[논문리뷰] OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
링크: 논문 PDF로 바로 열기
저자: Kaihang Pan, Qi Tian, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OmniWeaving : 자유 형식(Free-form)의 Multimodal Composition과 Reasoning-informed Capabilities를 통합하여 다양한 Video Generation 시나리오를 처리하는 제안된 Unified Video Generation 모델입니다.
- Multimodal Composition : 텍스트, 다중 이미지(Multi-image), 비디오 Input을 시간적(Spatio-temporal)으로 Seamless하게 결합하여 일관된 비디오를 생성하는 능력을 의미합니다.
- Reasoning-Augmented Tasks : 모호하거나 추상적인 사용자 Input으로부터 복잡한 의도를 추론하여 Video Generation을 Guided하는 태스크를 지칭합니다.
- IntelligentVBench : Multimodal Composition 및 Abstract Reasoning Capabilities를 엄격하게 평가하기 위해 고안된 최초의 Comprehensive Benchmark Suite입니다.
- MLLM (Multimodal Large Language Model) : OmniWeaving 모델의 핵심 구성 요소로, Multimodal Input에 대한 이해와 Semantic Parsing을 담당합니다.
- MMDiT (Multimodal Diffusion Transformer) : OmniWeaving의 Generative Backbone으로, Conditioned Latents를 Video로 생성하는 Diffusion Model입니다.
- DeepStacking : MLLM의 다양한 Intermediate Layers에서 Hidden States를 추출하여 MMDiT에 Multi-granular Semantic Guidance를 제공하는 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Proprietary Systems인 Seedance-2.0 과 같은 모델들은 Omni-capable Video Generation 분야에서 놀라운 성공을 거두었지만, Open-source 대안들은 그에 비해 상당히 뒤쳐져 있습니다. 현재 대부분의 학술 모델들은 Text-to-Video (T2V), Image-to-Video (I2V), Video-to-Video (V2V) 등 특정 태스크에만 Heavy하게 Fragmented되어 있으며, Task-specific Modules에 의존하여 확장이 어렵고 통합이 방해됩니다. VACE , UniVideo , VINO 와 같은 기존 Open-source Unified Video Generation 노력들은 기본적인 Task Combinations에 초점을 맞추거나 Deep Visual Understanding을 Video Generation에 충분히 활용하지 못하여 Multimodal Composition 및 Reasoning-informed Video Synthesis를 효과적으로 처리하는 데 어려움을 겪고 있습니다.
저자들은 이러한 중대한 Capability Gap을 해결하기 위해 세 가지 핵심 동인을 제시합니다. 첫째, Model Architecture는 Visual Comprehension과 Generation을 단일 Framework로 통합하여 Abstract Reasoning을 명시적으로 활성화해야 합니다. 둘째, Free-form, Multi-task Pretraining으로의 전환이 필수적입니다. 마지막으로, 기존 Benchmark들이 단순한 태스크에 제한되어 있어, Truly "Omni-capable" Video Systems 개발을 촉진할 더 복잡하고 Comprehensive한 Evaluation Suite가 필요합니다. 이에 저자들은 Multimodal Composition과 Abstract Reasoning이 가능한 Omni-level Video Generation Framework인 OmniWeaving 을 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
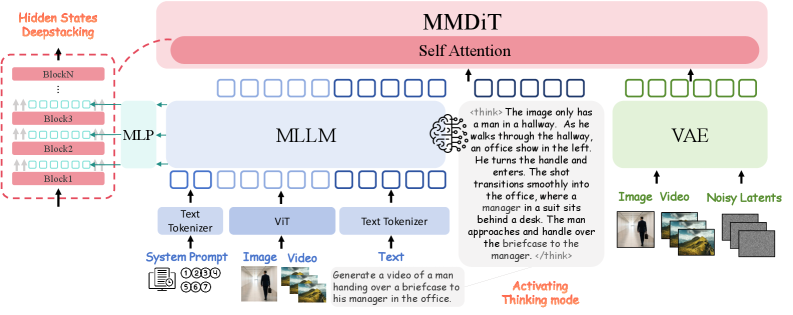
저자들은 Multimodal Comprehension과 Generation을 통합한 Unified Architecture를 기반으로 OmniWeaving 을 제안합니다. 이 모델은 MLLM , MMDiT , VAE 의 세 가지 핵심 구성 요소로 이루어져 있습니다. MLLM 은 자유 형식의 Multimodal Input을 High-level Semantic Space로 Project하고 Hidden States를 MMDiT 로 전달하며, VAE 는 Input Vision을 Low-level Latents로 압축합니다. MMDiT 는 Conditioning Branch를 통해 MLLM Semantic을 Encoding하고 Generative Branch를 통해 Semantically Aligned된 High-fidelity Video를 생성합니다.
모델은 두 가지 주요 개선 사항을 포함합니다:
- Activating Thinking Mode of the MLLM : MLLM 이 Intermediate Reasoning Steps를 생성하여 Semantically Precise하고 Enhanced된 Prompt를 자체적으로 추론하게 함으로써, 추상적인 사용자 의도와 Pixel-level Generation 사이의 Cognitive Gap을 연결합니다.
- Hidden States DeepStacking : MLLM 의 Intermediate Layers (예: 8번째, 16번째, 24번째)에서 Hidden States를 추출하여 Fine-grained Details부터 High-level Abstractions까지 다양한 Semantic Spectrum을 포착하고, 이를 MMDiT 의 Conditioning Branch에 Multi-granular Semantic Guidance로 주입합니다.
훈련은 세 가지 Progressive Stages로 진행됩니다. 첫째, Modality Alignment Training 단계에서는 MLLM 과 MMDiT 간의 정렬을 위해 T2V, I2V와 같은 기본적인 태스크에 대해 MMDiT 와 MLP Connector를 Finetuning하고 MLLM 파라미터는 고정합니다. 둘째, Multi-Task Free-Form Pretraining 단계에서는 Reasoning-Augmented Tasks를 제외한 모든 복잡하고 Heterogeneous Input 태스크를 포함하여 훈련하며, MLLM 파라미터는 여전히 고정됩니다. 셋째, Reasoning-Augmented Fine-Tuning 단계에서는 Reasoning-Augmented Tasks를 도입하고 MLLM 파라미터까지 Unfreeze하여 End-to-end Optimization을 수행합니다. 이 단계에서는 MLLM 의 Reasoning Proficiency를 향상시키기 위해 Next-token-prediction Loss가 추가되어 "Comprehend-then-generate" 패러다임을 확립합니다 [cite: 3, Table 1].
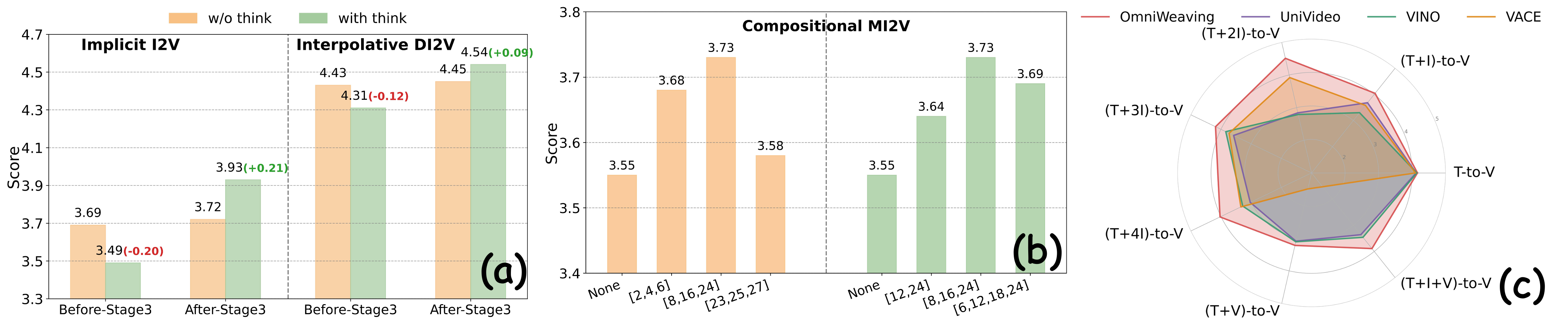
저자들은 또한 Unified Video Generation을 평가하기 위한 새로운 Benchmark인 IntelligentVBench 를 제안합니다. 이 Benchmark는 Implicit I2V, Interpolative DI2V, Compositional MI2V, TIV2V의 네 가지 Distinct Tasks를 포함하며, "VLM-as-a-Judge" (Gemini2.5-Pro) 패러다임을 사용하여 Instruction Following, Condition Preserving, Overall Visual Quality의 세 가지 Metric으로 평가합니다.
OmniWeaving 은 IntelligentVBench 의 모든 네 가지 태스크에서 기존 Open-source Unified Models 중 SoTA 성능 을 일관되게 달성합니다. 특히, MIN 및 AVG Overall Metrics에서 다른 모델들을 능가하며 Synergistic Multi-task Integration을 입증합니다 [cite: 3, 4, Table 3, Table 4]. MLLM 의 "Thinking Mode"를 활성화하면 Implicit I2V 및 Interpolative DI2V 와 같은 Reasoning-related Tasks에서 성능이 크게 향상되어 Comprehension-guided Generation의 효과를 보여줍니다 [cite: 3, Figure 5]. 또한, DeepStacking 메커니즘은 Compositional MI2V 태스크에서 평균 성능을 향상시키는 것으로 나타났으며, Shallow Layer부터 Deep Layer까지 균형 잡힌 Semantic Feature의 통합이 최적의 결과를 가져옴을 시사합니다 [cite: 3, Figure 5]. 기존 Benchmark인 VBench (T2V) 에서는 HunyuanVideo 와 같은 Specialized Models와 비교할 만한 성능을 유지하고, OpenVE-Bench (V2V) 에서는 Unified Counterparts를 능가하는 평균 3.15점 을 기록합니다 [cite: 5, 6, Table 5, Table 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 강력한 Multimodal Composition 및 Reasoning-informed Generation Capabilities를 특징으로 하는 Omni-level Video Generation Model인 OmniWeaving 을 소개합니다. OmniWeaving 은 자유 형식의 Multimodal Interleaved Inputs를 수용하여 조건에 부합하는 비디오를 생성할 수 있으며, Unified Visual Comprehension 및 Generation Framework를 통해 Deep Visual Understanding을 활용하여 Generative Process를 능동적으로 Guided합니다.
나아가, 저자들은 Next-level Intelligent Video Generation을 평가하기 위해 특별히 설계된 Comprehensive Benchmark인 IntelligentVBench 를 제안합니다. 광범위한 실험 결과에 따르면 OmniWeaving 은 기존 Open-source Unified Framework 중에서 SoTA 성능 을 달성하며, 심지어 특정 Specialized Models을 능가하는 결과도 보여주었습니다. 이 연구는 Open-source 커뮤니티에 Unified Video Generation Models의 미래 궤적을 Guided하는 실행 가능한 Reference Point를 제공하는 데 목적이 있습니다. 향후 연구는 Interleaved Multiple-image-and-video Sequences와 같은 더욱 복잡한 Input을 지원하고, Audio Input 및 Output과 같은 Additional Modalities를 통합하여 Fully Omni-modal, Audio-visually Synchronized Video Generation을 달성하는 데 초점을 맞출 것입니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] ShutterMuse: Capture-Time Photography Guidance with MLLMs
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
- [논문리뷰] Towards One-to-Many Temporal Grounding
- [논문리뷰] Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
Review 의 다른글
- 이전글 [논문리뷰] LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis
- 현재글 : [논문리뷰] OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
- 다음글 [논문리뷰] PLDR-LLMs Reason At Self-Organized Criticality
댓글