에서 발생하는 비정상적 성능 저하를 모니터링하고 예방하는 핵심 지표로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Multi-Agent Tool-Integrated Policy Optimization
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
Review 의 다른글
- 이전글 [논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
- 현재글 : [논문리뷰] When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
- 다음글 [논문리뷰] Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
댓글