[논문리뷰] Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haozhan Shen, Tiancheng Zhao, Kangjia Zhao, Jianwei Yin
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLM (Vision-Language Models): 언어 감독(Language supervision)을 통해 시각적 관측값과 의미적 개념을 정렬하는 모델로, 객체 인식과 범주 이해에 특화됨.
- VGM (Video Generation Models): 시간적으로 변화하는 시각적 세계를 학습하여 동역학 및 기하학적 일관성에 대한 사전 지식을 획득하는 모델.
- Frozen-Feature Probing: 기초 모델을 미세 조정(Fine-tuning)하지 않고, 모델을 고정한 상태에서 중간 레이어의 특징(Features)만을 추출하여 가벼운 프로브(Lightweight probe)로 분석하는 방법론.
- Spatial Intelligence: 로봇 공학이나 자율 주행 등에서 요구되는 능력으로, 물리적 세계의 의미적 객체 인식과 기하학적 구조 이해를 통합적으로 수행하는 역량.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Spatial Intelligence를 구축하는 데 있어 VLM과 VGM 중 어느 사전 학습(Pre-training) 패러다임이 더 우수한 표현 체계(Representation substrate)를 제공하는지 분석한다 [Figure 1]. 기존 연구들은 로봇 제어 정책이나 대규모 모델을 전체적으로 fine-tuning하여 평가했기 때문에, 행동 디코더나 데이터 혼합 등 부수적인 요인으로 인해 사전 학습 패러다임 자체의 기여도를 분리하기 어렵다는 한계가 있다. 저자들은 이러한 제약을 극복하고, 사전 학습된 모델의 고정된 표현(Frozen representations) 속에 내재된 공간적 정보의 접근성을 객관적으로 측정하고자 한다.
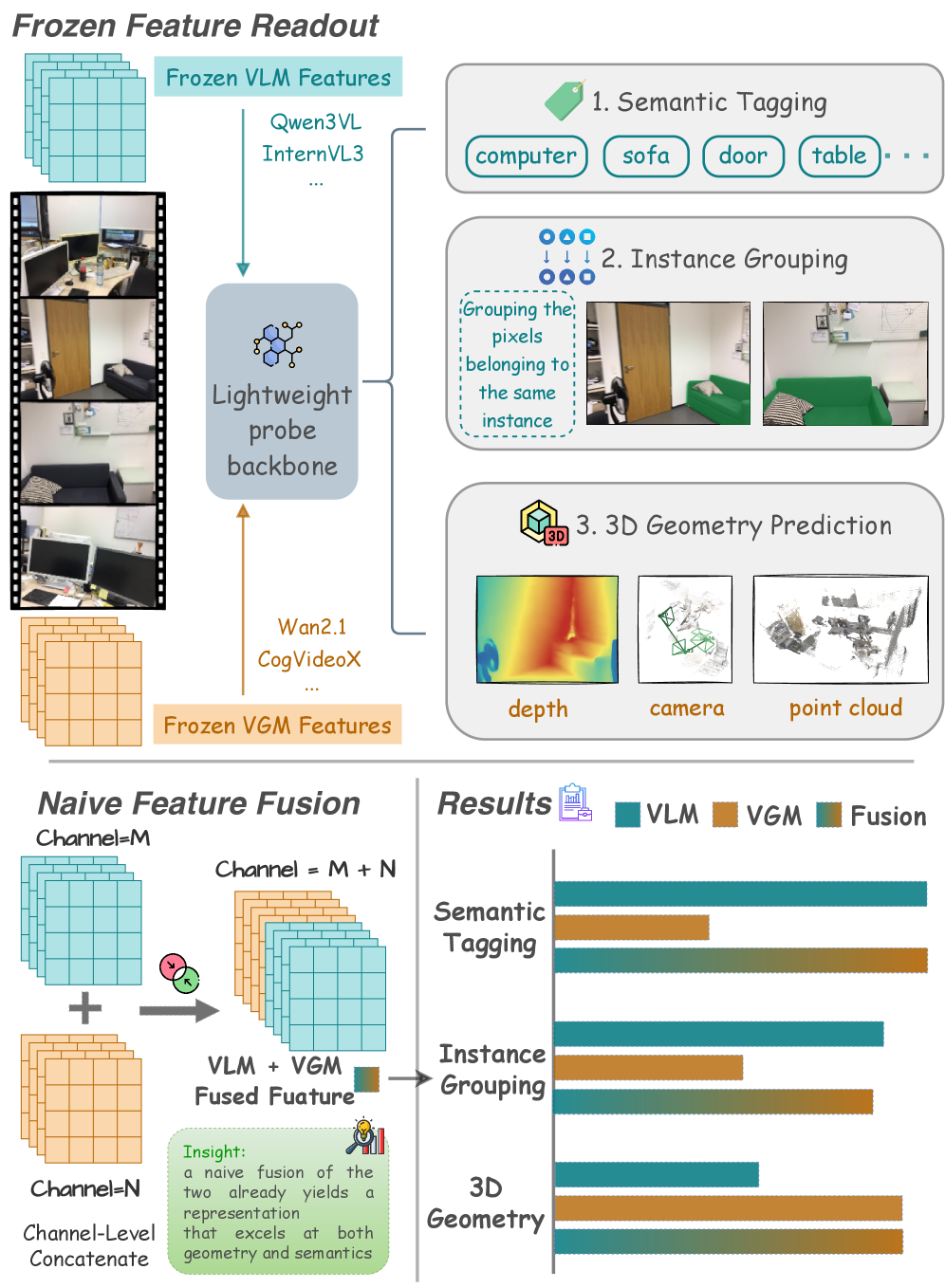
Figure 1 — VLM과 VGM 프로빙 개요 및 상호보완성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Semantic Tagging, Instance Grouping, 3D Geometry Prediction의 세 가지 핵심 축을 중심으로 VLM과 VGM을 체계적으로 비교하는 프로빙 프레임워크를 제안한다 [Figure 2]. 연구 결과, VLM은 의미적 범주 인식과 객체 인스턴스 그룹화에서 압도적인 성능을 보였으며, VGM은 밀집 기하학(Dense geometry) 및 카메라 움직임 예측에서 상대적 우위를 점하는 명확한 상호보완적 관계가 확인되었다 [Table 1]. 예를 들어, Semantic Tagging에서 VLM은 평균 mAP 92.08%를 기록하여 VGM(69.89%) 대비 우수한 객체 범주 보존 능력을 입증했다. 또한, 3D Geometry 지표인 AbsRel에서 VGM은 낮은 오차를 보이며 기하학적 구조 복원에 더 강한 신호를 제공함이 드러났다. 흥미롭게도, 두 모델의 정규화된 특징을 단순 융합(Feature-level fusion)했을 때, 의미론적 강점과 기하학적 강점이 결합되어 단일 모델 대비 향상된 성능을 도출했다 [Table 2].
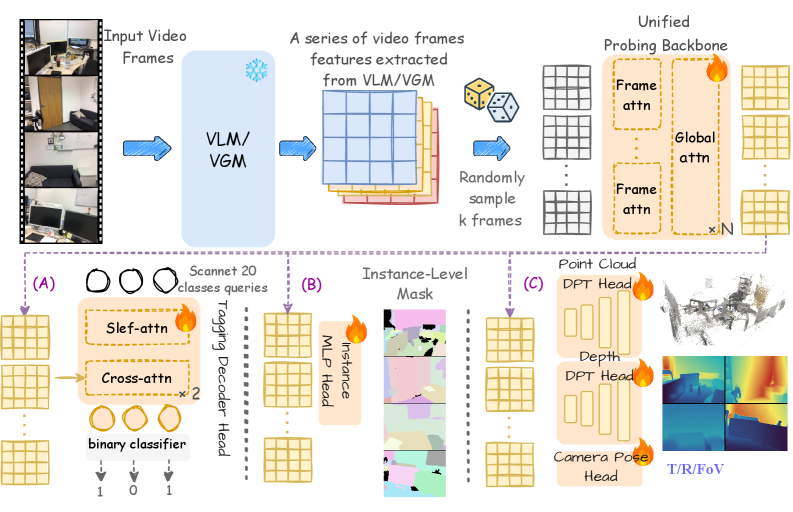
Figure 2 — 공통 프로빙 프레임워크 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLM과 VGM이 각각 의미적 정보와 기하학적 정보를 서로 다른 수준으로 인코딩하고 있음을 입증하며, 두 패러다임의 상호보완성을 실험적으로 규명했다. 이러한 발견은 차세대 Spatial Intelligence를 위한 백본 모델 개발 시, 언어 정렬 기반의 객체 표현과 생성 학습 기반의 기하학적 표현을 통합하는 새로운 아키텍처 방향성을 제시한다. 이는 향후 Embodied AI 시스템이 더욱 정밀한 물리적 상호작용과 환경 이해를 수행할 수 있도록 기술적 가이드라인을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
- [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
- [논문리뷰] EmboAlign: Aligning Video Generation with Compositional Constraints for Zero-Shot Manipulation
- [논문리뷰] Stepping VLMs onto the Court: Benchmarking Spatial Intelligence in Sports
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
Review 의 다른글
- 이전글 [논문리뷰] Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
- 현재글 : [논문리뷰] Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
- 다음글 [논문리뷰] X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
댓글