[논문리뷰] Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Liyang Li, Muzhi Zhu, Zhiyue Zhao, Hengyu Zhao, Ke Liu, Linhao Zhong, Hao Chen, Chunhua Shen
1. Key Terms & Definitions (핵심 용어 및 정의)
- TVR (Target Viewpoint Reproduction): 에이전트가 주어진 Target image와 일치하는 시점(Viewpoint)을 찾을 때까지 3D 환경 내에서 능동적으로 이동 및 회전하는 폐루프(Closed-loop) 작업입니다.
- TVRBench: 실내 시뮬레이션 환경에서 에이전트의 공간 지능을 평가하기 위한 벤치마크로, 장면 규모와 시각적 정보량에 따라 난이도를 구분하여 탐색 효율성과 공간 메모리를 측정합니다.
- VA (Visual-Action) Memory: 에이전트가 이전의 전체 관측치와 수행한 행동 시퀀스를 다중 모달 컨텍스트로 유지하는 메모리 방식입니다.
- AO (Action-Only) Memory: 에이전트가 현재의 관측치, 목표 이미지, 그리고 이전 행동들에 대한 간략한 요약 정보만을 활용하는 메모리 방식입니다.
- GRPO (Group Relative Policy Optimisation): 보상(Reward)을 기반으로 에이전트의 정책을 최적화하는 강화학습 기법으로, 본 논문에서는 단일 단계(Single-turn)와 궤적 단위의 다중 단계(Multi-turn) 방식으로 구분하여 적용되었습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Foundation Models가 수동적인 시각적 이해를 넘어, 능동적인 탐색을 통해 3D 공간에서 목표 시점을 정확히 재현할 수 있는지 질문합니다 [Figure 1]. 기존 연구들은 주로 사전에 수집된 데이터에 의존하여 "무엇이 어디에 있는가"를 묻는 정적인 공간 지능에 집중해 왔습니다. 그러나 실제 환경에서의 공간 지능은 스스로 움직이며 시각적 증거를 수집하고, 목표 시점에 도달하기 위해 실시간으로 행동을 수정하는 능동적 과정이 필수적입니다. 저자들은 기존 모델들이 이러한 능동적 제어 능력이 부족하여 단순한 회전이나 반복적인 배회에 그치는 한계가 있음을 지적합니다.
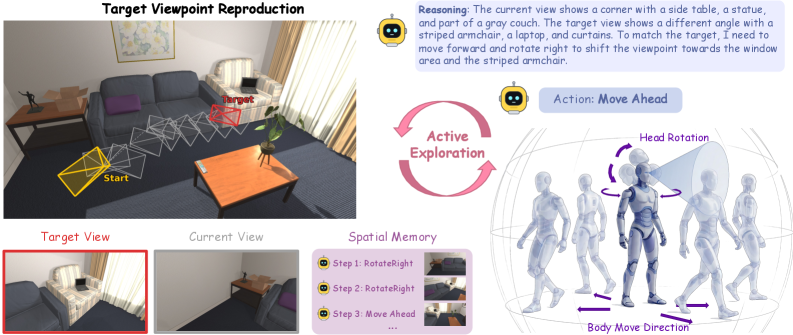
Figure 1 — TVR 작업 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 능동적 공간 탐색 능력을 향상시키기 위해 Expert-trajectory SFT, CoT-SFT, Single-turn GRPO, 그리고 실시간 시뮬레이터 롤아웃을 기반으로 한 Multi-turn GRPO를 포함하는 통합 Post-training 프레임워크를 제안합니다 [Figure 4]. 실험 결과, 단순히 시각적 패턴을 인식하는 것보다 공간적 불일치를 실제 신체 이동(Body translation)으로 매핑하는 것이 가장 큰 병목 현상임을 확인하였습니다 [Figure 3]. Visual-action SFT를 통해 Qwen3.5-9B 모델의 성공률을 2.8%에서 50.8%로 크게 향상시켰으며, Multi-turn GRPO를 추가 적용하여 복잡한 다중 방(Multi-room) 환경에서 51.4%의 최고 성공률을 달성했습니다 [Table 2]. 대조적으로 CoT supervision과 Single-turn GRPO는 오히려 폐루프 성능을 저하시키는 결과를 보였습니다.
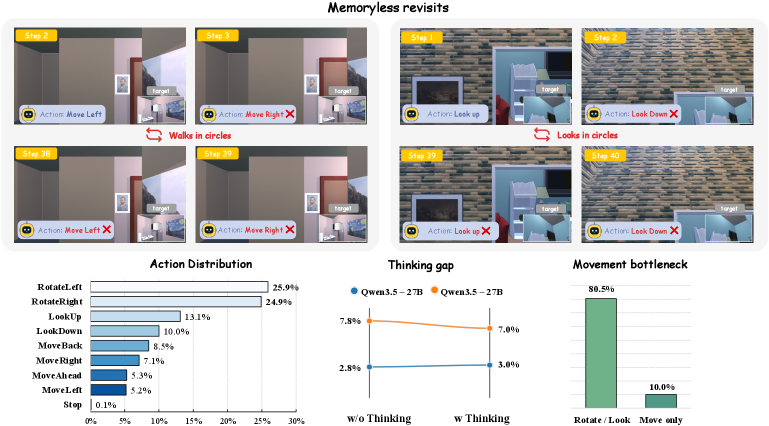
Figure 3 — 모델 실패 패턴 분석
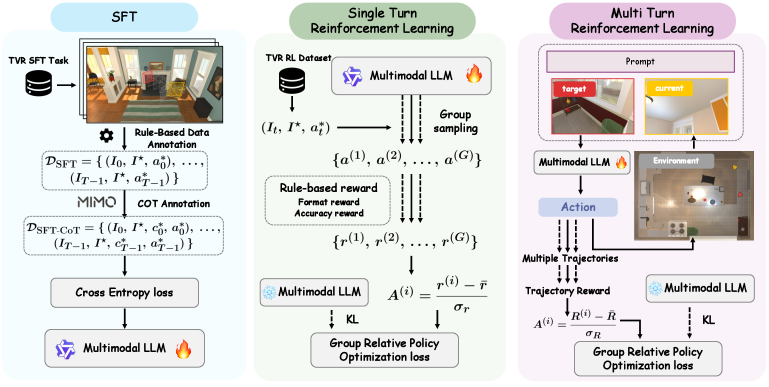
Figure 4 — Post-training 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 능동적 시점 재현이라는 새로운 태스크인 TVR과 이를 평가하는 TVRBench를 통해 Foundation Models의 공간 지능을 측정하는 표준을 제시합니다. 연구 결과는 단순히 모델의 규모를 키우는 것보다, 능동적인 다단계 제어 구조에 최적화된 Post-training 전략이 훨씬 효과적임을 입증했습니다. 이러한 발견은 향후 Embodied AI 에이전트가 실제 물리 환경에서 더 효율적으로 탐색하고 임무를 수행하도록 설계하는 데 중요한 기초가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
- [논문리뷰] Audio-Visual Intelligence in Large Foundation Models
- [논문리뷰] ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
- [논문리뷰] NitroGen: An Open Foundation Model for Generalist Gaming Agents
- [논문리뷰] DiRL: An Efficient Post-Training Framework for Diffusion Language Models
Review 의 다른글
- 이전글 [논문리뷰] When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
- 현재글 : [논문리뷰] Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
- 다음글 [논문리뷰] Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
댓글