[논문리뷰] VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junhao Cheng, Liang Hou, Tianxiong Zhong, Xin Tao, Pengfei Wan, Pengfei Wan, Kun Gai, Jing Liao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VGM (Video Generation Models): 시간적 일관성을 유지하며 텍스트 기반의 visual trajectory를 생성하는 핵심 모델입니다.
- VLM-as-Teacher: VLM이 단순히 텍스트 솔루션을 제공하는 'solver' 역할을 넘어, process constraints와 최종 목표 달성 여부를 평가하고 differentiable reward를 생성하는 'teacher'로 기능하는 패러다임입니다.
- Adaptive Test-Time Optimization: 추론 과정 중에 모델 전체를 재학습하는 대신, lightweight LoRA 모듈만을 업데이트하여 인스턴스별 최적화를 수행하는 방식입니다.
- Differentiable Rewards: VLM이 생성한 긍정적 답변(e.g., "Yes")에 대한 log-likelihood를 기반으로 VGM의 생성 과정에 피드백을 전달하는 보상 함수입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 "Reasoning with Video" 패러다임에서 VGM들이 높은 시각적 품질에도 불구하고 논리적 추론이나 특정 규칙 준수에서 시스템적인 한계를 보인다는 문제에 주목합니다 [Figure 1]. 기존 연구들(Baseline)은 Best-of-N 샘플링이나 VLM을 활용한 텍스트 기반의 Plan-as-Solver 방식을 도입했으나, 언어적 프롬프트가 복잡한 시공간적 제약을 모두 포착하지 못하거나, VGM이 고수준의 지시 사항을 정밀한 시각적 결과물로 변환하는 데 실패하는 경우가 잦습니다. 저자들은 이러한 한계를 극복하기 위해, VLM의 뛰어난 시각적 인식 및 평가 능력을 활용하여 추론 과정을 실시간으로 교정하는 새로운 접근 방식이 필요함을 강조합니다.
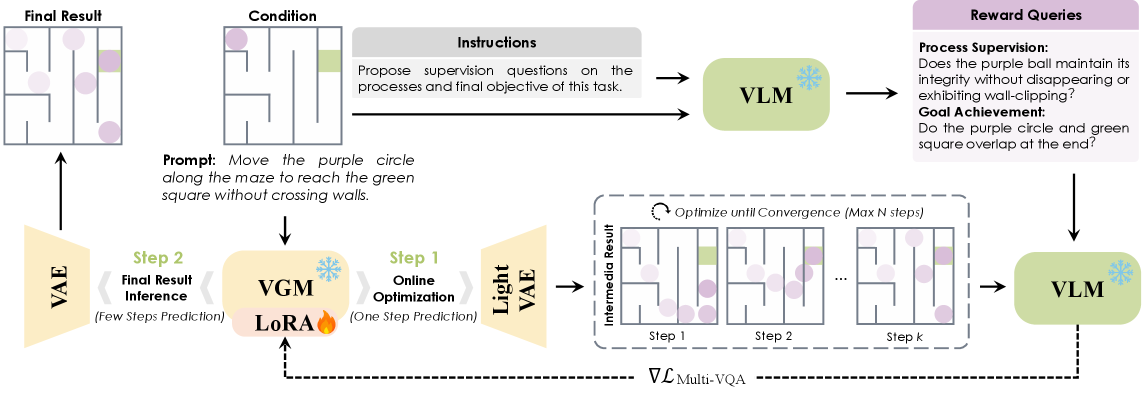
Figure 1 — 제안 모델의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VLM을 'teacher'로 활용하여 task-specific 규칙을 differentiable reward로 변환하고, 이를 통해 inference 시점에 LoRA 모듈을 최적화하는 Adaptive Test-Time Optimization 프레임워크를 제안합니다 [Figure 1]. 이 방법론은 task에 적합한 supervision query를 자동으로 생성하여, 생성된 비디오가 목표 상태에 도달했는지와 process constraints를 만족하는지를 실시간으로 평가합니다 [Figure 2]. 핵심적인 계산 효율성을 위해 lightweight surrogate decoder를 활용하고, 4-step으로 증류된(distilled) VGM 기반에서 첫 번째 단계의 clean-latent prediction을 최적화하는 방식을 도입했습니다. VBVR-Bench와 RULER-Bench 실험 결과, 제안 모델은 평균적으로 16.7점의 성능 향상을 기록하며 기존의 VLM-as-Solver 패러다임(+0.4점) 및 Best-of-N 샘플링(+2.2점) 대비 압도적인 우위를 보였습니다. 특히, 이 모든 과정은 비교 가능한 수준의 Latency(추론 비용) 하에서 이루어짐을 입증하였습니다.

Figure 2 — 정성적 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLM을 비디오 추론의 감독자로 활용하는 새로운 'VLM-as-Teacher' 패러다임을 확립하였습니다. 이 연구는 고정된 VGM의 내재적 한계를 test-time online optimization을 통해 성공적으로 확장할 수 있음을 보여주며, 시각적 생성 모델과 논리적 추론 사이의 간극을 좁히는 유효한 전략을 제시합니다. 이러한 성과는 향후 복잡한 물리적 제약이나 규칙이 존재하는 다양한 영역에서 생성 모델의 활용도를 비약적으로 높일 수 있는 기반이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
- [논문리뷰] RoboEvolve: Co-Evolving Planner-Simulator for Robotic Manipulation with Limited Data
- [논문리뷰] EmboAlign: Aligning Video Generation with Compositional Constraints for Zero-Shot Manipulation
- [논문리뷰] Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
Review 의 다른글
- 이전글 [논문리뷰] Unified Neural Scaling Laws
- 현재글 : [논문리뷰] VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
- 다음글 [논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
댓글