[논문리뷰] Native Audio-Visual Alignment for Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Longbin Ji, Guan Wang, Xuan Wei, Chenye Yang, Xiangrui Liu, Zhenyu Zhang, Shuohuan Wang, Yu Sun, Jingzhou He
1. Key Terms & Definitions (핵심 용어 및 정의)
- NAVA (Native Audio-Visual Alignment): 오디오-비디오 생성 과정에서 외부 문맥(context) 주입과 동기화(synchronization) 구조를 명확히 분리하여, 모델이 이벤트 수준의 대응 관계를 직접 학습하도록 설계된 프레임워크입니다.
- Align-then-Fuse MMDiT: 오디오-비디오의 이질적인 표현을 초기 레이어에서 정렬(Alignment)한 뒤, 후기 레이어에서 통합(Fusion)하여 공동 노이즈 제거(collaborative denoising)를 수행하는 핵심 아키텍처입니다.
- Timbre-in-Context Conditioning: 특정 음성 구간(speech span)에 참조 음색(reference timbre)을 바인딩하여, 별도의 보조 네트워크 없이도 유연한 다중 화자 생성 및 음색 제어를 가능하게 하는 기술입니다.
- Condition-Factorized CFG (Classifier-Free Guidance): 프롬프트 준수, 오디오-비디오 동기화, 음색 보존이라는 세 가지 목적을 독립적인 가이드 방향으로 분해하여 추론 시 정밀하게 제어하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 오디오-비디오 조인트 생성 모델에서 발생하는 동기화 성능 저하와 모달리티 간 정보 결합 문제를 해결하는 것을 목표로 합니다. 기존의 듀얼 타워(Dual-Tower) 접근 방식은 사후 정렬(posterior alignment)에 의존하여 정밀한 동기화 학습에 한계가 있으며, 반면 완전 통합형(fully unified) 방식은 의미론적 문맥과 저수준 동기화가 동일한 표현 공간에서 충돌하여 모델의 제어 성능을 저해합니다 [Figure 1]. 이러한 문제점들로 인해, 저자들은 오디오-비디오 간의 상호작용을 외부 컨텍스트와 독립된 전용 공간에서 수행함으로써 동기화의 정확도를 높일 새로운 생성 프레임워크인 NAVA를 제안합니다 [Figure 1].
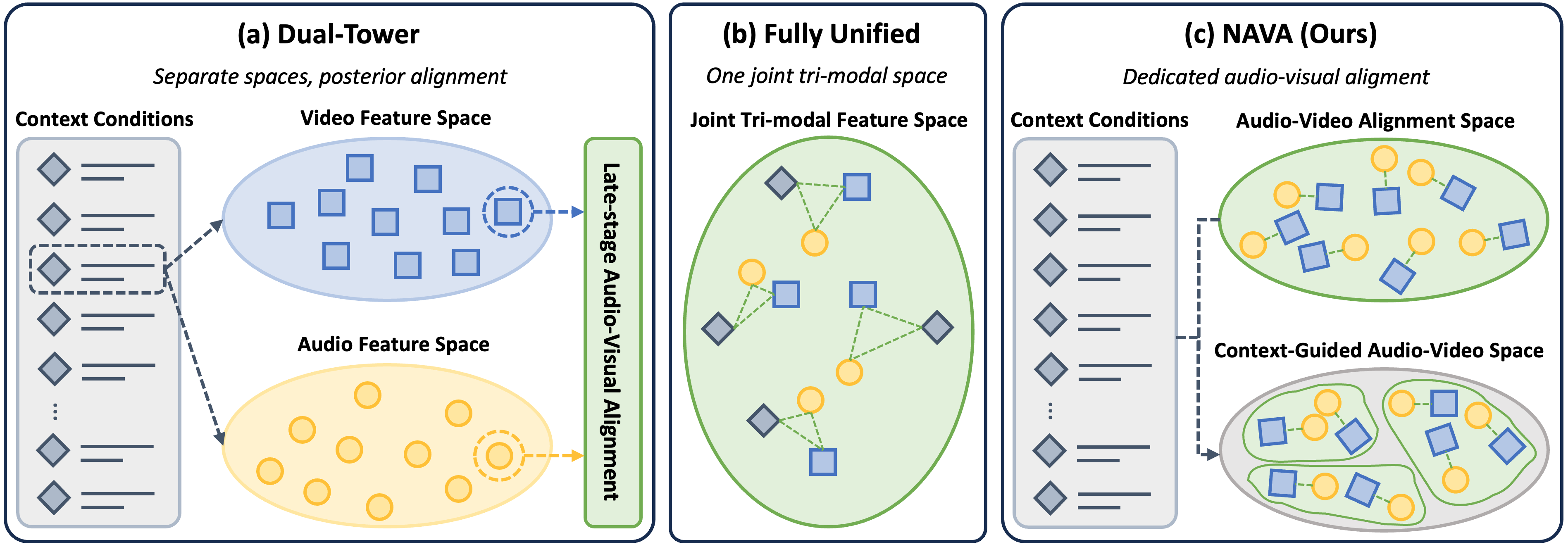
Figure 1 — 오디오-비디오 생성 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 오디오-비디오 생성 시 동기화와 컨텍스트 컨디셔닝을 분리하여 학습하는 NAVA 프레임워크를 제안합니다. 제안된 Align-then-Fuse MMDiT 아키텍처는 초기 Hierarchical Alignment Layers를 통해 이질적인 오디오-비디오 토큰 간의 기본 대응 관계를 구축하고, 이후 Unified Fusion Layers를 통해 공유된 공간에서 효과적인 협력적 노이즈 제거를 수행합니다 [Figure 2]. 특히 Timbre-in-Context Conditioning은 참조 음색을 컨텍스트 내의 특정 구간으로 결합함으로써 사용자 수준의 세밀한 제어를 가능하게 합니다. 정량적 실험 결과, NAVA는 6.3B 파라미터라는 효율적인 규모임에도 불구하고 Verse-Bench에서 Sync-C 7.791을 기록하며 경쟁 모델 대비 가장 우수한 오디오-비디오 동기화 성능을 달성했습니다 [Table 1]. 또한, Seed-TTS 벤치마크에서 음색 유사도(Speaker Similarity) 66.7을 기록하며 기존 오디오-비디오 모델을 크게 상회하는 음색 제어 능력을 입증했습니다 [Table 2]. 아울러 사용자 연구를 통해 다양한 생성 시나리오에서 오디오-비디오 정렬 및 전반적인 품질 측면에서 높은 인간 선호도를 확보했음을 확인했습니다 [Figure 4].
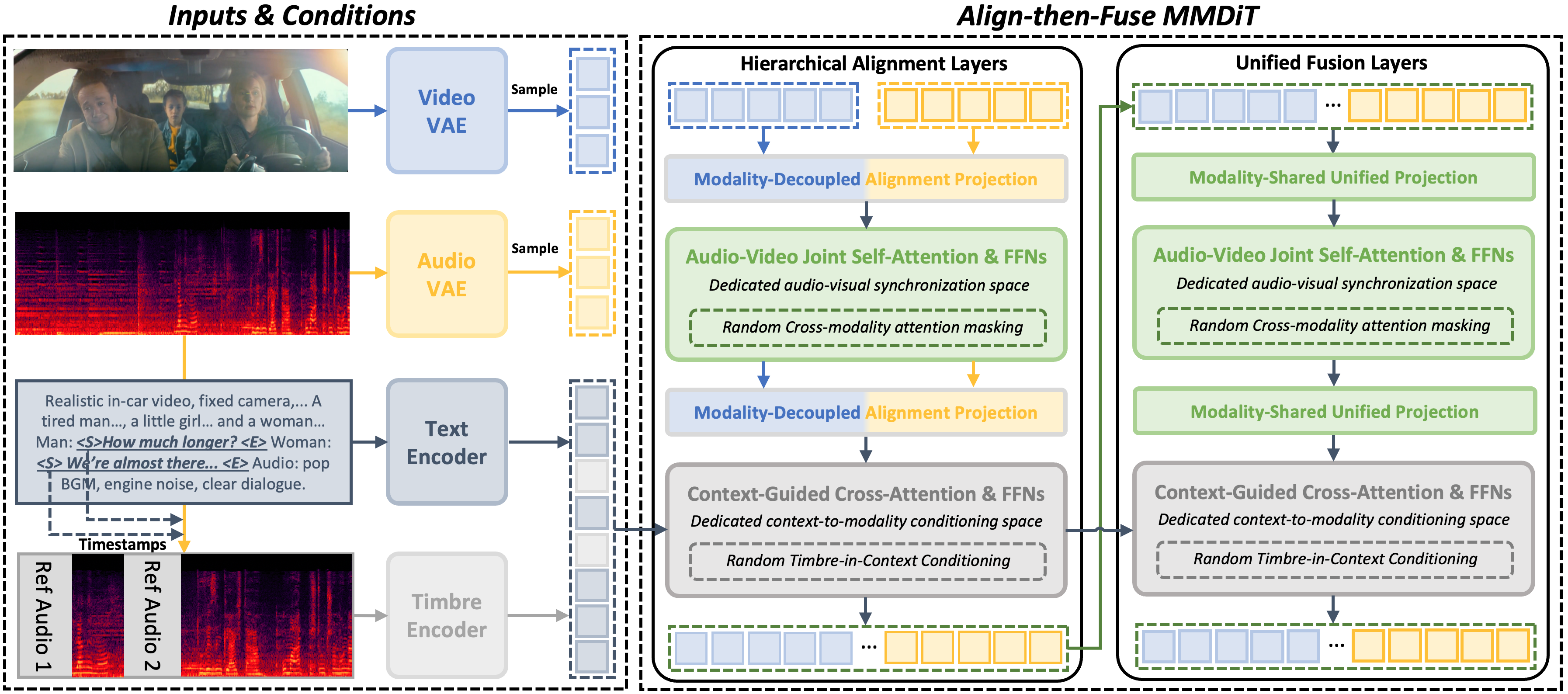
Figure 2 — NAVA 전체 아키텍처
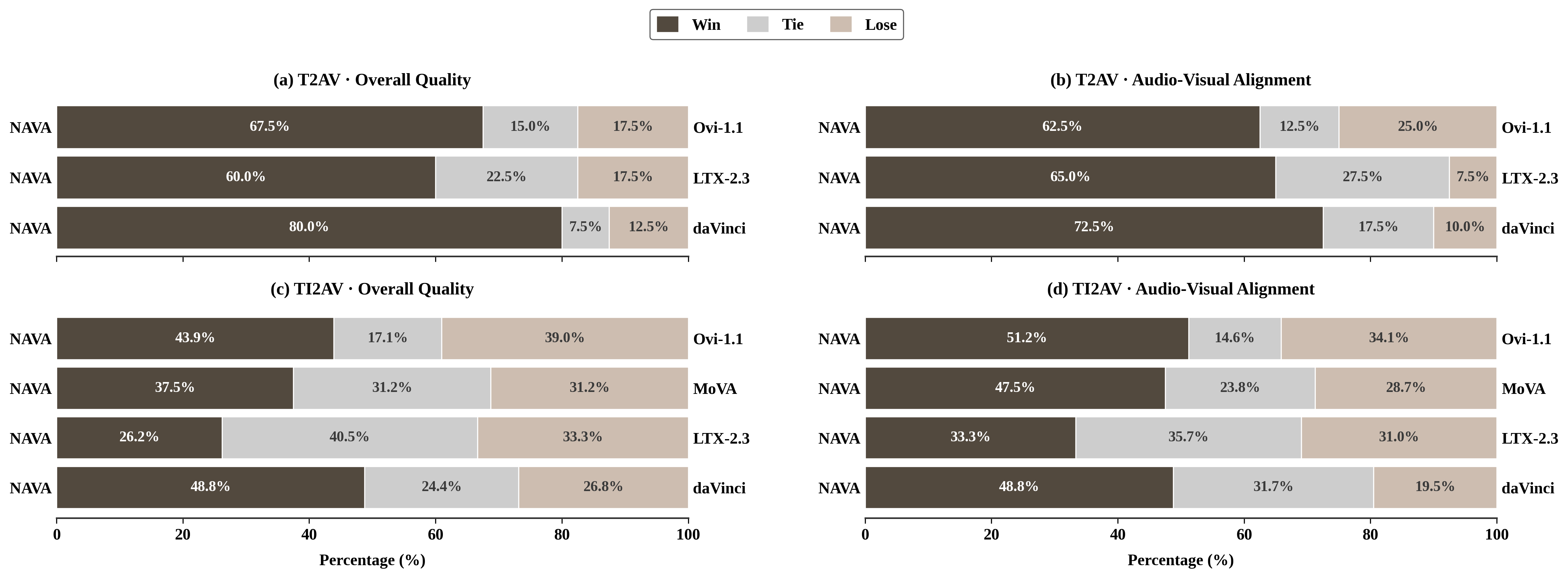
Figure 4 — 사용자 선호도 평가 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 오디오-비디오 생성의 핵심인 정렬과 컨디셔닝의 역할 분리를 통해 더 정확하고 제어 가능한 생성 프레임워크를 구현했습니다. 이 연구는 복잡한 상업적 아키텍처 없이도 높은 수준의 오디오-비디오 동기화를 실현함으로써, 향후 고품질 멀티모달 생성 연구의 오픈 소스 표준을 제시하는 중요한 시사점을 갖습니다. 결과적으로 NAVA는 고해상도 비디오 생성과 정밀한 오디오-비디오 일치성을 동시에 달성해야 하는 창작 도구 및 미디어 콘텐츠 생성 분야에서 핵심적인 역할을 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] UnityShots: Memory-Driven Multi-Shot Audio-Video Generation with Boundary-Aware Gating
- [논문리뷰] LongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
- [논문리뷰] Woosh: A Sound Effects Foundation Model
- [논문리뷰] AVControl: Efficient Framework for Training Audio-Visual Controls
- [논문리뷰] OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
Review 의 다른글
- 이전글 [논문리뷰] MoZoo:Unleashing Video Diffusion power in animal fur and muscle simulation
- 현재글 : [논문리뷰] Native Audio-Visual Alignment for Generation
- 다음글 [논문리뷰] NeuROK: Generative 4D Neural Object Kinematics
댓글